In an era defined by the rapid proliferation of digital content and the increasing sophistication of generative artificial intelligence, the integrity of published information has become a critical concern for journalists, researchers, and corporate communicators alike. As the barrier to content creation continues to lower, the risk of disseminating misinformation—whether through human error or AI “hallucination”—has surged. To address this challenge, experimentation consultant Iqbal Ali has developed a sophisticated automation framework using the n8n platform, designed to streamline the arduous process of verifying claims and documenting sources.

The development of this workflow comes at a time when digital trust is at an all-time low. According to a 2023 report by the Pew Research Center, a significant majority of adults express concern over the impact of misinformation on public discourse. Furthermore, industry analysts at Gartner have predicted that by 2026, the volume of synthetically generated content will necessitate the widespread adoption of automated verification tools to maintain editorial standards. Ali’s approach represents a growing trend in “agentic” workflows, where AI is not merely used to generate text, but to perform complex, multi-step investigative tasks that were previously the sole domain of human researchers.
The Challenge of Manual Verification
For content creators, the traditional process of fact-checking is often reactive rather than proactive. Many professionals utilize a “second brain” methodology—archiving interesting facts and research data in tools like Notion or Obsidian as they encounter them. However, in practice, the transition from a rough draft to a finalized, verified article often reveals gaps in documentation. Writers frequently find themselves retracing their digital steps to locate the original source of a specific statistic or claim, a process that is both time-consuming and prone to distraction.
Ali’s workflow seeks to automate this transition by moving from a rough draft to a documented claim through a series of logical gates: extracting claims, checking numerical accuracy, validating facts against search results, and documenting the final source. By reducing the friction inherent in these steps, the system allows creators to maintain high standards of accuracy without the prohibitive time costs usually associated with deep research.
Technical Architecture and System Integration
The backbone of this automated fact-checking system is n8n, an extendable workflow automation tool that allows for the integration of various APIs and AI models. The architecture is modular, consisting of a primary workflow that triggers five distinct “mini-API” sub-workflows via HTTP requests. This modularity ensures that each component—such as claim extraction or source validation—can be updated or improved independently as technology evolves.

To facilitate the research process, the workflow integrates several high-performance tools:
- Exa (formerly Metaphor): A neural search engine designed specifically for LLMs (Large Language Models) to find high-quality, relevant web content rather than just keyword-matched pages.
- Browserless: A headless browser service used to navigate to specific web pages, bypass anti-scraping measures, and extract raw text content for analysis.
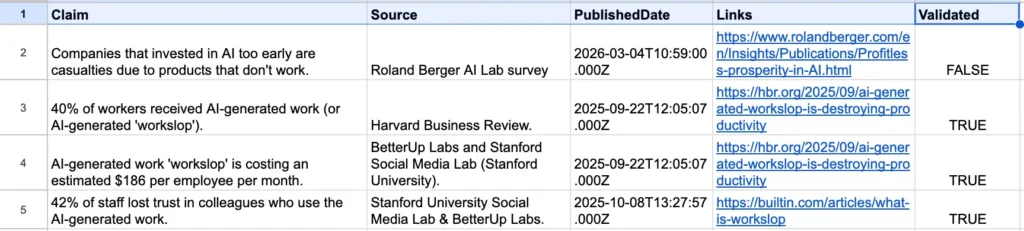
- Google Sheets: Serves as the final repository, where claims are categorized by their source, publication date, relevant links, and validation status.
- LLMs (Gemma and Llama): These models are utilized for natural language processing tasks, including the extraction of concise claims and the evaluation of semantic similarity between claims and source text.
The Five-Stage Chronology of Verification
The workflow operates through a structured chronology, ensuring that every piece of information is scrutinized multiple times before being marked as “validated.”
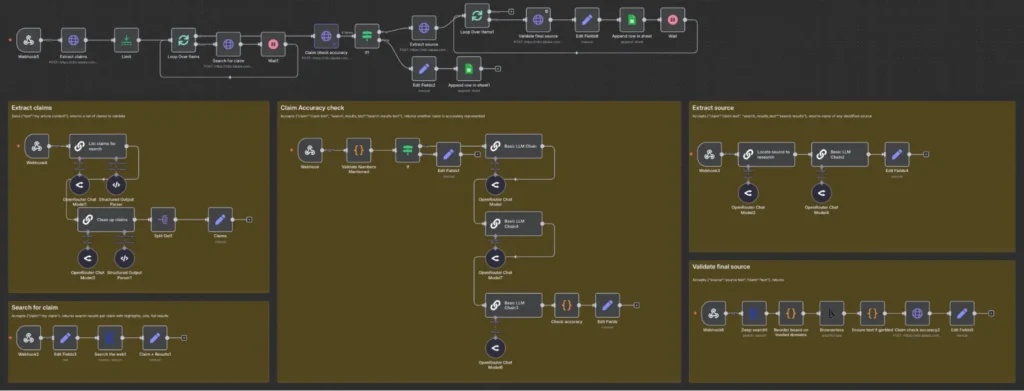
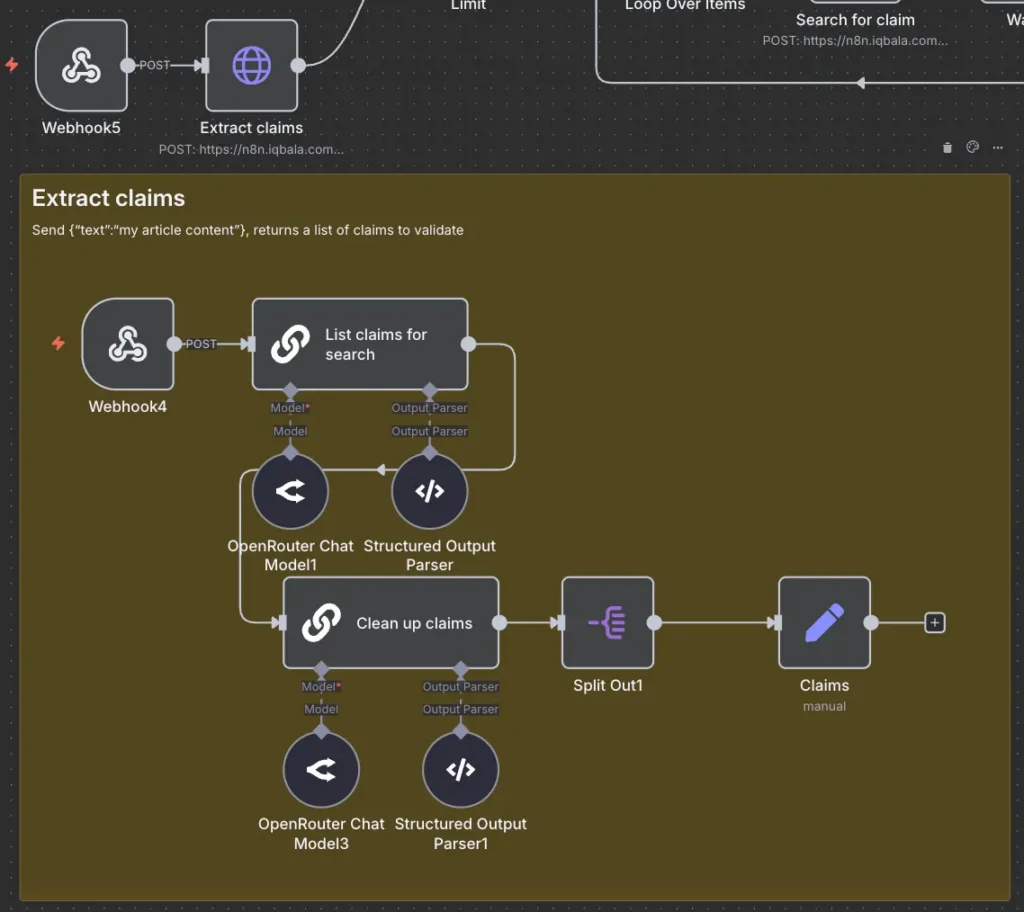
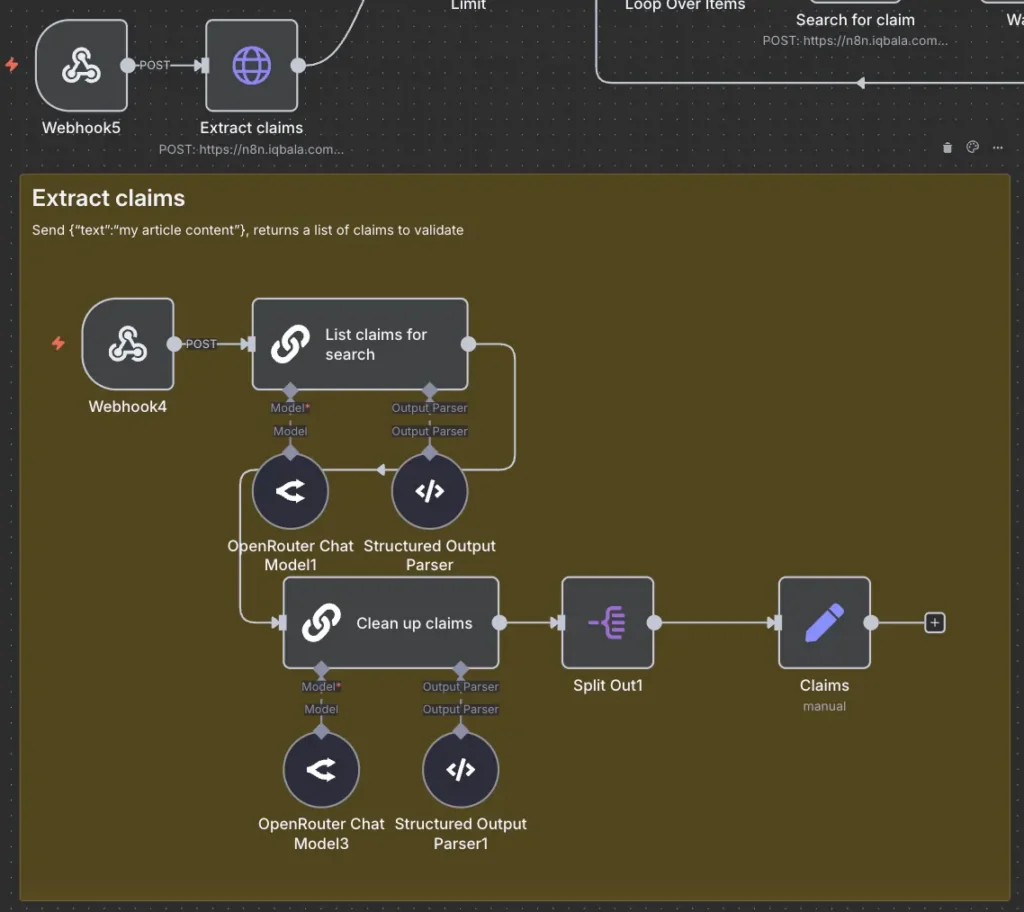
Stage 1: Claim Extraction and Self-Reflection
The process begins when a rough draft is submitted to the system. An AI node identifies every discrete factual assertion within the text. To ensure accuracy at the outset, the system employs a “self-reflection” technique. This involves a second AI pass that verifies whether the extracted claims accurately reflect the original intent of the draft. This iterative prompting has been shown in various studies to significantly reduce initial extraction errors.
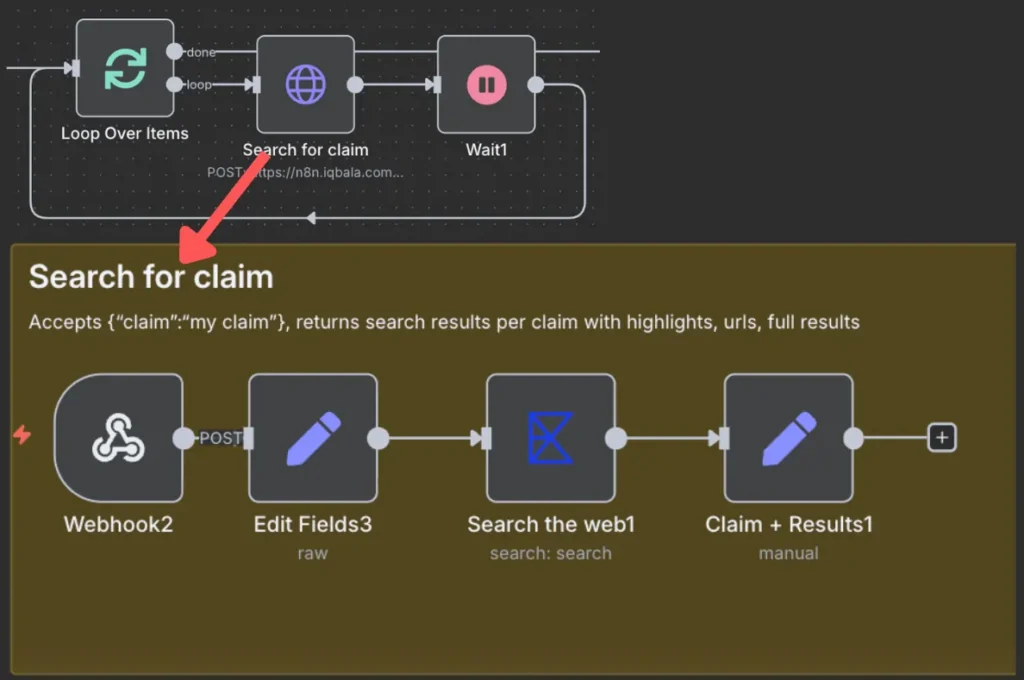
Stage 2: Neural Search and Highlight Retrieval
Once a list of claims is generated, the system utilizes Exa to conduct targeted web searches. Unlike traditional search engines, Exa returns “highlights”—specific snippets of text that the engine deems most relevant to the query. To manage API rate limits on free-tier accounts, the workflow incorporates a batching logic, processing claims in groups of ten with built-in delays to ensure consistent service delivery.
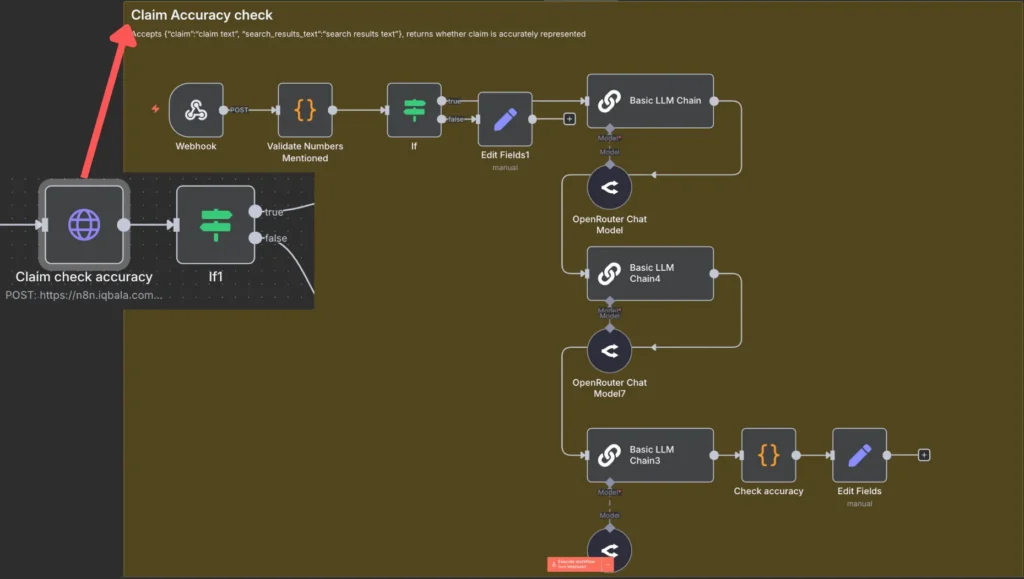
Stage 3: The Accuracy Check (Best-of-Three Logic)
The most critical phase involves comparing the extracted claims against the search highlights. Ali’s workflow employs a “best-of-three” approach to mitigate the non-deterministic nature of AI. The system runs the accuracy check three times; if a claim is validated in at least two of the three passes, it proceeds to the next stage. If the system cannot find a match, it marks the claim as “Validated: FALSE” in the spreadsheet, signaling to the human editor that further manual investigation is required.
Stage 4: Source Extraction and Refinement
For claims that pass the initial accuracy check, the system identifies the specific URL and publication details of the source. A secondary AI node then rewrites the source description to be more concise, ensuring that the final spreadsheet is easy to navigate and professional in appearance.
Stage 5: Primary Source Validation and Trusted Domains
The final stage addresses the risk of “AI circularity”—where AI models cite other AI-generated content that may be incorrect. The workflow filters results based on a list of trusted domains (e.g., academic journals, government databases, or reputable news outlets). The Browserless node then performs a “deep dive,” scraping the full text of the most trusted page to perform one final accuracy check. This ensures that the claim is supported not just by a snippet, but by the full context of a primary source.
Supporting Data and Implications for Accuracy
The necessity for such systems is underscored by data regarding the “hallucination rate” of modern LLMs. Research from various AI safety labs suggests that even top-tier models can produce factual errors in 3% to 10% of generated content, depending on the complexity of the topic. By introducing deterministic elements—such as code-based domain filtering and multi-pass validation—the n8n workflow acts as a “sanity check” that balances the speed of AI with the rigor of traditional journalism.
Furthermore, the automation of these tasks offers significant efficiency gains. A manual fact-check of a 1,000-word article can take a human researcher anywhere from two to five hours, depending on the density of the claims. Ali’s workflow can process dozens of claims in a matter of minutes, though the author notes that “Browserless is super rate-limited,” necessitating a patient approach to the final scraping phase.
Broader Impact on the Content Industry
The implications of this technology extend beyond individual LinkedIn posts or blog articles. In the broader media landscape, the ability to automate the “first pass” of fact-checking could prove transformative for small newsrooms and independent journalists who lack the resources of major fact-checking departments like those at The New York Times or Reuters.
However, the creator emphasizes that this is a “human-in-the-loop” system. The automated output is intended to reduce friction, not to replace the final editorial judgment of a human being. The “Validated: FALSE” flag is perhaps the most important feature, as it identifies exactly where the human mind needs to focus its attention, thereby optimizing the relationship between human intuition and machine processing power.
Official Responses and Future Outlook
While there have been no official statements from the platforms integrated (n8n, Exa, or Browserless) regarding this specific workflow, the trend toward “verifiable AI” is a major focus for the industry. Developers are increasingly moving away from “black box” AI models toward Retrieval-Augmented Generation (RAG) systems, which prioritize the sourcing of information from external, verifiable databases.
Iqbal Ali has made the workflow available for public download, inviting the community to adapt and improve the logic. Future iterations of the tool are expected to include more deterministic semantic similarity checks and expanded databases of trusted domains. As the digital landscape continues to grapple with the challenges of the information age, tools like this n8n workflow represent a vital step toward a more accountable and accurate internet.
The project serves as a practical blueprint for how professionals can navigate the complexities of modern content creation. By combining low-code automation with advanced AI, creators can uphold the principles of accuracy and transparency, ensuring that even in an era of “fake news,” the truth remains accessible and documented.