The landscape of digital marketing is currently undergoing a silent but profound crisis regarding the scientific integrity of its most fundamental tool: the A/B test. While modern marketing technology allows for the rapid deployment of randomized controlled trials (RCTs) at a scale previously unimaginable in traditional scientific fields, the statistical methodologies governing these experiments have largely failed to keep pace. Industry experts and data scientists warn that the common advice found in A/B testing literature is lagging behind modern statistical science by nearly half a century. This discrepancy is not merely academic; it results in billions of dollars in wasted resources, missed opportunities, and the implementation of business strategies based on illusory data.
At its core, an A/B test is a scientific experiment designed to establish a causal relationship between a specific change—such as a new website layout or a different checkout flow—and a measurable outcome, like conversion rate. However, the widespread misuse of classical statistical significance tests, a lack of consideration for statistical power, and general inefficiencies in testing protocols have created a "Garbage In, Garbage Out" (GIGO) cycle in many conversion rate optimization (CRO) departments. In response to these systemic failures, a new framework known as the AGILE statistical approach is being proposed, drawing inspiration from the rigorous protocols of clinical trials to modernize digital experimentation.
The Structural Flaws of Traditional Statistical Significance
In the current digital marketing ecosystem, the term "statistical significance" is often used as a synonym for "truth," yet its application frequently violates the very mathematical assumptions upon which it was built. Most practitioners rely on classical tests, such as the Student’s T-test, which were designed for fixed-sample experimentation. These models assume that a researcher will determine a sample size in advance, collect that specific amount of data, and perform a single evaluation at a lone point in time.
The reality of business operations, however, stands in direct opposition to this requirement. In a high-pressure corporate environment, stakeholders naturally want to monitor results as they accrue. This leads to the pervasive issue of "data peeking" or data-driven optional stopping. When a marketing team observes a high confidence level after only a few days of a month-long test and decides to "call the winner" early, they are unknowingly inflating their error rates.
Statistical data indicates that peeking at results just twice during an experiment can more than double the actual error rate compared to the reported nominal error. If a practitioner peeks five times, the actual probability of a false positive is 3.2 times larger than reported; peeking ten times results in an error rate five times larger than the nominal 5% threshold. This phenomenon occurs because peeking introduces an additional dimension to the test’s sample space. Rather than estimating the probability of a false detection at a single point, the test must account for the probability of a false detection at multiple points across a fluctuating data stream. Without adjusting for these multiple looks, the resulting "significance" is often a statistical mirage caused by natural variance in the data.
The Invisible Threat of Under-Powered Experiments
While false positives (Type I errors) represent the danger of implementing changes that don’t work, the lack of statistical power (Type II errors) represents the danger of missing out on genuine improvements. Statistical power is defined as the probability that a test will detect a true effect of a certain size if one actually exists. Despite its importance, a review of influential A/B testing literature published over the last decade reveals a startling omission: the vast majority of resources fail to mention statistical power entirely or treat it with superficial brevity.
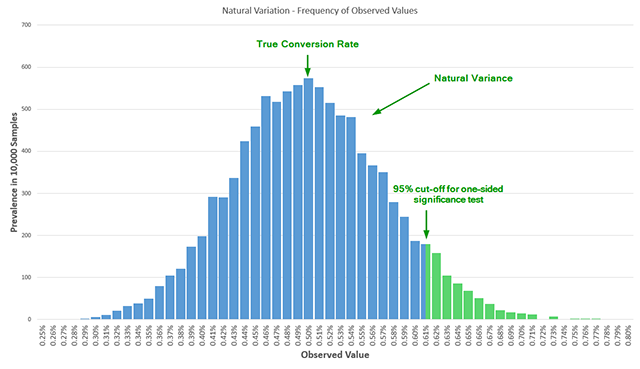
Running an under-powered test is akin to using a low-resolution microscope to look for a specific bacterium; if you don’t find it, you cannot be sure if it isn’t there or if your tool simply wasn’t sensitive enough to see it. Many free statistical calculators used by practitioners operate at a default power of 50%, which is essentially the equivalent of a coin toss. This lack of sensitivity means that even if a new variant is significantly better than the control, the test may return a "non-significant" result.
The consequences of low power are twofold. First, it leads to the abandonment of potentially lucrative ideas, as a "false negative" is often misinterpreted as proof that a certain direction is not viable. Second, it leads to immense operational waste. Teams may spend weeks designing and coding a variant, only to subject it to a test that never had a realistic chance of validating its success. To run a mathematically sound test, practitioners must balance four variables: the historical baseline conversion rate, the desired significance threshold (usually 95%), the desired power (usually 80% or 90%), and the minimum effect size of interest (MDE).
Historical Context: From Agriculture to the Digital Frontline
To understand why A/B testing has reached this impasse, one must look at the chronology of experimental design. The foundations of modern statistics were laid in the early 20th century by figures like Ronald A. Fisher, primarily for use in agriculture and biology. In these fields, data collection was slow—growing a crop takes a full season—making a single, fixed-point analysis logical and necessary.
However, as experimentation moved into the medical field in the mid-20th century, ethical and financial pressures necessitated a change. In clinical trials, if a new drug is showing overwhelming evidence of saving lives, it is unethical to continue giving the control group a placebo until the pre-set sample size is reached. Conversely, if a drug is showing toxic side effects, the trial must be stopped immediately. This led to the development of Group Sequential Designs and "error-spending functions" in the 1960s and 70s.
Digital marketing currently finds itself in a position similar to 1960s medicine. The speed of data accrual is high, and the financial stakes of continuing a losing test—or delaying a winning one—are significant. Yet, the industry has largely remained stuck in the Fisherian agricultural model of the 1920s. The AGILE method represents the bridge between these two eras, bringing the sophistication of 21st-century bio-statistics to the world of e-commerce and digital product development.
The AGILE Statistical Method: A New Standard for CRO
The AGILE statistical method is a specialized framework designed to align the mathematical rigor of randomized controlled trials with the practical realities of the digital business cycle. It addresses the three primary flaws of classical testing—misuse of significance, lack of power, and general inefficiency—through a structured, multi-stage approach.
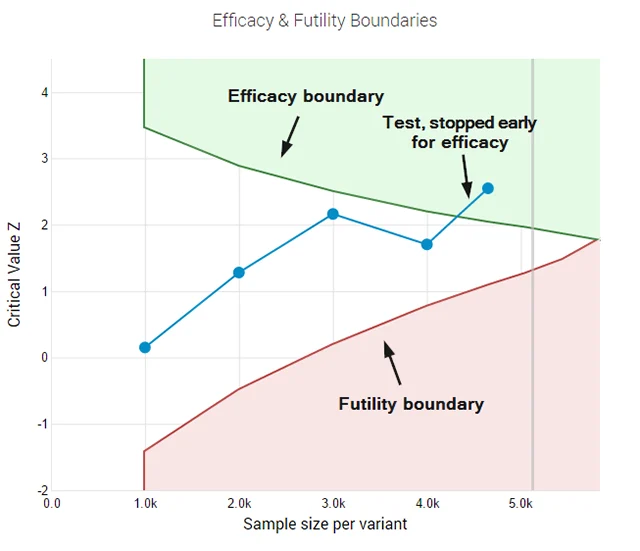
The cornerstone of the AGILE method is the use of error-spending functions. This mathematical technique allows for interim analyses of data while maintaining strict control over the total false-positive rate. Essentially, it "allocates" a portion of the allowable error to each "peek" or interim check. If a result is so extreme that it exceeds the adjusted threshold early on, the test can be stopped for efficacy with full statistical confidence.
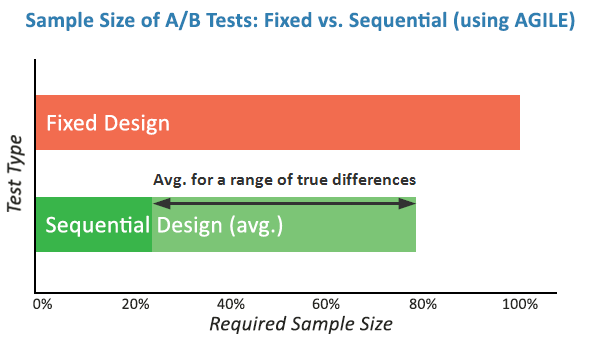
Furthermore, AGILE incorporates a "futility stopping rule." This is perhaps the most significant efficiency gain for business operations. A futility rule allows a practitioner to abandon a test that has a mathematically negligible chance of reaching significance before the sample size is exhausted. In traditional testing, a team must wait until the end of the test to declare a "neutral" result. With AGILE, they can "fail fast," cutting losses on stagnant variants and redirecting traffic and engineering resources to more promising hypotheses.
Simulations of the AGILE framework demonstrate efficiency gains ranging from 20% to 80% in terms of sample size requirements. By allowing for early stopping in both highly successful and highly unsuccessful variants, the method ensures that the majority of the testing "budget" (user traffic) is spent on the most ambiguous cases where data is truly needed.
Broader Impact and Economic Implications
The shift toward more robust statistical methods like AGILE has profound implications for the broader tech industry. As the cost of customer acquisition continues to rise across digital channels, the ability to accurately and efficiently optimize conversion rates becomes a primary competitive advantage.
Companies that rely on flawed statistical models face a hidden "innovation tax." This tax is paid in the form of implemented features that actually hurt the user experience but were flagged as "winners" due to inflated error rates, and in the form of missed revenue from "losers" that were actually winners. Moreover, the psychological impact on product teams cannot be overstated; a culture of experimentation that frequently produces contradictory or unreplicable results leads to skepticism and the eventual abandonment of data-driven decision-making in favor of "HiPPO" (Highest Paid Person’s Opinion) directed strategies.
The transition to AGILE and similar sequential testing methods also signals a maturation of the Data Science role within marketing. It moves the practitioner from being a mere reporter of "p-values" to an architect of experimental strategy. By requiring the explicit definition of power and MDE, the AGILE method forces business stakeholders to quantify their goals and risk tolerance before a test begins, leading to better-aligned organizational objectives.
Future Outlook: The Automation of Rigor
As the industry looks forward, the integration of AGILE principles into automated testing platforms appears inevitable. The complexity of calculating error-spending functions and adjusted significance thresholds is a barrier to manual adoption for many small teams. However, as these methodologies are baked into the backend of testing tools, the "standard" for digital experimentation will rise.
The ultimate goal of this evolution is to create a testing environment where speed does not come at the expense of accuracy. By adopting the lessons learned from decades of clinical research, digital marketers can finally transform A/B testing from a misinterpreted marketing tactic into a reliable scientific discipline. The AGILE method provides the roadmap for this transformation, ensuring that the next generation of digital growth is built on a foundation of mathematical certainty rather than statistical convenience.