The transition from intuition-based decision-making to data-driven experimentation has defined the last decade of digital commerce, yet many organizations have found themselves trapped in a cycle of diminishing returns. What begins as a strategic effort to reduce guesswork often evolves into a narrow dependence on A/B testing, where teams prioritize incremental UI tweaks over substantive business improvements. While A/B testing remains a foundational tool for conversion rate optimization (CRO), industry experts and data analysts increasingly warn that an over-reliance on this single methodology signals a lack of institutional maturity, often masking deeper systemic issues within a product’s user experience or business model.
The Genesis of the A/B Testing Default
The ascent of A/B testing as the primary mechanism for digital decision-making was driven by its accessibility and the visible successes of early adopters. In the early 2010s, experimentation platforms like FigPii and Optimizely democratized data science, allowing marketing and product teams to launch variants without deep statistical expertise. This convenience fostered a corporate culture where “experimentation” became synonymous with “running a split test,” regardless of whether a split test was the appropriate diagnostic tool for the problem at hand.

Historical precedents from major technology firms further cemented this mindset. One of the most cited examples in the industry involves Microsoft’s Bing team, which tested a specific change to ad display logic. By merging two ad title lines into a single, longer headline, the team observed a click-through rate increase significant enough to generate an additional $100 million in annual revenue. Success stories of this magnitude encouraged a “test everything” philosophy, leading Microsoft to scale its experimentation program to over 20,000 controlled experiments annually. However, for the average e-commerce brand, the attempt to replicate this high-velocity testing environment often leads to a phenomenon known as “local maximum” syndrome—optimizing a specific feature to its limit while ignoring the fact that the entire page or strategy may be fundamentally flawed.
The Statistical Reality of Traffic Constraints
A primary driver of failed experimentation programs is a fundamental misunderstanding of statistical power. Reliable A/B testing requires a high volume of traffic and conversions to distinguish true behavioral shifts from random “noise.” For an experiment to detect a small lift—such as a 1% or 2% increase in conversion—a site typically requires hundreds of thousands of visitors per variant.
Most mid-market e-commerce brands do not possess the traffic necessary to reach statistical significance within a reasonable timeframe. Data indicates that even brands generating one to two million sessions per month struggle to validate minor UI changes. This lack of power leads to three common failure modes in CRO programs:
- The Infinite Test: Experiments run for months without reaching significance, paralyzing the development roadmap.
- False Positives: Teams declare a “winner” based on a temporary spike in data, only to find that the lift does not translate to long-term revenue.
- The Flatline: A series of inconclusive tests leads leadership to believe that experimentation is ineffective, resulting in budget cuts for research and development.
Beyond the “What”: The Diagnostic Gap and Survivorship Bias
A/B testing is designed to answer “what” happened, but it is notoriously poor at explaining “why” it happened. A variant may win because it genuinely improved user confidence, or it may win because it introduced a “dark pattern” that coerced a short-term action at the expense of long-term trust.
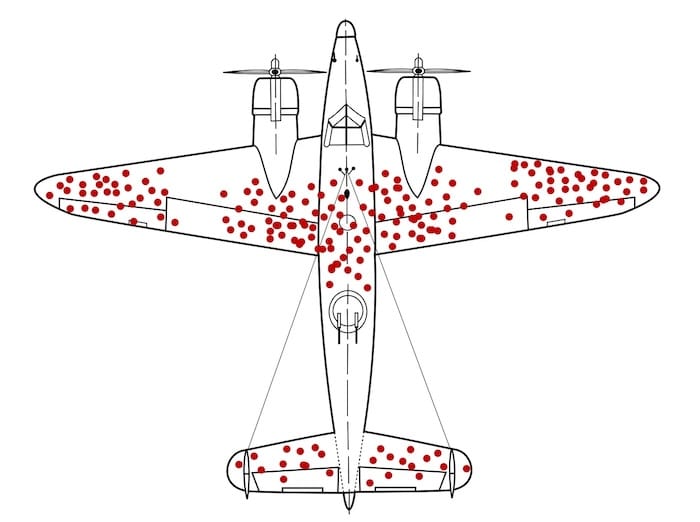
This creates a dangerous blind spot similar to the classic World War II survivorship bias observed by statistician Abraham Wald. When the military analyzed returning aircraft to determine where to add armor, they initially looked at where the bullet holes were located. Wald pointed out that they were only seeing the planes that survived; the planes hit in the engines or cockpit never returned to be analyzed. Similarly, A/B tests focus on the “survivors”—the users who stayed in the funnel. They often fail to capture the insights of the users who bounced entirely. A test result might show that “Variant B” increased add-to-cart rates, but it won’t reveal if those same users abandoned the checkout later because the variant set unrealistic expectations about shipping or product quality.
The Conflict Between Short-Term Uplift and Long-Term Value
In the pursuit of immediate “wins,” many teams prioritize metrics that are easy to move but decoupled from actual business health. Research into experimentation trends shows that over 90% of tests focus on five primary metrics: CTA clicks, revenue per session, checkout starts, registrations, and add-to-cart actions. Clicks alone account for nearly 35% of all primary experiment goals.

However, high-maturity teams recognize that short-term lifts often clash with long-term profitability. The “Choice Overload” effect, famously illustrated by the “Jam Experiment,” serves as a cautionary tale. In that study, a display with 24 varieties of jam attracted more interest than a display with six, but the smaller selection led to a purchase rate ten times higher. In a modern e-commerce context, a variant that adds more “recommended products” to a cart page might increase click-through rates (a short-term win) but actually decrease total completed purchases by distracting the user during a critical decision moment.
Characteristics of High-Maturity Experimentation Programs
Organizations that successfully move beyond basic A/B testing adopt a more diversified and research-heavy approach. This evolution is characterized by three strategic shifts:
1. Diversification of the Experimentation Toolkit
Mature teams do not force every question into a binary split test. Instead, they match the methodology to the complexity of the problem:
- Sequential Testing: Used for long-term tracking of subscription retention or repeat purchase behavior.
- Holdout Groups: A small percentage of users is kept away from a new feature for months to measure its true cumulative impact on Customer Lifetime Value (CLV).
- Switchback Tests: Common in marketplaces (like Uber or DoorDash), these tests alternate treatments over time across entire regions to prevent “network interference” where one user’s experience affects another’s.
- Quasi-Experiments: Used when random assignment is impossible or unethical, such as testing the impact of a new pricing tier across different geographic markets.
2. Evidence-Led Hypothesis Development
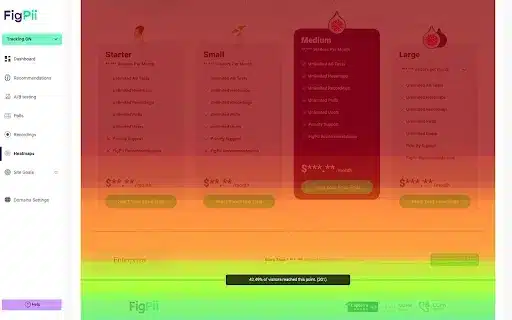
Rather than testing “random ideas,” mature programs ground every experiment in qualitative and quantitative research. This includes analyzing heatmaps, session recordings, customer support tickets, and exit surveys. A high-quality hypothesis follows a rigorous structure: “Because we observed [Evidence], we believe that [Specific User Problem] exists; therefore, we will [Change], and we expect [Metric] to improve for [Segment].”
3. Testing “Big Levers” Over Micro-Tweaks
High-impact programs focus on the core drivers of human behavior: motivation, trust, and perceived value. Instead of testing button colors, they test:
- Value Propositions: How the brand’s unique benefits are communicated.
- Pricing Psychology: The impact of bundling, tiered pricing, or “free shipping” thresholds.
- Information Architecture: How users navigate complex product catalogs.
- Social Proof: The placement and type of reviews or expert endorsements.
Analysis of Implications: The Future of CRO
The shift away from obsessive A/B testing toward “Holistic Experimentation” represents a professionalization of the digital marketing industry. As privacy regulations like GDPR and CCPA make user tracking more difficult and third-party cookies disappear, the “brute force” method of running thousands of micro-tests is becoming less viable.

Furthermore, the rise of Artificial Intelligence and Machine Learning in CRO is automating the “small wins.” Tools can now automatically optimize headlines or layouts in real-time. This leaves human teams with the more important task of strategic experimentation—identifying the “why” behind consumer behavior and building experiences that foster long-term loyalty rather than just one-time clicks.
For businesses looking to scale, the path forward involves a paradox: to get better results from data, they must spend more time talking to customers. The most successful experimentation programs of the next decade will be those that use A/B testing not as a crutch for decision-making, but as a final validation step for deeply researched, customer-centric strategies. By focusing on “big levers” and long-term business outcomes, e-commerce brands can break out of the cycle of incrementalism and achieve the transformative growth that simple A/B testing often promises but rarely delivers.