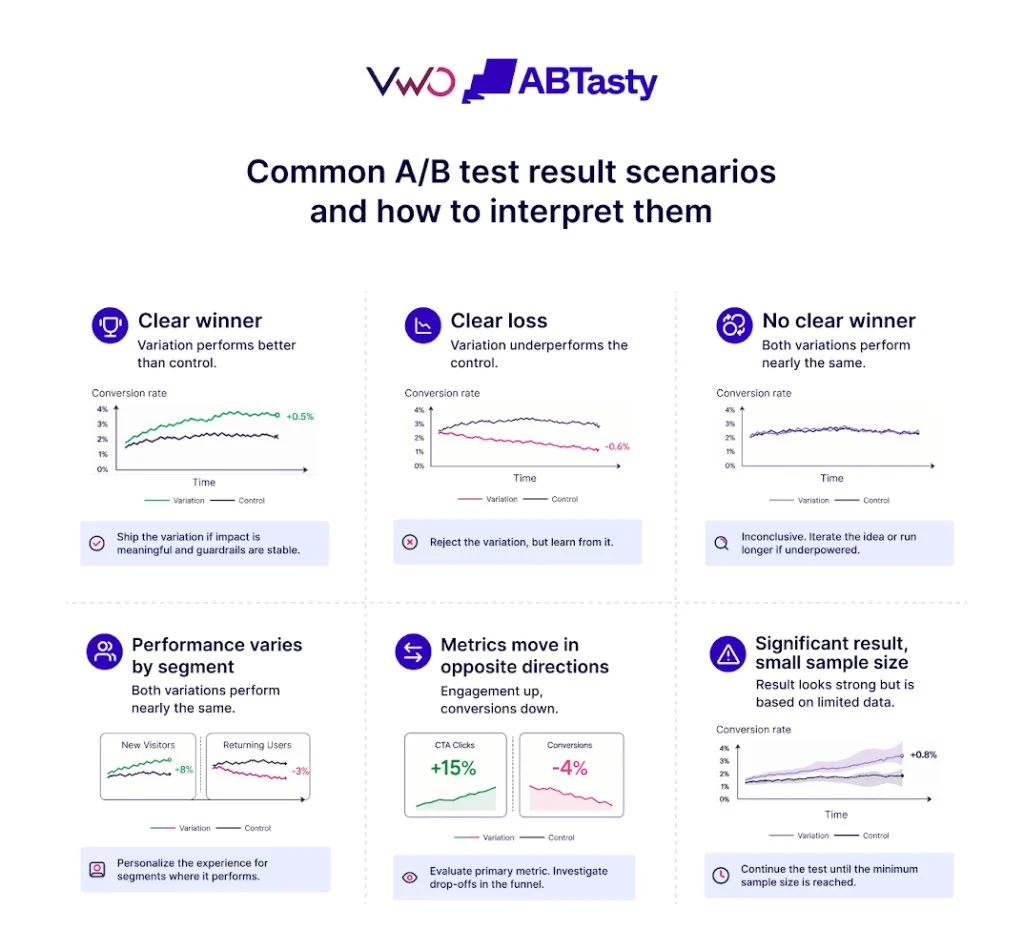
The evolution of digital experimentation often begins with a single, modest victory. A marketing team tests a headline, observes a marginal uptick in conversions, and subsequently applies the same logic to a button color or a product image. Over time, this iterative process transforms into a default decision-making framework: isolate a variable, run a split test, and wait for a statistical winner. While A/B testing remains a cornerstone of data-driven development, industry experts warn that an over-reliance on this specific method has become a primary indicator of low Conversion Rate Optimization (CRO) maturity.
A/B testing is exceptionally effective for answering narrow, binary questions. However, it frequently falters when applied to systemic business challenges such as brand messaging clarity, navigational architecture, or complex pricing strategies. When organizations treat the A/B test as a universal solution, they often overlook the underlying causes of friction, leading to a phenomenon known as "polishing a sinking ship." To achieve sustainable growth, high-maturity teams are moving beyond simple split tests toward a more holistic experimentation ecosystem.
The Cultural Rise of the A/B Default
The ascent of A/B testing as the primary tool for digital product teams is largely attributed to its accessibility. Modern experimentation platforms have democratized data science, allowing marketers and product managers to launch variants without deep expertise in statistics or complex analysis. This convenience has fostered an industry culture where "experimentation" has become synonymous with "A/B testing," regardless of whether the method is appropriate for the problem at hand.
Market data underscores this trend. According to industry surveys, approximately 77% of all digital experiments are simple A/B tests involving only two variants. This preference for simplicity often persists even when multivariate or multi-treatment designs would provide more comprehensive insights. The normalization of this mindset was further accelerated by success stories from "Big Tech" firms. Microsoft’s Bing team, for instance, famously generated over $100 million in additional annual revenue by simply merging two ad title lines into a single headline. Today, Microsoft conducts more than 20,000 controlled experiments annually across its search platform alone, a scale that has prompted many smaller organizations to mimic their methods without possessing their massive traffic volumes.
The Mathematical and Strategic Limitations of Split Testing
Despite its popularity, A/B testing possesses inherent limitations that can lead teams toward false conclusions. One of the most significant hurdles is the requirement for statistical power. To detect a small improvement—such as a 1% or 2% lift—reliably, a site needs hundreds of thousands of visitors per variant. For the vast majority of e-commerce brands, achieving this level of traffic within a reasonable timeframe is impossible.
When traffic is insufficient, teams often fall into three common failure modes:
- Underpowered Tests: Running experiments that lack the volume to distinguish between a real improvement and random statistical noise.
- Excessive Duration: Keeping tests live for 8 to 12 weeks, which slows the pace of innovation and allows external variables (such as seasonal shifts or competitor moves) to contaminate the data.
- The "False Positive" Trap: Declaring a winner based on a temporary spike in data that does not hold up when the change is implemented permanently.
Furthermore, A/B tests are descriptive rather than diagnostic. They reveal what happened—which version "won"—but offer no insight into why it occurred. A variant might win because it genuinely improved the user experience, or it might win because it introduced a sense of urgency that ultimately damaged long-term brand trust. Without qualitative context, teams risk repeating changes they do not fully understand, creating blind spots in their long-term strategy.

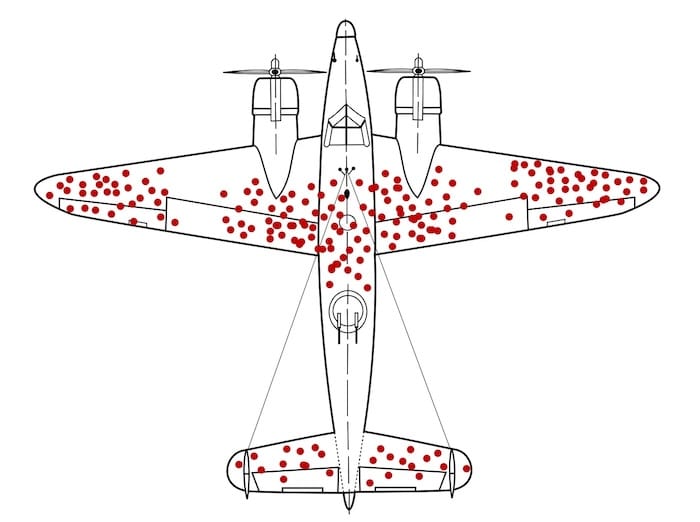
The Survivorship Bias in User Funnels
The limitation of A/B testing is often compared to the World War II phenomenon of survivorship bias. During the war, the military analyzed returning aircraft to determine where to add armor, noting that the fuselage was frequently riddled with bullet holes while the engines remained untouched. Statistician Abraham Wald famously corrected this logic, pointing out that the military only saw the planes that survived. The planes hit in the engine never returned.
A/B testing operates on a similar principle. It captures the behavior of the "survivors"—those who successfully navigated the funnel. It rarely provides data on the "drop-offs"—the users who were so alienated by a confusing navigation menu or a lack of trust that they left the site entirely. By focusing only on the converters, teams may inadvertently reinforce the wrong parts of the experience, optimizing for the "bullet holes" rather than fixing the "engine" failures that cause the most significant losses.
Short-Term Gains vs. Long-Term Business Health
A critical risk of over-testing is the prioritization of immediate session-based metrics over long-term business outcomes. Most A/B tests measure clicks, add-to-cart rates, or immediate purchases. However, these metrics can clash with more vital indicators such as Customer Lifetime Value (CLV), return rates, and overall profitability.
For example, a promotional "spin-to-win" wheel might significantly increase the conversion rate for first-time visitors. However, if those customers are primarily bargain hunters who never return or if the discount erodes the brand’s perceived value, the "winning" test actually harms the business in the long run. High-maturity organizations recognize that an uplift today is meaningless if it compromises repeat purchase rates or increases the volume of support tickets.
The Toolkit of High-Maturity Experimentation Teams
To transcend the limitations of simple split testing, sophisticated organizations utilize a broader range of experimental designs. They match the tool to the specific business question rather than forcing every problem into an A/B framework.
- Sequential Testing: Used for monitoring results in real-time to allow for earlier decision-making when an effect is large, reducing the time wasted on underpowered tests.
- Holdout Groups: A small percentage of users is kept away from a new feature or change for an extended period (months or even a year). This allows the company to measure the long-term impact on retention and CLV that a standard two-week test would miss.
- Switchback Tests: Common in marketplaces or logistics, these tests alternate treatments over time across an entire system rather than splitting users. This prevents "interference" where one user’s experience affects another’s.
- Quasi-Experiments: Used when a clean split is impossible, such as testing the impact of a new pricing model across different geographic regions.
Grounding Hypotheses in User Research
A primary reason many experimentation programs fail to produce meaningful wins is the lack of a rigorous hypothesis-generation process. If a test is based on a random suggestion or an internal opinion, it is essentially a coin toss. High-maturity teams mitigate this by grounding every test in multi-source evidence.
Before a test is even designed, these teams aggregate data from session recordings, customer support logs, post-purchase surveys, and heatmaps. A robust hypothesis follows a strict logical structure: "Because [Evidence from Research], we believe [Specific User Problem], so we will [Specific Change], and we expect [Metric Improvement]."
For instance, rather than "testing a new checkout layout," a high-maturity hypothesis would be: "Because support tickets show users are confused about delivery dates, we believe uncertainty is causing checkout abandonment. We will display estimated arrival dates on the product page. We expect the checkout completion rate to increase and delivery-related inquiries to decrease."

Strategic Impact and Business Alignment
Ultimately, the goal of a mature experimentation program is to move "big levers" rather than making cosmetic tweaks. While button colors and font sizes are easy to change, they rarely alter the trajectory of a company’s revenue. Instead, high-maturity teams focus on core value propositions, pricing psychology, and the information architecture that helps users compare products.
Data analysis reveals a significant disconnect in how many teams choose their goals. Over 90% of experiments focus on just five metrics: clicks, revenue, checkout, registration, and add-to-cart. Interestingly, while "revenue" is the most common goal, it often has a lower "expected impact" than metrics related to navigation or product engagement. By focusing on how users find and evaluate products—rather than just the final click—teams can uncover more significant opportunities for growth.
As the digital landscape becomes increasingly competitive, the ability to run sophisticated experiments will distinguish market leaders from those merely following a checklist. Moving beyond the "A/B testing default" requires a cultural shift toward research, a willingness to measure long-term health over short-term spikes, and a commitment to understanding the "why" behind user behavior. For organizations looking to scale, the path forward involves less "guessing and testing" and more disciplined, evidence-based experimentation.