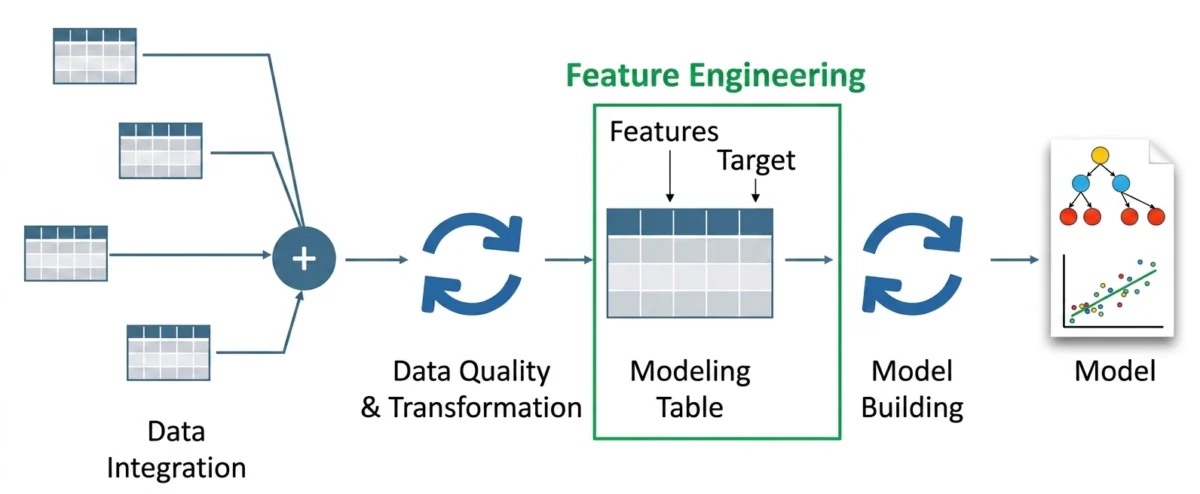
Feature engineering has long been recognized as the most critical yet labor-intensive phase of the machine learning lifecycle. For decades, data scientists have relied on manual transformations—such as one-hot encoding, scaling, and the creation of interaction terms—to convert raw data into a format that algorithms can digest. However, the rise of Large Language Models (LLMs) is fundamentally altering this landscape. By leveraging the semantic depth and contextual awareness of models like GPT-4, Llama, and FLAN-T5, organizations are now able to automate the extraction of complex features from unstructured data, moving beyond simple statistical patterns toward a deeper understanding of human intent and nuance.
The Technological Evolution: From Statistics to Semantics
The history of feature engineering is characterized by a gradual shift from human-defined rules to automated representation learning. In the early 2000s, traditional natural language processing (NLP) relied on techniques like Term Frequency-Inverse Document Frequency (TF-IDF) and Bag-of-Words (BoW). While these methods were computationally efficient, they treated words as isolated units, failing to capture the relationship between synonyms or the sentiment behind a phrase. For instance, a traditional model might struggle to realize that "the battery dies quickly" and "the power cell has a short lifespan" describe the same technical issue.
The 2017 publication of the "Attention Is All You Need" paper by Google researchers introduced the Transformer architecture, which serves as the backbone for modern LLMs. This marked a pivotal moment in the chronology of artificial intelligence. Unlike previous models, Transformers use self-attention mechanisms to weigh the significance of different words in a sentence simultaneously. This capability allows LLMs to generate "embeddings"—dense, high-dimensional vectors that represent the semantic meaning of text. In the context of feature engineering, this means that instead of a sparse matrix of word counts, a machine learning model can now receive a 384-dimensional or 1,536-dimensional vector that encapsulates the "essence" of a user review or a support ticket.
Core Methodologies in LLM-Driven Feature Engineering
The integration of LLMs into feature pipelines generally follows three primary technical paths: the generation of semantic embeddings, structured information extraction, and context-aware label generation.
1. Semantic Embeddings as Input Features
The most direct application involves using pretrained transformer models to convert text into numeric features. By using libraries such as Sentence-Transformers, engineers can map sentences into a continuous vector space where similar meanings are positioned closely together. For example, applying a model like all-MiniLM-L6-v2 to a dataset of product reviews allows the system to recognize that "I love machine learning" and "The movie was fantastic" are both positive expressions, even though they share no common vocabulary. This technique effectively solves the "polysemy" problem, where a single word has multiple meanings depending on its surroundings.

2. Automated Structured Extraction
LLMs excel at "zero-shot" or "few-shot" learning, where they can perform tasks without specific training for that task. In feature engineering, this is utilized to extract structured data from messy, unstructured logs or customer interactions. By prompting an LLM to "Extract sentiment, product issue, and urgency from the following text," engineers can transform a paragraph of text into a structured JSON object. These extracted attributes—such as a binary sentiment score or a categorical "urgency" label—can then be fed into traditional classifiers like Logistic Regression or Random Forests. This process essentially turns the LLM into an automated data labeling agent, drastically reducing the need for manual annotation.
3. Semantic Feature Generation and User Intent
Beyond mere extraction, LLMs can synthesize new information. By analyzing a customer’s purchase history and their written feedback, an LLM can infer a "user intent" feature. A customer who writes, "Great camera quality but battery drains fast," might be assigned a feature label of "photography-focused/battery-conscious." This level of granular categorization was previously impossible without extensive domain expertise and complex, fragile rule-based systems.
The Rise of Hybrid Feature Spaces
Industry analysts point out that the most effective modern AI systems are rarely "LLM-only." Instead, they utilize hybrid feature spaces that combine traditional tabular data with semantic LLM outputs. In a real-world scenario, such as predicting customer churn for a telecommunications company, the model would integrate:
- Tabular Data: Monthly billing amount, tenure, and number of dropped calls.
- Semantic Data: Embeddings from the customer’s last five interactions with support agents.
- Extracted Features: A "frustration index" generated by an LLM based on the tone of the customer’s emails.
By concatenating these diverse data types into a single vector, data scientists can build multi-modal pipelines that outperform models relying on numeric data alone. Research suggests that incorporating text-based semantic features can improve model accuracy by 15% to 30% in sectors where customer sentiment is a primary driver of behavior.
Real-World Applications and Industry Impact
The practical implications of this shift are being felt across several major industries:
- E-commerce and Retail: Companies are using LLMs to categorize millions of products based on descriptions and user reviews. This allows for more sophisticated recommendation engines that understand the "vibe" of a product rather than just its category.
- Financial Services: In credit scoring, LLMs can analyze the "purpose of loan" text fields to identify risk factors that are not captured in a standard credit report. They are also used in fraud detection to analyze the narrative patterns in suspicious transaction reports.
- Healthcare: Medical researchers use LLMs to extract features from clinical notes and pathology reports. By turning narrative descriptions of symptoms into structured features, they can better predict patient outcomes and identify potential candidates for clinical trials.
Challenges: Cost, Latency, and the "Black Box" Problem
Despite the clear advantages, the adoption of LLMs in feature engineering is not without significant hurdles. Technical leads at major tech firms have raised concerns regarding the "three pillars of risk": cost, latency, and interpretability.
Cost and Scalability: Generating embeddings for millions of rows of data can be computationally expensive. While open-source models can be hosted locally, the infrastructure required to run high-performance inference at scale involves significant investment in GPU resources.
Latency in Production: Traditional features can be calculated in microseconds. In contrast, calling an LLM—especially via an API—can take hundreds of milliseconds or even seconds. This makes real-time feature engineering with LLMs challenging for applications like high-frequency trading or real-time ad bidding.
The Interpretability Gap: Traditional features like "age" or "income" are easily understood by human stakeholders. LLM embeddings, however, are essentially black boxes. If a model denies a loan based on a 384-dimensional vector, explaining the reasoning to a regulator or a customer becomes a complex legal and technical challenge.
Future Outlook and Strategic Implications
As the field matures, the focus is shifting toward "Small Language Models" (SLMs) and distilled versions of larger architectures. These smaller models offer a middle ground, providing high-quality semantic features with much lower latency and cost. Furthermore, the development of "Vector Databases" like Pinecone and Milvus has provided the necessary infrastructure to store and query these semantic features efficiently.
The consensus among AI researchers is that we are entering an era of "Agentic Feature Engineering." In this future, AI agents will not only extract features but will also autonomously evaluate which features are most predictive, iterating on their own prompts to refine the data pipeline. This reduces the role of the data scientist in the "janitorial" aspects of data prep, allowing them to focus on high-level strategy and model ethics.
In conclusion, the integration of LLMs into feature engineering represents a fundamental shift in how we approach machine learning. By bridging the gap between raw unstructured text and structured mathematical models, LLMs have unlocked a new dimension of data intelligence. While challenges regarding cost and interpretability remain, the ability to capture human-like understanding in a machine-readable format is a breakthrough that will define the next decade of artificial intelligence development. Organizations that fail to adopt these semantic techniques risk falling behind in a market where the depth of data understanding is the ultimate competitive advantage.