The rapid expansion of the digital economy has transformed A/B testing from a niche statistical tool into a fundamental pillar of corporate strategy, yet this reliance on data-driven decision-making has introduced a systemic risk known as p-hacking. In the context of conversion rate optimization (CRO) and user experience design, p-hacking refers to the practice—whether intentional or accidental—of manipulating experiment data or analysis methods until a result achieves statistical significance. This phenomenon is often a byproduct of Goodhart’s Law, which posits that when a measure becomes a target, it ceases to be a good measure. For many organizations, the pressure to deliver "winning" experiments has overshadowed the primary objective of experimentation: gaining reliable, actionable insights.

The Statistical Reality of False Discoveries
The scale of p-hacking in the professional testing environment is significant. A landmark 2018 analysis of 2,101 commercially conducted A/B tests revealed that approximately 57% of experimenters engaged in some form of p-hacking once their results approached a 90% confidence level. This behavior has a direct and measurable impact on the False Discovery Rate (FDR) of an experimentation program. At a standard 90% confidence threshold, p-hacking can push the FDR from an expected 33% to a staggering 42%. This implies that nearly half of all reported "wins" in such environments are likely false positives—random noise masquerading as meaningful consumer behavior changes.
Sundar Swaminathan, author of the experiMENTAL Newsletter, characterizes p-hacking as one of the most dangerous pitfalls in modern testing. According to Swaminathan, when testers stop experiments prematurely upon seeing a significant p-value, they are essentially cherry-picking data points that support a pre-existing hypothesis while ignoring the underlying mathematical requirements of the test. This leads to the implementation of changes that provide no real value, eventually undermining the credibility of the entire experimentation department.

The Chronology of Data Manipulation: When P-Hacking Occurs
P-hacking typically enters the experimentation workflow at three distinct stages: during the execution of the test, during the final analysis, and through unintentional procedural errors.
During the experiment phase, the most common form of p-hacking is "peeking." This occurs when a researcher monitors results daily and stops the test the moment the p-value dips below the 0.05 threshold. Because p-values fluctuate naturally as data accumulates, stopping at a temporary low point guarantees a high rate of false positives. Another common mid-test error is the "variant hunt," where researchers add new variations to an active test or extend the duration indefinitely until a winner emerges.
In the post-experiment phase, p-hacking often takes the form of "metric switching" or "selective reporting." If the primary metric (such as checkout completions) fails to show significance, a tester might scan through dozens of secondary metrics (such as "add to cart" or "scroll depth") until they find one that looks positive, then report that as the success of the test. Similarly, post-test segmentation—slicing data by browser, region, or device until a significant result appears in a sub-group—without prior hypothesis leads to "data dredging."
Unintentional p-hacking behaviors often stem from a lack of rigorous setup. Failing to account for the "multiple comparison problem" when testing more than one variant against a control is a frequent culprit. Each additional variant increases the mathematical probability that one will appear to "win" purely by chance.
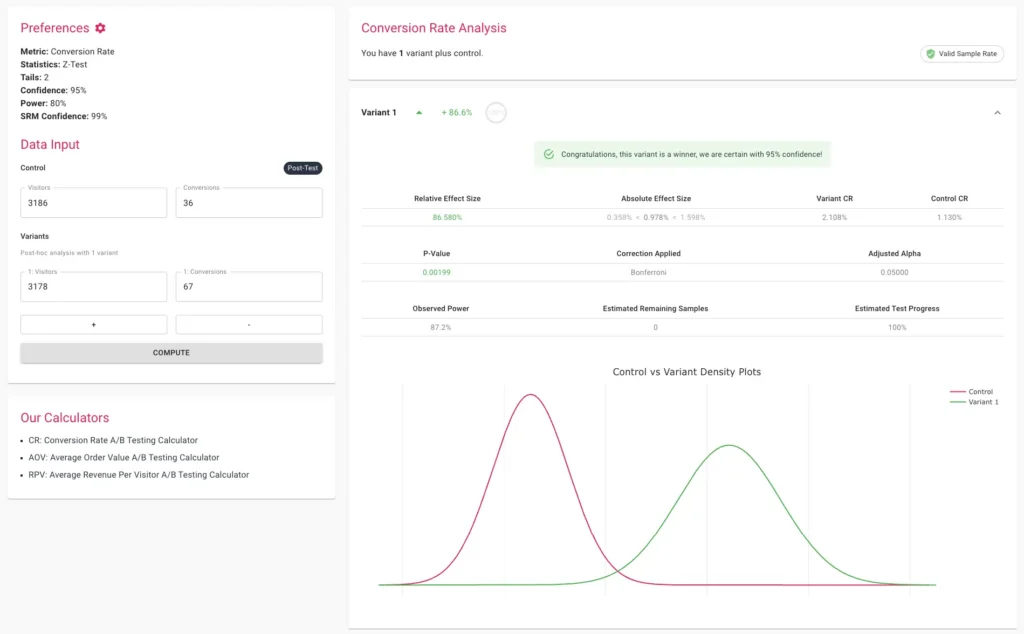
Technical Safeguards: Implementing Statistical Guardrails
To combat these risks, sophisticated experimentation platforms and data scientists are increasingly moving toward a "guardrail-first" approach. This involves establishing rigid parameters before any data is collected.
Pre-Calculation of Sample Size and Duration
The first line of defense is the use of pre-test calculators to determine the required sample size and test duration based on the Minimum Detectable Effect (MDE) and desired statistical power. By committing to a fixed horizon, organizations prevent the "peeking" problem. A test must run until the predetermined sample size is reached, regardless of how promising the interim results appear.
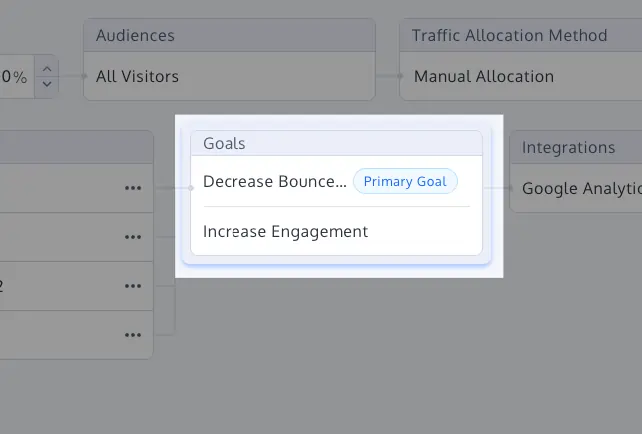
Primary Goal Labeling and Metric Hierarchy
To prevent metric switching, practitioners are encouraged to define a single primary "North Star" metric. All other tracked data points are treated as "guardrails"—metrics intended to ensure that the experiment does not cause harm elsewhere, rather than metrics used to declare a victory.
Multiple Comparison Corrections: Bonferroni and Sidak
When testing multiple variants (A/B/C/D tests), the risk of a Type I error (a false positive) compounds. Statistical corrections like the Bonferroni or Sidak methods adjust the significance threshold. For example, if a researcher tests four variants at a 95% confidence level, the Bonferroni correction would require each variant to meet a much stricter p-value to be considered a true winner. While the Sidak correction is slightly less conservative than Bonferroni, it is often preferred in commercial settings for maintaining better statistical power while still controlling the family-wise error rate.
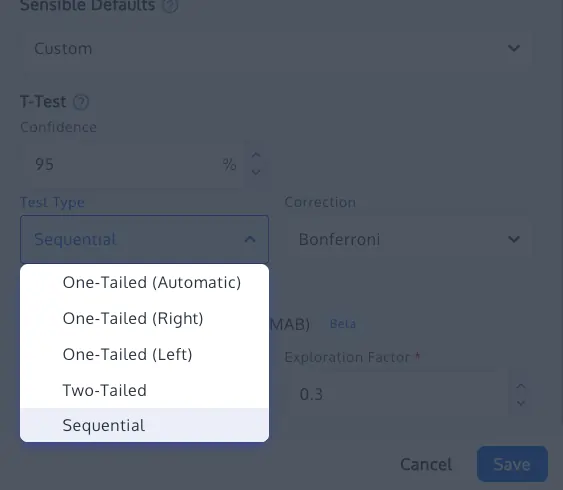
Advanced Methodologies: Sequential Testing and Bayesian Frameworks
As the industry matures, many organizations are adopting sequential testing and Bayesian statistics to balance the need for speed with the requirement for rigor.
Sequential testing allows for continuous monitoring of data without inflating the Type I error rate. Using implementations such as confidence sequences (based on the work of Waudby-Smith et al., 2023), testers can provide "always-valid" inference. This means a test can be stopped early if a result is overwhelmingly positive or negative, provided the mathematical framework specifically accounts for the sequential nature of the data.
Bayesian A/B testing offers a different perspective by focusing on the probability of a variant being better than the control and the "risk" associated with choosing it. While Bayesian methods do not magically eliminate the potential for p-hacking, they provide a more intuitive "Expected Uplift" estimate and "Probability to Outperform," which can be more resilient to the binary "win/loss" pressure that often drives p-hacking in frequentist setups.
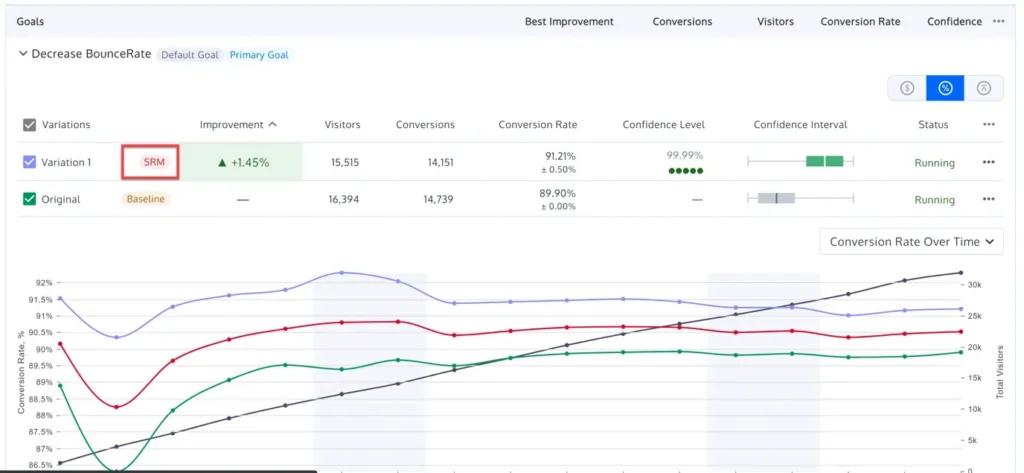
Identifying Broken Experiments: The Role of SRM
Even a perfectly designed test can be compromised by technical failures. A Sample Ratio Mismatch (SRM) occurs when the actual distribution of visitors between the control and variants deviates significantly from the intended split (e.g., a 50/50 split resulting in 48/52).

SRM is often a "canary in the coal mine" for deeper issues such as bot interference, redirect errors, or faulty tracking scripts. High-integrity experimentation programs use Chi-square goodness-of-fit tests to check for SRM automatically. If an SRM is detected, the results of the test are considered fundamentally untrustworthy, regardless of how high the reported "uplift" might be. In such cases, the only valid course of action is to identify the technical bug, fix it, and restart the experiment.
Broader Implications for Corporate Culture and ROI
The prevalence of p-hacking is ultimately a cultural issue as much as a statistical one. In many corporate environments, "velocity" and "win rate" are used as key performance indicators for optimization teams. This creates a perverse incentive structure where researchers feel pressured to produce positive results to justify their budgets.
However, the long-term impact of a p-hacked experimentation program is devastating to a company’s bottom line. When false positives are implemented, engineering resources are wasted on features that do not move the needle. Over time, the cumulative "lift" reported by the experimentation team fails to manifest in the company’s actual financial statements, leading to a "credibility gap."
To build a sustainable experimentation culture, leadership must shift the focus from "finding winners" to "finding truths." A "neutral" result or a "losing" test that provides a clear insight into customer behavior is often more valuable than a p-hacked "winner." By prioritizing statistical integrity through automated guardrails, pre-defined success criteria, and rigorous peer review of test designs, organizations can ensure that their data-driven decisions are actually driven by data, and not by the noise of random chance.