The landscape of data science and local analytics is undergoing a fundamental shift as the industry moves from a period of “Big Data” obsession toward a more nuanced “Small Data” philosophy. While pandas has long been the undisputed sovereign of the Python data ecosystem, the emergence of Polars and DuckDB has introduced a new paradigm of efficiency and performance. For over a decade, pandas served as the default choice for exploratory data analysis (EDA), visualization, and machine learning workflows. However, as datasets grow in complexity and hardware capabilities advance, the limitations of the aging pandas architecture—primarily its single-threaded execution and high memory overhead—have paved the way for modern alternatives designed for high-performance computing.
Polars, a Rust-based DataFrame library, focuses on lightning-fast, memory-efficient processing by leveraging multithreading and lazy execution. Simultaneously, DuckDB has revolutionized the space by bringing a SQL-first approach to local files, functioning as an embedded analytical database that can query Parquet and CSV files with the speed of a traditional data warehouse. Each of these tools represents a different philosophy regarding how data should be handled on a single machine, and understanding their architectural differences is now a critical skill for data engineers and scientists alike.
The Historical Context: From pandas to the Modern Era
To understand the current competition between these libraries, one must look at the timeline of their development. The journey began in 2008 when Wes McKinney started developing pandas at AQR Capital Management. By 2011, pandas was open-sourced, quickly becoming the backbone of the Python data science boom. For years, it had no serious competitors in the local processing space, largely because it was built on top of NumPy, which provided the necessary speed for numerical operations.

However, as data sizes increased from megabytes to gigabytes, the “memory wall” became a significant issue. pandas typically requires five to ten times as much RAM as the size of the dataset to perform operations comfortably. This inefficiency led to the development of alternative engines. In 2019, researchers Hannes Mühleisen and Mark Raasveldt at the Centrum Wiskunde & Informatica (CWI) in the Netherlands launched DuckDB, aiming to create an “SQLite for Analytics.” Shortly thereafter, in 2020, Ritchie Vink introduced Polars, written in Rust and built on the Apache Arrow memory format, specifically designed to utilize all available CPU cores.
Architectural Philosophies: Eager vs. Lazy Execution
The primary differentiator among these three tools is their underlying architecture and how they execute queries. pandas is fundamentally an “eager” execution engine. When a user writes a line of code to filter a DataFrame, pandas executes that operation immediately, creating a new object in memory. While this makes it highly interactive and easy to debug in a Jupyter notebook, it is notoriously inefficient for complex pipelines because it cannot optimize the sequence of operations.
In contrast, Polars offers both eager and lazy execution modes. Its “LazyFrame” API allows users to define a series of transformations without executing them. When the user finally calls for the result, Polars’ query optimizer looks at the entire plan. It can perform “predicate pushdown” (filtering data as it is read from the source) and “projection pushdown” (selecting only necessary columns), which significantly reduces the memory footprint and increases speed.
DuckDB operates similarly to a traditional relational database management system (RDBMS). It uses a vectorized query execution engine, processing data in “batches” that fit into the CPU cache. Like Polars, DuckDB is a columnar engine, meaning it only reads the columns required for a specific query, making it exceptionally fast for analytical tasks like joins and aggregations across massive files.

Performance and Memory Management Benchmarks
Performance is the most cited reason for the migration away from pandas toward Polars or DuckDB. In standard benchmarks involving multi-gigabyte datasets, the differences are stark. Because pandas is mostly single-threaded, it cannot take advantage of modern multi-core processors. Polars, however, is written in Rust, a language known for “fearless concurrency,” allowing it to distribute tasks across all available cores automatically.
Data professionals often observe that Polars and DuckDB can handle datasets that would cause pandas to crash due to “Out of Memory” (OOM) errors. DuckDB, in particular, excels at “out-of-core” processing. This means it can execute queries on datasets that are larger than the available system RAM by intelligently spilling data to the disk. This capability effectively bridges the gap between local analysis and distributed computing frameworks like Apache Spark.
According to various industry benchmarks, including the H2O.ai Database-like Ops Benchmark, Polars and DuckDB consistently outperform pandas by factors of 10x to 50x on common operations such as “group by” and “join” on datasets exceeding 5GB. While pandas remains performant for small datasets (under 100MB), the overhead of its NumPy-based string handling and object types becomes a bottleneck as scale increases.
Hands-on Comparative Implementation: A Practical Scenario
To illustrate the practical differences, consider a standard data pipeline involving two datasets: an “orders” file in Parquet format and a “customers” file in CSV format. The goal is to join these tables, filter for completed orders, calculate daily revenue by customer segment, and save the result.
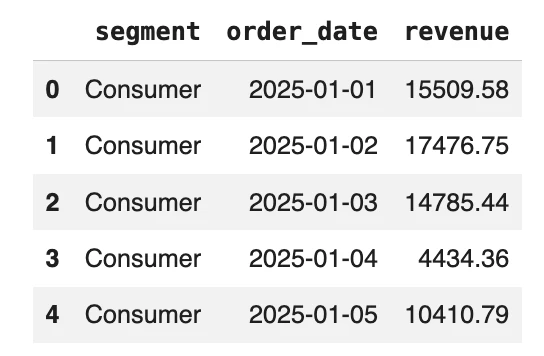
The pandas Approach: Eager and Familiar
In a pandas workflow, the user reads both files into memory as DataFrames. The process is step-by-step: first loading, then merging, then calculating a new date column, and finally grouping. Because pandas loads the entire Parquet file into RAM before filtering, it uses significantly more memory than necessary. However, for a data scientist working in a notebook, the ability to inspect the DataFrame at every step remains a powerful advantage for rapid prototyping.
The Polars Approach: Optimized and Parallel
Using Polars, the developer typically uses scan_parquet() and scan_csv() instead of read_. This creates a lazy query plan. The join and filter operations are not executed until the collect() method is called. This allows Polars to ignore any rows in the Parquet file that don’t meet the “status == complete” criteria before they even enter memory. The result is a much faster execution time and a lower peak memory usage.
The DuckDB Approach: SQL-First Efficiency
DuckDB treats the local files as tables in a database. The entire operation can be written in a single SQL query. DuckDB’s ability to query a Parquet file directly without an explicit “import” step is a game-changer for many analysts. It uses its internal optimizer to handle the join and aggregation, often completing the task in a fraction of the time required by pandas, especially when the datasets involve complex joins.
Interoperability and the Role of Apache Arrow
A common misconception is that these tools are mutually exclusive. In reality, the modern data stack is built on interoperability, largely thanks to Apache Arrow. Arrow is a cross-language development platform for in-memory data that specifies a standardized columnar memory format.
Polars is built natively on Arrow, and DuckDB has high-performance integration with it. This means that a user can perform a heavy SQL join in DuckDB, convert the result to a Polars DataFrame for complex feature engineering, and finally pass it to a pandas-based library like Scikit-learn for machine learning—all without the expensive overhead of copying or serializing the data. This “Zero-Copy” capability is what allows these three tools to coexist in a single production pipeline.
Industry Adoption and Future Implications
The reaction from the data science community has been one of rapid adoption. Major tech firms are increasingly integrating Polars into their ETL (Extract, Transform, Load) pipelines to save on cloud computing costs. Because Polars and DuckDB can do more with less hardware, companies can often avoid moving to expensive Spark clusters for “medium-sized” data (10GB to 100GB), keeping their workflows simpler and more maintainable.
However, pandas is far from obsolete. Its ecosystem is massive, with over 100 million monthly downloads. Visualization libraries like Matplotlib and Seaborn, as well as machine learning frameworks like PyTorch and Scikit-learn, are built around pandas compatibility. For many practitioners, the “ease of use” and the ability to find solutions to any problem on Stack Overflow keep pandas as their primary tool for final-stage analysis.
Strategic Decision Matrix: Choosing the Right Tool
The choice between these libraries should be based on the specific requirements of the project rather than raw speed alone.
- Choose pandas when: You are performing exploratory analysis on small to medium datasets, require deep integration with the Python ML ecosystem, or are working in an environment where ease of debugging is the top priority.
- Choose Polars when: You need maximum performance in a DataFrame-centric workflow, are dealing with large datasets that strain system memory, or are building production-grade ETL pipelines that require multithreading.
- Choose DuckDB when: Your workflow is SQL-heavy, you need to query local files (Parquet/CSV/JSON) directly without a loading phase, or you require a local persistence layer (a database file) for your analytics.
Conclusion: A Hybrid Future
As the data ecosystem matures, the “one tool fits all” mentality is fading. The most effective data professionals are those who recognize that pandas, Polars, and DuckDB are complementary. By using DuckDB for initial file scanning and SQL-based joins, Polars for high-speed transformations, and pandas for final visualization and modeling, developers can create pipelines that are both highly performant and easy to maintain.
The rise of Polars and DuckDB does not signal the death of pandas, but rather its transition into a specialized role within a broader, more powerful toolkit. This evolution reflects a broader trend in software engineering: the move toward specialized engines that prioritize hardware efficiency and parallel execution, ensuring that as data continues to grow, our ability to process it remains one step ahead.