The determination of A/B test duration has emerged as a cornerstone of modern digital experimentation, serving as the critical juncture where statistical theory meets practical business application. While the industry lacks a singular, universal timeframe for running experiments, the consensus among leading conversion rate optimization (CRO) experts suggests that duration is governed by a complex interplay of traffic volume, minimum detectable effect (MDE), significance thresholds, and statistical power. For organizations seeking to leverage data for growth, understanding these variables is not merely a technical requirement but a strategic imperative that dictates the pace of innovation and the reliability of business decisions.
The Fundamental Mechanics of Experimentation Timing
Test duration is defined as the total elapsed time from the initial split of traffic between variations to the moment a final conclusion is drawn. In a professional experimentation framework, this period is far more than a simple countdown; it serves as a feasibility study for the hypothesis itself. Before a single line of code is deployed, a duration estimate provides a "reality check" on whether a specific change is worth pursuing. If a mathematical projection indicates that a test requires fourteen weeks to reach statistical significance on a low-traffic homepage segment, the business is signaled to either broaden the segment, aim for a more substantial impact, or pivot to a different hypothesis entirely.

Industry veterans emphasize that duration calculations must be finalized before the launch of any experiment. This "fixed-horizon" approach prevents the common pitfall of "peeking"—the practice of checking results prematurely and stopping the test as soon as a favorable trend appears. Such behavior significantly inflates the false-positive rate, leading companies to implement changes that do not actually drive value, or worse, negatively impact the user experience.
Expert Methodologies in Duration Planning
Top-tier experimenters have developed diverse yet complementary frameworks for determining how long a test should remain active. Kateryna Berestneva, CRO Manager at SomebodyDigital, advocates for a threshold-based approach. In her professional practice, Berestneva recommends a minimum of 100 conversions per variation and a statistical significance level of at least 95%. Based on typical user behavior patterns, she notes that this frequently translates to a duration of four to six weeks. This timeframe is designed to account for weekly cycles, ensuring that the data captures both weekday and weekend purchasing behaviors, which often differ significantly.
In contrast, Sadie Neve, Group Digital Experimentation Manager at Rubix, focuses on the broader experimentation landscape. Neve stresses the importance of mapping traffic volumes and baseline performance across the entire site before committing to an experiment. This mapping allows teams to identify which areas of a digital property can realistically support multi-variant testing and which require more conservative, two-way splits. By utilizing specialized spreadsheets that factor in baseline conversion rates and daily traffic, Neve ensures that tests are only designed for areas where the traffic can support a statistically sound conclusion within a reasonable timeframe.
Gerda Thomas, co-founder of Koalatative, advocates for the use of specialized pre-test calculators to eliminate human error and subjective guesswork. These tools allow teams to input weekly traffic and conversion data to receive a defensible timeframe. This methodological rigor ensures that the experimentation backlog remains fluid and that resources are not wasted on "zombie tests"—experiments that run indefinitely without the hope of reaching a valid conclusion.
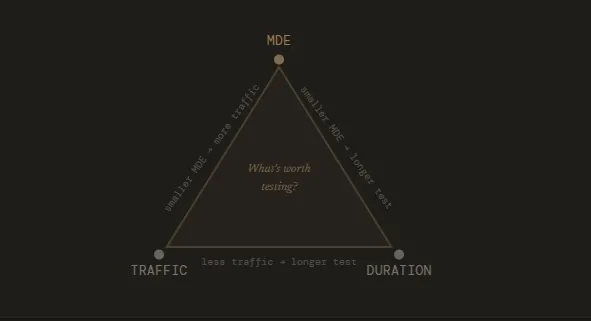
The Relationship Between Resolution, MDE, and Sample Size
To understand duration, one must understand the concept of "experiment resolution." This analogy, popularized within the experimentation community, compares an A/B test to an artist’s canvas. A high-resolution drawing, which captures minute details, requires more time and a finer brush. Similarly, detecting a small MDE (a subtle change in user behavior) requires a significantly larger sample size and, consequently, a longer duration.
The mathematical relationship is non-linear: to detect an effect that is half the size of another, an experimenter typically needs four times the sample size. This means that if a business decides it needs to detect a 2% lift instead of a 4% lift, the test duration could jump from two weeks to eight weeks. Professional testers must therefore balance the desire for granular insights with the practical need to maintain a high velocity of testing.
The Risks of Prolonged Testing and Sample Pollution
While stopping a test too early is a well-documented error, running a test for too long introduces its own set of risks, primarily in the form of sample pollution. As an experiment stretches over several months, external factors increasingly threaten the integrity of the data. Seasonal shifts, such as the transition into a holiday shopping period or a sudden change in market conditions, can alter user behavior in ways that have nothing to do with the test variations.
Furthermore, technical factors like "cookie churn" become a concern. Most A/B testing tools rely on browser cookies to ensure a consistent experience for the user. Over long durations, users may clear their cookies or switch devices, potentially seeing multiple versions of the test and blurring the distinction between the control and the variant. Ruben de Boer, owner at Conversion Ideas, suggests that while many valid tests run between two to four weeks, the goal should be to capture full business cycles while maintaining stable conditions. He argues that it is often better to run a three-week test with a 3% MDE than a one-week test with a 10% MDE, as the former provides a more realistic view of sustainable growth.
Impact on Product Backlogs and Quarterly Goals
The duration of individual tests directly impacts the throughput of an entire experimentation program. In a corporate environment, every test run represents an opportunity cost—the decision to test one hypothesis is a decision not to test another. If a team runs four concurrent tests that each take six weeks, they can only complete approximately two cycles per quarter. By optimizing duration estimates and potentially targeting larger MDEs, a team might increase their velocity to three or four cycles per quarter, dramatically increasing the number of validated insights generated for the business.

For teams with limited traffic, the challenge of duration is even more acute. Fewer visitors necessitate longer tests, which can lead to a "stale" roadmap. In these instances, experts suggest focusing on "bold" changes that are likely to produce a larger MDE, thereby reducing the required sample size and keeping the program moving forward.
When Early Termination is Statistically Defensible
Despite the strict rules against peeking, there are specific, fringe scenarios where stopping a test early is considered a professional necessity. Ioana Iordache, Founder and Product Growth Consultant at Io Growth Lab, identifies three primary justifications:
- Technical Malfunction: If a variant is found to be "broken" (e.g., the checkout button does not function on certain browsers), the test must be stopped immediately to prevent further revenue loss and data corruption.
- Severe Negative Impact: If a variation is causing a catastrophic drop in key performance indicators (KPIs)—often referred to as a "guardrail metric"—the business must intervene to protect its bottom line.
- Extreme Outperformance: In very rare cases, a variant may perform so significantly better than the control that the statistical power is reached much earlier than anticipated. However, this requires rigorous post-hoc analysis to ensure the result isn’t a fluke of early-stage noise.
Strategic Recommendations for Implementation
For organizations looking to refine their experimentation culture, several habits are recommended by industry leaders. First, teams should adopt a "set it and forget it" mentality. Once the pre-test duration is calculated, the results should ideally not be analyzed until the timeframe has elapsed. This prevents emotional decision-making based on temporary fluctuations in the p-value.
Second, the use of frequentist duration calculators, such as those provided by Convert, allows for a "fixed-horizon" approach that is statistically robust. By inputting baseline conversion rates, weekly visitors, and the number of variants, businesses can generate a clear, defensible window for their experiments.
Finally, the MDE should be treated as a business decision rather than just a statistical one. The MDE represents the minimum lift that would justify the cost of implementing the change. If a developer’s time is expensive, a 0.5% lift may not be worth the investment. By setting a higher MDE, the business naturally shortens the test duration and focuses its resources on high-impact changes.
Conclusion and Broader Implications
The science of A/B test duration is a vital component of risk management in the digital age. By adhering to calculated timeframes, organizations ensure that their growth strategies are built on a foundation of stable, reproducible data rather than statistical noise. As the digital marketplace becomes increasingly competitive, the ability to accurately forecast and execute experiment durations will separate market leaders from those who are merely guessing. Proper duration planning doesn’t just protect the integrity of a single test; it safeguards the entire trajectory of a company’s data-driven evolution.