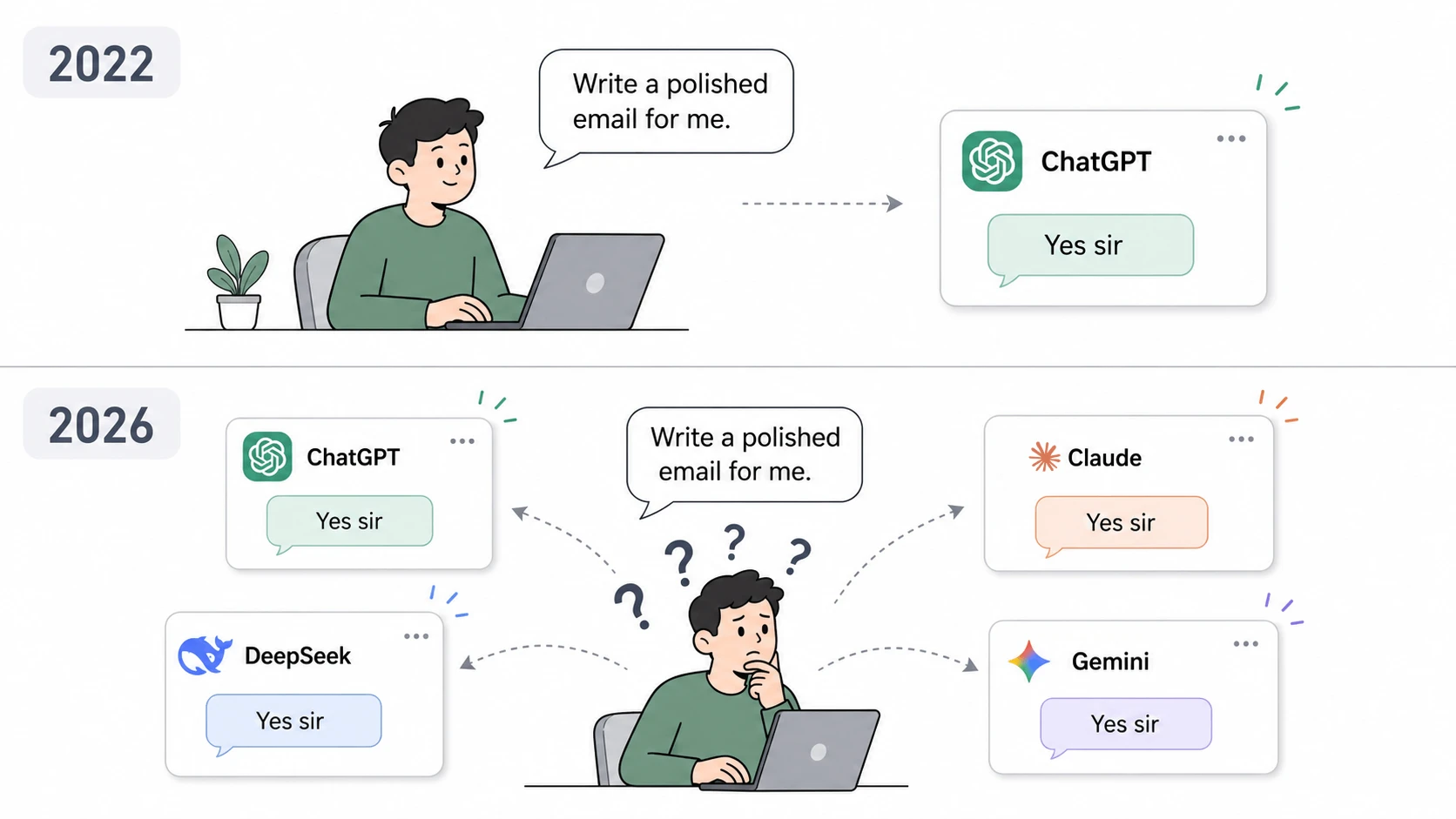
The landscape of generative artificial intelligence has undergone a profound transformation over the last three years, evolving from a market dominated by a single player into a highly fragmented ecosystem of specialized models. In the early stages of the AI boom, specifically following the late 2022 release of ChatGPT, the term “AI” was often used interchangeably with the OpenAI product. For the general public and enterprise users alike, there was no choice to be made; ChatGPT was the definitive tool for text generation, coding assistance, and creative brainstorming. However, as of late 2025 and moving into 2026, this monopoly has dissolved. Users are now confronted with an overwhelming array of options, including Anthropic’s Claude, Google’s Gemini, Elon Musk’s Grok, Meta’s Llama, and emerging international powerhouses like DeepSeek, Qwen, and Kimi.
While the proliferation of these Large Language Models (LLMs) was intended to empower users through competition and variety, it has instead fostered a “paradox of choice.” Because most top-tier models utilize similar chatbot interfaces and demonstrate comparable capabilities in general conversation, the differences between them have become increasingly subtle. This has led many users to select their primary AI tool based on brand recognition, aesthetic preference, or news headlines rather than technical suitability for specific workflows. Consequently, the central question for the modern user has shifted from “Which model is the best?” to “Which model is the best for my specific needs?”
A Chronology of the AI Model Explosion
To understand the current state of the market, one must look at the timeline of development that led to this saturation. In 2023, the industry saw the first major wave of competition as Google rebranded its efforts into Gemini and Anthropic introduced Claude, a model focused on “Constitutional AI” to ensure safer and more human-like interactions. By 2024, the focus shifted toward multi-modality—the ability to process images, audio, and video alongside text.
By 2025, the industry reached a state of parity where the “State of the Art” (SOTA) title began changing hands almost monthly. OpenAI’s release of the GPT-5 series was met with immediate counter-offensives from Anthropic’s Claude 4.0 series. Simultaneously, open-source models like Meta’s Llama 4 achieved performance levels that rivaled paid proprietary systems, democratizing high-level reasoning. This rapid succession of releases has created a market where the average consumer can no longer keep pace with technical specifications, leading to a reliance on benchmarks that may not reflect real-world utility.

The Benchmark Paradox: Why Metrics Can Be Misleading
The AI industry relies heavily on standardized benchmarks to rank model performance. Metrics such as MMLU (Massive Multitask Language Understanding), HumanEval for coding, and GSM8K for grade-school math are frequently cited in marketing materials. However, industry analysts warn that these scores often act as a “smoke screen” for several reasons.
First, models are increasingly being trained on the very data used in these tests, leading to “benchmark contamination.” A model might score exceptionally high on a coding test because it has “memorized” the solutions during its training phase, yet it may struggle with novel, real-world programming tasks. Second, most public benchmarks are conducted using the flagship, paid versions of models—such as Claude 4.7 Thinking or GPT-5.5. The free versions available to the general public are often significantly “distilled” or older iterations, creating a performance gap that benchmarks do not always disclose.
For instance, recent data from Artificial Analysis and LMSYS Chatbot Arena—a platform that uses blind human preference votes—shows that while one model might lead in mathematical reasoning, it may lag behind in creative writing or emotional intelligence. Claude Opus 4.6 and 4.7, for example, have recently dominated the LMArena text leaderboards due to their perceived “natural” tone, whereas GPT-5.2 and 5.5 remain the preferred choices for economically valuable tasks across professional occupations, according to OpenAI’s GDPval metric.
Economic Disparities in AI Accessibility
A critical factor often overlooked in the selection process is the “pay-to-play” nature of modern AI. The most sophisticated reasoning capabilities are currently locked behind subscription models, typically costing $20 USD per month for individual users. This creates a tiered system of intelligence:
- The Pro Tier: Users paying for subscriptions get access to the latest reasoning models (e.g., Claude 4.8, GPT-5.5), larger context windows (the amount of text a model can “remember” in one session), and priority access during peak hours.
- The Free Tier: These users often interact with smaller, faster, but less “intelligent” versions of the models. For example, a free user might be limited to GPT-4o mini or Claude Haiku, which lack the deep reasoning of their “Pro” counterparts.
- The Open-Source Tier: Models like Llama and DeepSeek provide a middle ground, offering high performance for those with the technical infrastructure to host them locally, bypassing subscription fees but requiring significant hardware investment.
This disparity means that a user choosing a model based on a benchmark may be disappointed if they are using the free version, as the benchmark likely measured a version of the software they are not actually accessing.
A Practical Framework for Model Selection
Given the limitations of general benchmarks, experts recommend that individuals and enterprises develop a personalized evaluation rubric. Rather than asking which model is globally superior, users should identify the three tasks that constitute the majority of their AI interaction.
For a software engineer, these tasks might be code refactoring, bug documentation, and unit test generation. For a marketing professional, the tasks might be SEO optimization, creative copywriting, and consumer sentiment analysis. Once these tasks are identified, the user should perform a “side-by-side” test across the major platforms—ChatGPT, Claude, and Gemini—and score them on a 1-to-5 scale based on the following criteria:
- Accuracy: Does the model provide factually correct and hallucination-free information?
- Instruction Following: How well does the model adhere to complex, multi-step prompts?
- Tone and Style: Does the output require extensive editing to match the user’s voice?
- Speed and Reliability: Is the response generated quickly, or does the system frequently time out?
In a recent internal study conducted by productivity analysts, GPT-5.5 emerged as the winner for a diverse workload involving research and technical writing, scoring 14 out of 15 points. Claude followed closely with 12 out of 15, praised for its superior creative writing but slightly lower performance in raw data extraction. Gemini rounded out the top three with 10 out of 15, noted for its excellent integration with Google Workspace but criticized for occasional inconsistencies in following negative constraints (e.g., “do not include X”).
Industry Reactions and Broader Implications
The shift toward specialized model selection is already impacting how AI companies market their products. Anthropic has increasingly positioned Claude as the “writer’s AI,” focusing on nuanced language and long-form document processing. Conversely, OpenAI has doubled down on the “AI Agent” concept, emphasizing GPT’s ability to interact with external tools, browse the web, and execute code in real-time.
Corporate leaders are also moving away from “all-in-one” AI adoptions. “We are seeing a trend where companies no longer sign enterprise agreements with just one provider,” says Sarah Chen, a lead analyst in emerging technologies. “Instead, they are using API routers to send coding tasks to one model, creative tasks to another, and data summarization to a third, more cost-effective model. The future is multi-model.”

This trend has significant implications for the labor market. As AI becomes more specialized, “prompt engineering” is evolving into “model orchestration”—the ability to know which specific AI tool is best suited for a particular professional challenge. It also raises questions about data privacy; users must now consider not only which model performs best, but which provider offers the most robust security for their specific industry.
Conclusion: The Path Forward in 2026
The era of the “default” AI model is over. As the technology continues to mature, the marginal gains in benchmark scores will become less relevant than the specific “feel” and integration of the model into a user’s daily workflow. The most successful users will not be those who follow the hype of the latest release, but those who apply an empirical approach to their own productivity.
By grounding the decision-making process in personal evidence rather than marketing metrics, users can navigate the crowded AI marketplace with confidence. Whether the choice is the reasoning power of the GPT series, the literary flair of Claude, or the ecosystem integration of Gemini, the “best” model remains a subjective determination based on the unique intersection of task, cost, and desired output. In the fast-moving world of artificial intelligence, the only constant is that the best tool for the job today may be surpassed tomorrow, necessitating a continuous cycle of testing and re-evaluation.