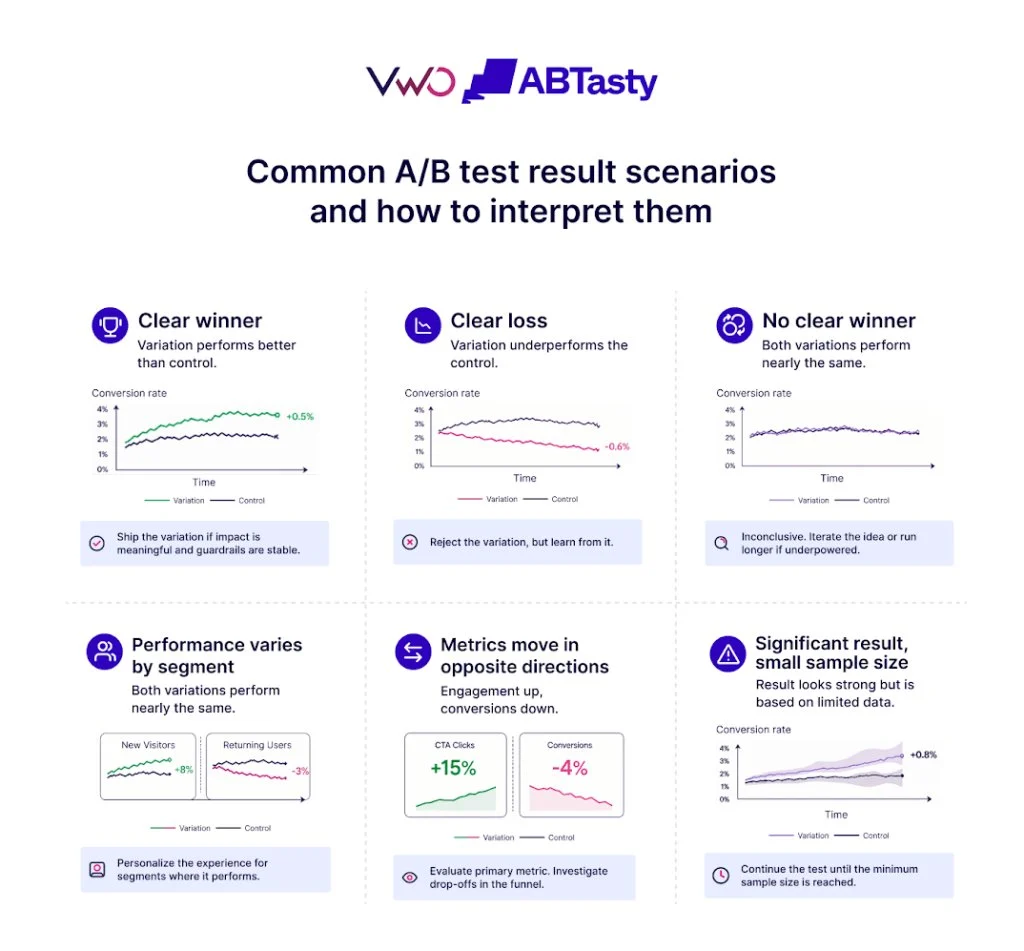
The rapid adoption of data-driven decision-making across the global business landscape has positioned A/B testing as the primary engine for growth in software-as-a-service (SaaS), e-commerce, and digital product development. However, a growing body of evidence suggests that the integrity of these experiments is frequently compromised by a phenomenon known as "p-hacking." This practice, whether intentional or accidental, involves the manipulation of experimental data until statistical significance is achieved, leading to a surge in false positives that can severely undermine a company’s long-term strategy and return on investment.
The Mechanics of P-Hacking and the Influence of Goodhart’s Law
At its core, p-hacking in the context of A/B testing refers to the misuse of data analysis to find patterns that can be presented as statistically significant when no real effect exists. This trend is often cited as a modern manifestation of Goodhart’s Law, which posits that "when a measure becomes a target, it ceases to be a good measure." In the high-pressure environment of Conversion Rate Optimization (CRO), where "wins" are often used as a metric for professional success, the pressure to deliver positive results can lead testers to prioritize significant p-values over actual business insights.

The danger lies in the inherent nature of probability. In a standard frequentist A/B test, a p-value of 0.05 suggests a 5% chance that the observed difference occurred by random chance. When testers engage in p-hacking—such as checking results daily and stopping as soon as the p-value dips below the threshold—they are essentially "rolling the dice" multiple times, drastically increasing the likelihood of capturing a fluke result and labeling it a victory.
Statistical Toll: Analyzing the False Discovery Rate
The scale of the problem was highlighted in a comprehensive 2018 analysis of 2,101 commercially run A/B tests. The study found that approximately 57% of experimenters engaged in some form of p-hacking once their results reached a 90% confidence level. This behavior has a compounding effect on the False Discovery Rate (FDR) of an experimentation program.
Statisticians note that at a 90% confidence threshold, a program that adheres to strict rigor might expect an FDR of roughly 33%. However, when p-hacking behaviors are introduced, that rate climbs to 42% or higher. This means that nearly half of all reported "winning" experiments may actually be statistical noise. For a large enterprise, implementing "winning" changes that provide no real value—or worse, cause undetected harm—leads to significant technical debt and wasted engineering resources.

Sundar Swaminathan, author of the experiMENTAL Newsletter, emphasizes that p-hacking is one of the most dangerous pitfalls in the industry because it masks random noise as significant results. According to Swaminathan, when testers stop experiments prematurely, they are cherry-picking data points that support their initial hypothesis while ignoring the broader statistical context. This compromises the credibility of the entire testing program.
A Chronological Breakdown of the Experimentation Lifecycle
To understand how p-hacking infiltrates a testing program, it is necessary to examine the chronology of an A/B test and identify the specific points where rigor typically breaks down.
Phase I: Pre-Experiment Design
The risk begins before the first visitor is ever tracked. Failure to pre-calculate the required sample size or define a fixed duration is the most common precursor to p-hacking. Without these "statistical guardrails," the experiment has no objective end-point, leaving it vulnerable to subjective interpretation.
Phase II: The Execution and the "Peeking" Problem
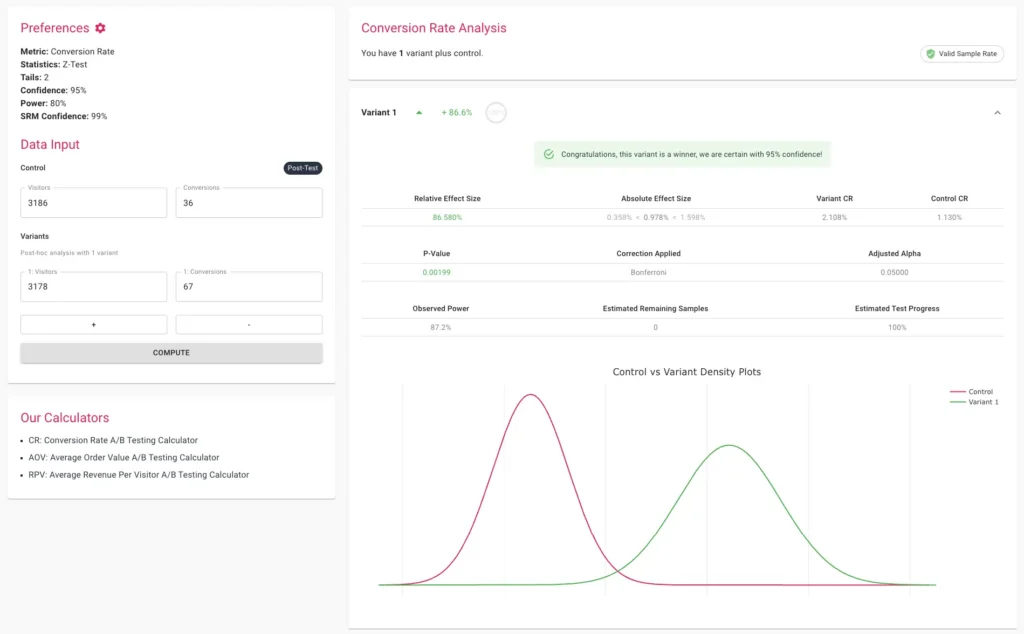
Once a test is live, the temptation to "peek" at the results becomes a primary driver of p-hacking. In a standard fixed-horizon test, the statistical math assumes that the data will only be analyzed once the predetermined sample size is reached. Checking the p-value repeatedly and stopping the test the moment it looks favorable—a practice known as "continuous monitoring" without adjustment—inflates the Type I error rate.
Phase III: Post-Experiment Analysis and Data Slicing
After a test concludes, if the primary metric does not show significance, testers may engage in "post-test segmentation." This involves slicing the data by device, geography, or traffic source until a "winning" segment is found. While segment analysis is valuable for generating new hypotheses, reporting a segment-specific win as the primary outcome of the original test without further validation is a classic form of p-hacking.
Technical Mitigations and Modern Methodologies
To combat these risks, the industry is shifting toward more robust statistical frameworks and automated tools that enforce discipline. Modern experimentation platforms, such as Convert Experiences, have integrated features designed to prevent the most common p-hacking behaviors.
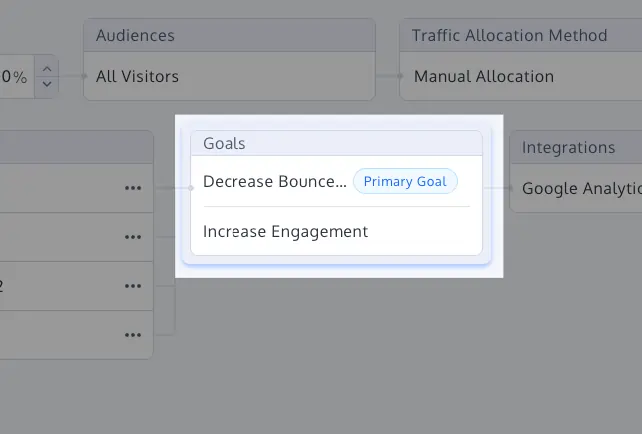
1. Primary Goal Labeling and Metric Hierarchies
One of the most effective ways to prevent p-hacking is the strict definition of a "North Star" primary metric before the test begins. By labeling secondary metrics as "guardrails" rather than success criteria, organizations prevent the practice of "metric switching," where a failure in the primary goal is ignored in favor of an accidental lift in a secondary goal.
2. Multiple Comparison Corrections: Bonferroni and Sidak
When an experiment involves multiple variants (e.g., an A/B/C/D test), the probability of finding a false positive increases with each additional variant. To correct for this, statisticians use the Bonferroni or Sidak corrections. These methods adjust the significance threshold (alpha) downward, making it harder to claim success by chance alone. While the Bonferroni correction is more conservative, the Sidak correction is often preferred for mission-critical experiments as it maintains more statistical power while still controlling the family-wise error rate.
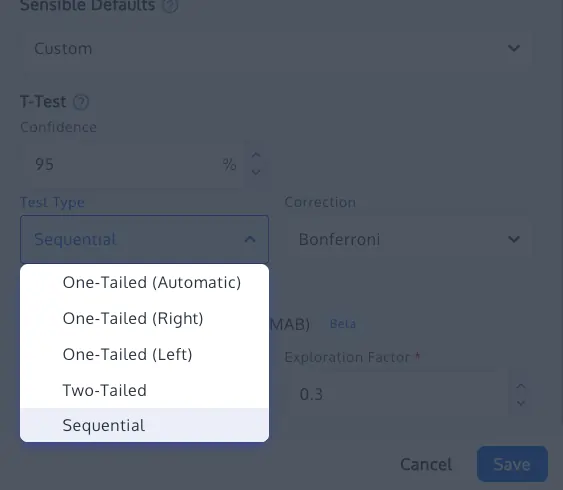
3. Sequential Testing and Confidence Sequences
For teams that require the ability to monitor tests in real-time, sequential testing offers a mathematically sound alternative to fixed-horizon testing. Based on recent advancements such as those by Waudby-Smith et al. (2023), sequential testing uses confidence sequences that remain valid at any point during data collection. This allows for "early stopping" for both winning and losing variations without inflating the Type I error rate.
4. Multi-Armed Bandits (MAB)
In scenarios where speed is prioritized over causal proof—such as short-term promotional campaigns—Multi-Armed Bandits offer a dynamic approach. MAB algorithms, like Thompson Sampling or Epsilon-Greedy, automatically shift traffic toward better-performing variants in real-time. While not a substitute for traditional A/B testing in generating long-term insights, MAB reduces the "opportunity cost" of running a test and removes the incentive for manual p-hacking.
The Critical Role of Sample Ratio Mismatch (SRM) Checks
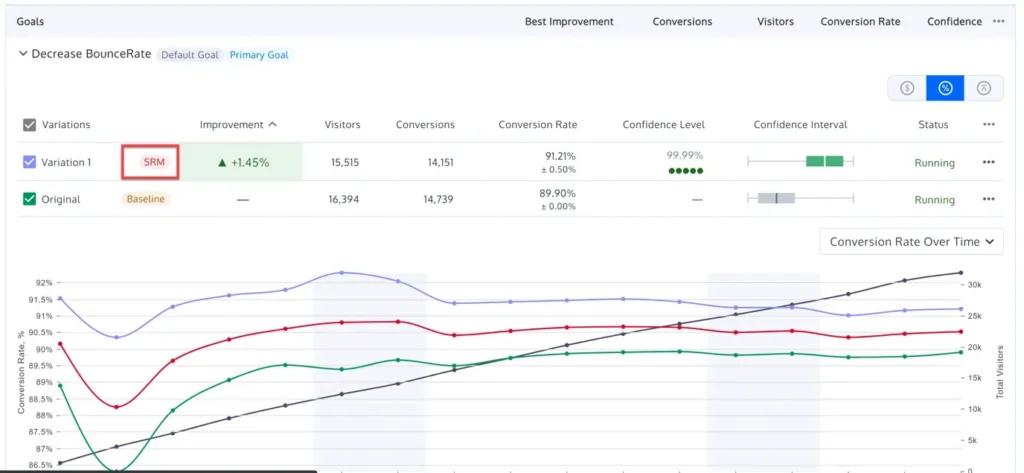
Even the most rigorous statistical analysis can be rendered useless if the underlying data is flawed. A Sample Ratio Mismatch (SRM) occurs when the actual distribution of visitors between the control and treatment groups deviates significantly from the intended split (e.g., a 50/50 split resulting in a 48/52 distribution).
SRM is often a symptom of technical issues, such as faulty redirection, bot interference, or tracking discrepancies. Industry leaders now advocate for mandatory SRM checks using a Chi-square goodness-of-fit test. If an SRM is detected, the results of the experiment should be considered compromised, regardless of the p-value. Detecting an SRM early is a vital safeguard against making decisions based on biased data sets.
Broader Impact and Organizational Implications
The implications of p-hacking extend beyond individual experiments; they affect the entire culture of an organization. When "false wins" are celebrated, it creates a feedback loop of misinformation. Companies may find themselves wondering why their "winning" experiments are not translating into actual revenue growth or improved user retention.
Furthermore, p-hacking erodes the trust between data science teams and executive leadership. If a testing program consistently reports high win rates that do not reflect in the company’s financial statements, the perceived value of experimentation diminishes. This can lead to reduced budgets for CRO and a return to "HIPPO" (Highest Paid Person’s Opinion) decision-making.
To build a sustainable experimentation culture, organizations must move away from a "win-at-all-costs" mentality. Success should be measured not just by the number of winning tests, but by the quality of the insights generated and the rigor of the process. This requires a combination of education, cultural shifts, and the implementation of software that acts as an unbiased referee.
Conclusion: Strengthening the Foundations of Data Science
The fight against p-hacking is a fight for the soul of digital experimentation. As tools become more accessible and the volume of data grows, the responsibility to use that data ethically and accurately becomes paramount. By adopting rigid stopping rules, utilizing advanced corrections for multiple variants, and leveraging platforms that prioritize statistical integrity over "flashy" wins, businesses can ensure that their A/B testing programs remain a source of truth rather than a source of noise.
The path forward involves a disciplined approach to experiment design: pre-calculating sample sizes, sticking to two-tailed tests by default, and maintaining a healthy skepticism toward "overnight" successes. In the long run, the organizations that prioritize the integrity of their data will be the ones that achieve genuine, scalable growth in an increasingly competitive digital economy.