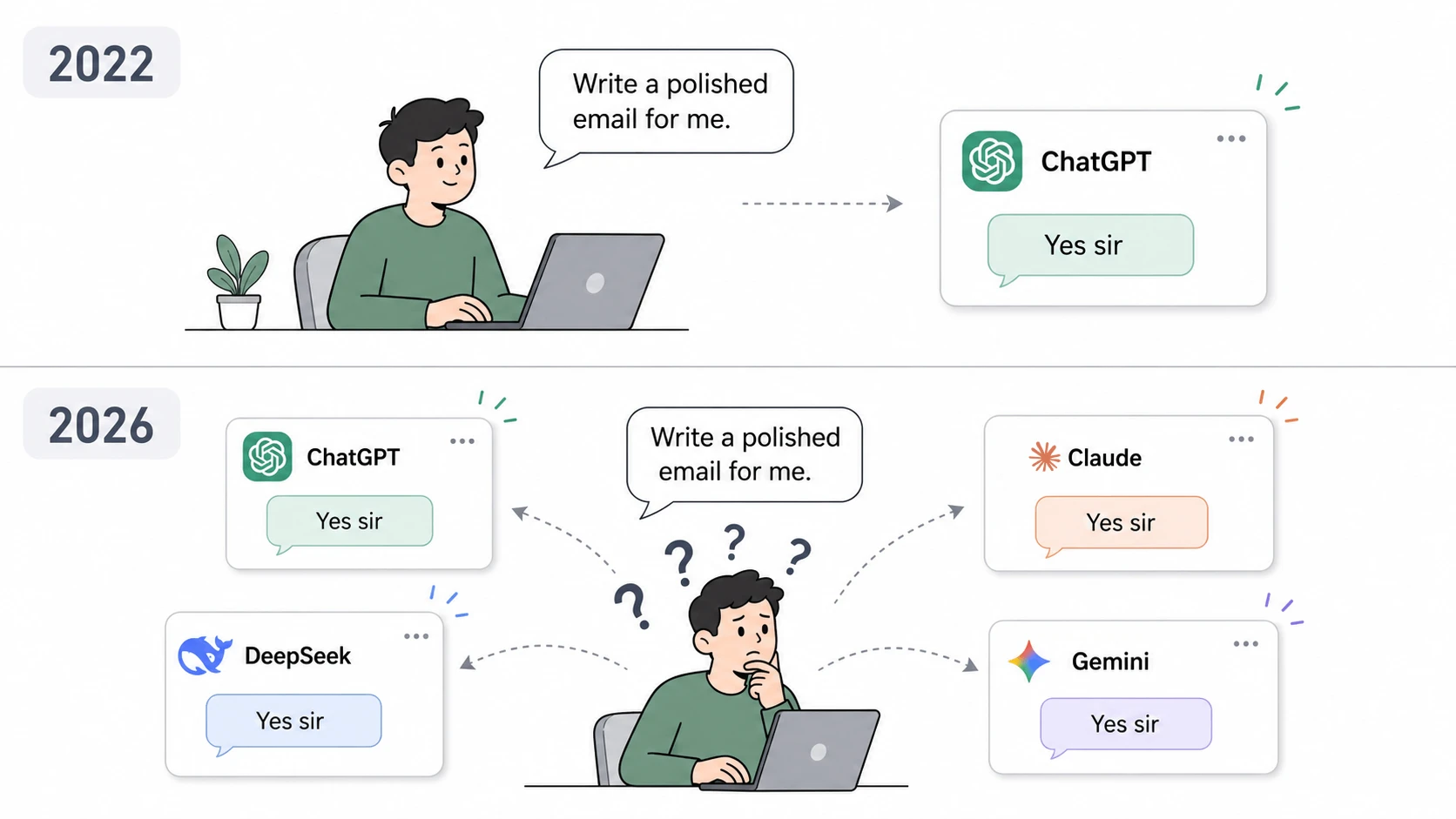
The landscape of artificial intelligence has undergone a fundamental transformation, shifting from a period of singular dominance to an era of intense market fragmentation. Just a few years ago, the consumer experience with artificial intelligence was almost entirely synonymous with OpenAI’s ChatGPT. At its inception, the choice for users was non-existent; ChatGPT was the default gateway to large language models (LLMs). However, the current technological environment presents a starkly different reality. Today, users are confronted with a dizzying array of sophisticated alternatives, including Anthropic’s Claude, Google’s Gemini, Meta’s Llama, and emerging powerhouses such as DeepSeek, Qwen, and Grok. While this abundance of choice was intended to empower the end-user, it has instead birthed a “paradox of choice,” where the superficial similarities between chatbot interfaces obscure the profound differences in their underlying capabilities.
As these models evolve at a comparable pace, the primary challenge for individuals and enterprises has shifted. The question is no longer “Which model is the best?” but rather “Which model is the best for my specific needs?” Despite the availability of high-level benchmarks and marketing claims, most users continue to select models based on brand recognition, interface aesthetics, or anecdotal recommendations—a methodology that often leads to suboptimal results and wasted resources.
The Evolution of the AI Market: A Brief Chronology
To understand the current state of model fragmentation, one must look at the timeline of generative AI development. The release of ChatGPT in late 2022 served as the “Big Bang” moment for consumer AI, establishing a monopoly on public attention. Throughout 2023, the industry saw the entrance of major competitors. Google rebranded its AI efforts under the Gemini umbrella, while Anthropic positioned Claude as a more “constitutional” and human-centric alternative.
By 2024 and 2025, the market matured into a high-stakes arms race characterized by the rapid-fire release of “frontier” models. This period saw the introduction of GPT-5 series variants and Claude’s 4.0 architecture, which pushed the boundaries of reasoning and coding. Concurrently, the rise of open-source models like Meta’s Llama and China’s DeepSeek challenged the dominance of closed-source providers by offering comparable performance at a fraction of the cost. This chronology illustrates a shift from a product-based market to a commodity-based market, where the interface remains static while the “engine” under the hood is swapped out with increasing frequency.
The Benchmark Dilemma: Navigating the Smoke Screen
In the absence of clear personal metrics, many users turn to standardized benchmarks to guide their selection. Metric systems such as MMLU (Massive Multitask Language Understanding), SWE-bench (Software Engineering Benchmark), and the LMSYS Chatbot Arena are frequently cited by developers to claim “state-of-the-art” (SOTA) status.

However, these benchmarks often act as a smoke screen for the average user. While a model like Claude Opus 4.7 may rank at the top of the SWE-bench for software engineering, that performance may not translate to a user who primarily needs a model for creative writing or basic administrative tasks. Furthermore, the industry has observed a phenomenon known as “benchmark contamination,” where training data for new models may inadvertently include the very questions used in the tests, artificially inflating scores.
The following data represents the current standing of flagship models across specialized domains, as of the latest industry evaluations:
| Task Category | Leading Models | Primary Evaluation Metric |
|---|---|---|
| General Conversation | Claude Opus 4.6 / 4.7 | LMSYS Human Preference Votes |
| Software Engineering | Claude Opus 4.7 / GPT-5.5 | SWE-bench Pro / Real-world PR resolution |
| Complex Reasoning | Claude Opus 4.8 / Gemini 3.1 Pro | Artificial Analysis Reasoning Score |
| Economic/Workplace Tasks | Claude Opus 4.1 / GPT-5.2 | GDPval (44 Professional Occupations) |
| Visual Synthesis | GPT Image 2 / GPT Image 1.5 | Blind Preference Image Testing |
While these figures provide a high-level overview of capability, they carry a significant caveat: they almost exclusively reflect the performance of paid, flagship versions.
The Socio-Economic Gap: Free vs. Paid Disparity
A critical factor often overlooked in model selection is the disparity between free tiers and subscription-based services. For the majority of global users who utilize free versions of these chatbots, the high-performance benchmarks touted in press releases are largely irrelevant.
Paid models, such as those behind a $20/month subscription, offer expanded context windows (the amount of information the model can “remember” during a conversation), higher rate limits, and access to more advanced reasoning engines. In contrast, free versions are frequently “distilled” or smaller versions of the flagship model. For instance, while GPT-5.5 might lead in complex reasoning, the free version available to the public may lack the multimodal capabilities or the deep-search functions that define the paid tier. This creates a “performance ceiling” for non-paying users, making the choice of model more about which company offers the most generous free tier rather than which model has the highest theoretical intelligence.
Beyond Top Speed: A Utility-Based Perspective
Choosing an AI model based solely on a leaderboard is analogous to purchasing a vehicle based only on its top speed. While a Formula 1 car is objectively “faster,” it is a poor choice for a family of five or a contractor needing to haul equipment. In the realm of AI, factors such as ecosystem integration, response latency, and “personality” or style preference often outweigh raw computational power.
For example, a researcher might prioritize a model with a massive context window (like Gemini’s 2-million-token capacity) to analyze entire libraries of documents, even if that model scores slightly lower on coding benchmarks. Conversely, a developer may prefer a model with high “conciseness” and low latency to serve as a real-time pair programmer. The industry is currently seeing a divergence in user needs, categorized into three distinct personas:
- The Creative Professional: Prioritizes nuance, tone control, and the absence of “AI-isms” or repetitive phrasing. (Often favoring Claude).
- The Technical Architect: Prioritizes logical consistency, zero-shot coding accuracy, and technical documentation synthesis. (Often favoring GPT or specialized Llama finetunes).
- The Integrated Researcher: Prioritizes the ability to pull data from live web sources, integrate with Google Workspace or Microsoft 365, and handle large datasets. (Often favoring Gemini).
The Personalized Evaluation Framework
To escape the cycle of hype and technical jargon, users are encouraged to develop a personalized scoring rubric. This framework grounds the decision in the user’s “own reality” rather than academic benchmarks. The process involves identifying the three most common tasks performed and testing them across the top three available models.
Step 1: Task Identification
Users should list three specific, repeatable tasks. For a typical professional, these might be:
- Synthesis: “Summarize this 50-page PDF and identify three contradictory statements.”
- Drafting: “Write a client-facing email explaining a project delay without sounding apologetic.”
- Instructional Learning: “Explain the concept of quantum entanglement using a sports metaphor.”
Step 2: Consistent Scoring
Each model is then rated on a scale of 1 to 5 based on criteria that matter to the individual, such as accuracy, the need for follow-up prompts, and the “human-like” quality of the prose.
Step 3: Result Analysis
In a sample evaluation of the 2025-2026 flagship models, a professional workload might yield the following internal scores:
- GPT-5.5: Writing (5), Research (5), Learning (4). Total: 14/15
- Claude Opus 4.7: Writing (4), Research (4), Learning (4). Total: 12/15
- Gemini 3.1 Pro: Writing (2), Research (4), Learning (4). Total: 10/15
In this specific scenario, GPT-5.5 emerges as the winner, not because of a global leaderboard, but because it consistently met the user’s specific demands for high-quality writing and deep research capabilities.

Industry Implications and the Future of Model Selection
As the AI market continues to mature, we are likely to see the rise of “Model Routers”—automated systems that analyze a user’s prompt and automatically direct it to the model best suited for that specific task. This would effectively remove the burden of choice from the user. Until such systems are perfected and widely adopted, the responsibility of selection remains a manual but necessary task.
Industry analysts suggest that the “brand loyalty” seen in the early days of ChatGPT is evaporating. Enterprises are increasingly adopting “model-agnostic” stances, utilizing API aggregators to switch between providers based on cost-efficiency and task performance. This shift forces AI developers to compete not just on general intelligence, but on specialized utility and reliability.
The broader implication is clear: the era of the “all-purpose” AI model may be coming to an end. We are entering a period of specialization where the “best” model is a moving target, defined by the constraints of the task at hand and the specific preferences of the human user.
Conclusion
There is no universally superior AI model. The rapid expansion of the AI sector has provided a wealth of tools, but it has also placed a greater burden on the user to act as a discerning critic. While benchmarks provided by organizations like OpenAI, Anthropic, and Google offer a useful starting point, they cannot account for the nuances of individual workflows or the specific requirements of different professional domains.
The most effective strategy for navigating this fragmented landscape is to remain empirical and objective. By testing models on actual, recurring tasks and scoring them through a consistent personal framework, users can ensure their choice is based on evidence rather than marketing hype. In the high-stakes world of artificial intelligence, the best model is not the one with the highest benchmark score—it is the one that most effectively solves the problems you face every day.