On April 21, 2026, Google officially expanded its generative AI ecosystem with the launch of Deep Research Max, a sophisticated autonomous research agent powered by the Gemini 3.1 Pro model. This release represents a fundamental shift in AI utility, moving beyond the conversational "chatbot" paradigm toward a "stateful agent" architecture capable of executing complex, multi-step cognitive tasks with minimal human intervention. Unlike traditional large language models (LLMs) that generate immediate responses based on existing training data, Deep Research Max is designed to plan, browse the live web, ingest private documentation, reason through contradictory information, and produce comprehensive, cited reports through a single API call.
The Evolution of Google’s Research Agents
The trajectory of Google’s research capabilities has been rapid. In December 2025, the company introduced its initial "Deep Research" tool, which offered basic summarization and limited web-search capabilities. While groundbreaking at the time, that version was restricted by its inability to process private data, lack of visual outputs, and a reliance on external integrations for charting and data visualization.
The April 2026 launch of Deep Research Max addresses these limitations by leveraging the Gemini 3.1 Pro architecture. This new model has demonstrated significant gains in reasoning benchmarks, most notably scoring 77.1% on the ARC-AGI-2 (Abstraction and Reasoning Corpus). This score is more than double the performance of the previous Gemini 3 Pro model, signaling a major leap toward Artificial General Intelligence (AGI) in specialized research domains. The "Max" designation refers to the agent’s expanded capacity for depth, allowing it to handle nearly four times the input tokens per task compared to the standard version.
Comparative Analysis: Deep Research vs. Deep Research Max
Google has positioned Deep Research Max as the high-tier alternative to its standard Deep Research agent. While both utilize the new Gemini 3.1 Pro backend, they are optimized for different operational workflows. Developers and enterprise architects must choose between these agents based on the trade-off between latency and comprehensiveness.

The standard Deep Research agent is optimized for speed and interactive user interfaces. It typically completes tasks within five to ten minutes, making it suitable for real-time dashboards or rapid inquiry tools. It executes approximately 80 search queries per task and can process roughly 250,000 input tokens.
In contrast, Deep Research Max is designed for "overnight" batch processing and high-stakes due diligence. It doubles the search capacity to approximately 160 queries and expands the input window to 900,000 tokens. This allows the agent to read hundreds of pages of web content and private PDFs before synthesizing a final report. The completion time for a "Max" task ranges from 10 to 20 minutes, with a higher cost per task—estimated between $3 and $5—reflecting the intense computational resources required for such deep synthesis.
Technical Architecture and the Interactions API
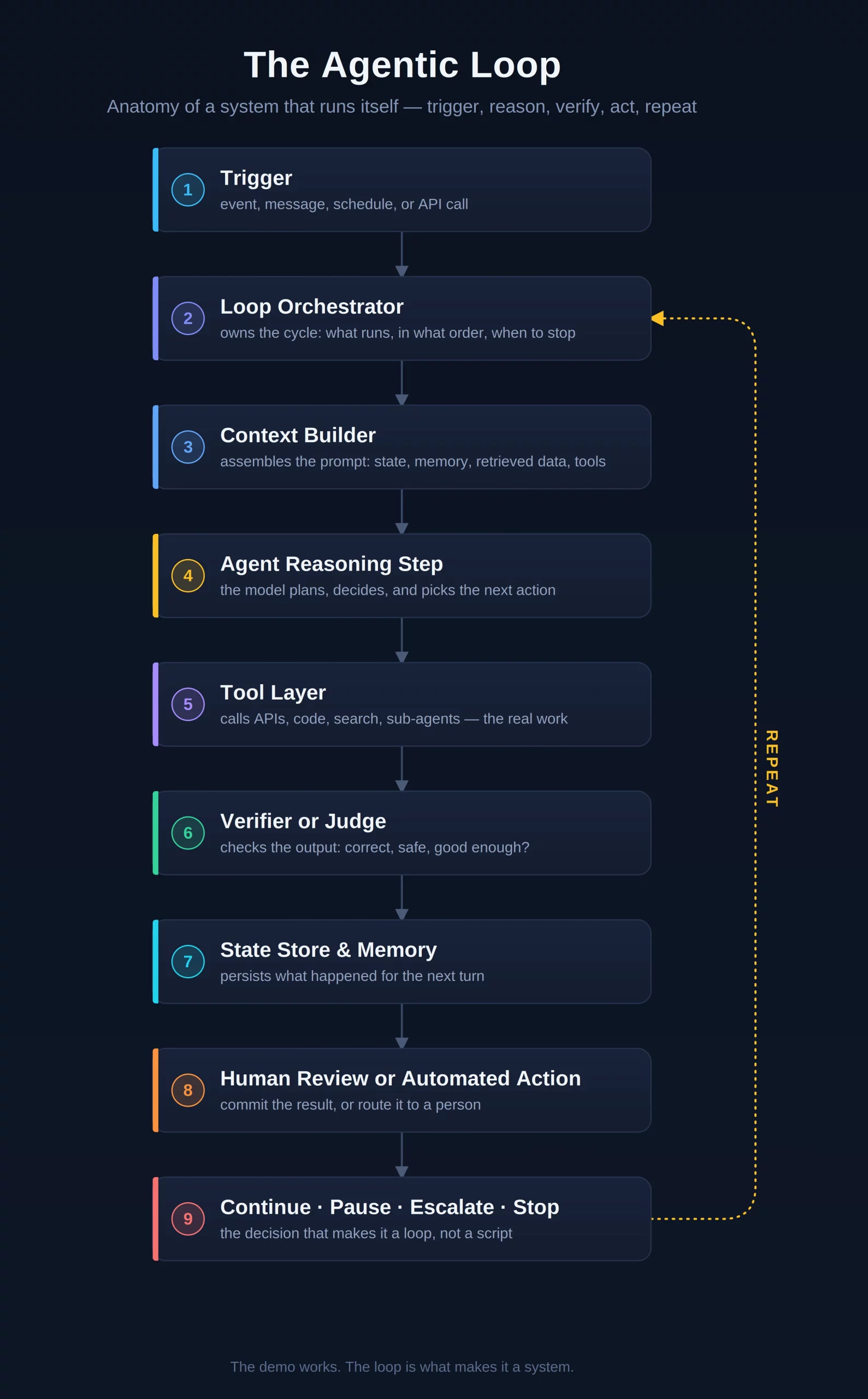
A significant technical departure in this release is the move away from the traditional generate_content endpoint. Deep Research Max operates exclusively through the Interactions API, a stateful framework designed for long-running background tasks.
In a standard LLM request, the connection remains open while the model streams a response. However, because a deep research task can take 20 minutes, a synchronous connection is impractical. The Interactions API allows a developer to submit a prompt and receive an Interaction ID. The agent then operates independently in the cloud, managing its own "state." This includes maintaining a research log, tracking which websites have been visited, and storing intermediate findings in a temporary memory buffer.
When a user submits a prompt, the system follows a specific internal logic:

- Decomposition: The agent breaks the primary prompt into sub-questions.
- Strategy Formulation: It creates a prioritized list of search queries and document reviews.
- Execution: The agent navigates the web, bypasses irrelevant content, and extracts data from primary sources.
- Synthesis: It reconciles data points, identifies trends, and builds a structured report.
- Verification: The agent cross-references its own claims against the gathered sources to ensure every statement has a corresponding citation.
Implementation Guide for Developers
To integrate Deep Research Max into existing workflows, developers must utilize the Google GenAI Python SDK. The setup process involves three primary steps: authentication, environment configuration, and the implementation of a polling loop.
1. Environment Setup
The system requires a Gemini API key obtained through Google AI Studio. Unlike the free tiers of earlier Gemini models, Deep Research Max is a premium service and requires a paid tier account. Developers must export their API key as an environment variable to ensure the SDK can authenticate requests securely.
export GEMINI_API_KEY="your-api-key-here"
pip install google-genai2. Initiating a Research Task
The core of the implementation involves calling client.interactions.create. It is mandatory to set the background=True parameter, as the system will not allow synchronous execution for these long-running tasks.
from google import genai
client = genai.Client()
interaction = client.interactions.create(
input="Analyze the impact of the EU AI Act on mid-sized SaaS providers in 2026.",
agent="deep-research-max-preview-04-2026",
background=True
)3. The Polling Mechanism
Because the agent works asynchronously, the application must "poll" the API to check the status of the research. A typical production implementation checks the status every 10 to 30 seconds. Once the status transitions from "running" to "completed," the final output—a markdown or HTML report—can be retrieved from the outputs list.
Native Visualizations and Data Synthesis
One of the most disruptive features of Deep Research Max is its ability to generate "native" visualizations. Historically, AI agents would provide raw data, which developers would then need to pass to libraries like Matplotlib or Plotly to create charts.

Deep Research Max eliminates this step. By including instructions such as "generate all charts natively inline," the agent can produce HTML-based visual reports. This includes bar charts, trend lines, and comparison tables embedded directly into the research document. This capability is particularly valuable for automated reporting pipelines in finance and marketing, where visual data representation is essential for stakeholder reviews.
Industry Implications and Strategic Analysis
The launch of Deep Research Max has profound implications for several professional sectors. In the legal and regulatory fields, the ability to parse thousands of pages of legislative text and provide a cited summary reduces the "first-pass" research time from days to minutes. In financial services, the agent’s capacity for due diligence allows for more rigorous vetting of investment opportunities by automatically aggregating market sentiment, financial filings, and news reports.
Industry analysts suggest that this move is Google’s attempt to reclaim the lead in the "agentic AI" race. By providing a managed service that handles the "planning" and "searching" phases of research, Google is lowering the barrier to entry for companies that want to build sophisticated AI tools but lack the expertise to build custom RAG (Retrieval-Augmented Generation) stacks.
However, the move to a stateful API also introduces new challenges for developers. Managing "Interaction IDs" requires a robust database backend to ensure that if a user’s session is interrupted, they can still retrieve their completed report. Furthermore, the cost-per-task model necessitates a shift in how companies budget for AI, moving from token-based micro-payments to task-based project fees.
Production Best Practices
For organizations moving Deep Research Max into a production environment, Google recommends several best practices:

- State Management: Store Interaction IDs in a persistent database (like Firestore or PostgreSQL) to allow users to return to their research later.
- Exponential Backoff: When polling for results, use an exponential backoff strategy to avoid hitting API rate limits.
- Prompt Engineering: Use highly specific prompts. Since each "Max" run costs several dollars, vague prompts can lead to expensive, irrelevant reports.
- Human-in-the-Loop: While the agent is autonomous, final reports should be reviewed by subject matter experts, especially in high-stakes fields like medicine or law.
Conclusion
Deep Research Max represents a maturation of generative AI from a creative assistant to an analytical workhorse. By combining the reasoning power of Gemini 3.1 Pro with an autonomous, stateful execution engine, Google has provided a tool that mimics the workflow of a human research analyst. As the technology moves out of the preview phase, the ability of organizations to integrate these autonomous agents into their core decision-making processes will likely become a key competitive differentiator in the data-driven economy of 2026 and beyond.