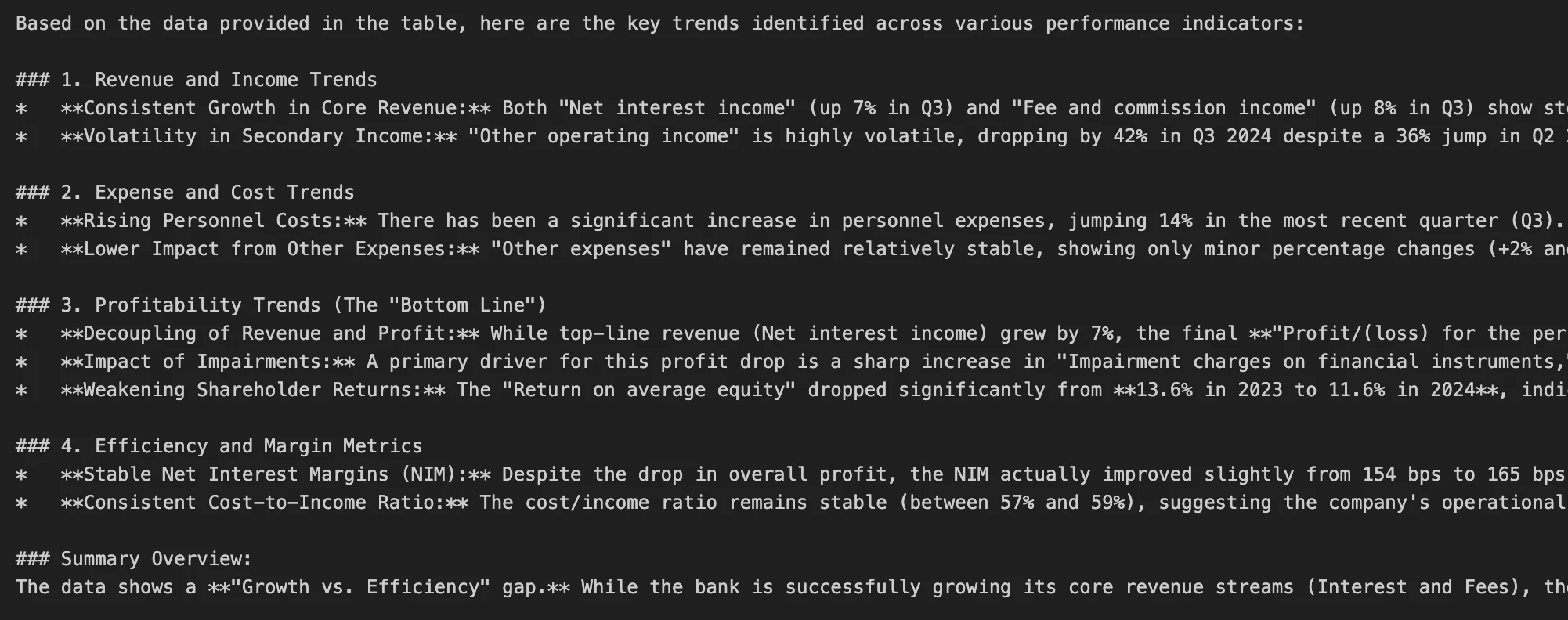
The landscape of artificial intelligence underwent a fundamental shift with the introduction of Gemini Omni, marking a transition from specialized, siloed AI tools to a unified multimodal framework capable of processing and generating text, audio, images, and high-definition video within a single interface. Since its inception in early 2023 as a text-based chatbot, Google’s Gemini series has rapidly evolved, responding to a competitive market that demands increasingly complex sensory understanding. The launch of Gemini Omni represents the culmination of this trajectory, positioning video generation not as a standalone novelty, but as a standard capability of a comprehensive AI assistant. By integrating video production into the core functionality of its generative models, Google aims to democratize high-fidelity content creation, allowing users to move seamlessly between different media formats through natural language processing.
The Evolution of the Gemini Ecosystem
The journey toward Gemini Omni began with the rebranding of Google’s "Bard" to "Gemini" in late 2023, signaling a shift toward a "native multimodal" architecture. Unlike previous iterations of AI that relied on stitching together separate models for text and vision, Gemini was built from the ground up to understand diverse data types simultaneously. The introduction of the Gemini 1.5 Pro and Flash models earlier in 2024 set the stage for this expansion, offering massive "context windows" capable of processing up to two million tokens. This technical foundation allowed the model to ingest hours of video or thousands of lines of code, providing the necessary computational "memory" to generate coherent video sequences that maintain temporal and visual consistency.

Gemini Omni is the practical application of this architecture in a consumer-facing environment. It signifies a move away from the "prompt-to-output" silos seen in platforms like OpenAI’s Sora or Runway Gen-3, which are primarily creative tools for filmmakers. Instead, Gemini Omni is designed for the everyday user, integrating video generation into the Google Workspace and the broader Android ecosystem. This strategic positioning suggests that Google views video as the next frontier of communication, comparable to the shift from text-only emails to the inclusion of images and attachments.
Core Capabilities: From Static Inputs to Dynamic Motion
The functional core of Gemini Omni revolves around three primary modalities: Text-to-Video, Image-to-Video, and Video-to-Video editing. Each of these capabilities utilizes the model’s unified latent space, where it treats different forms of information as interchangeable data points.
In the Text-to-Video domain, Gemini Omni demonstrates an advanced understanding of cinematic language and narrative structure. Rather than merely generating a series of disjointed frames, the model interprets complex prompts to create sequences with intentional camera movements, such as pans, tilts, and dollies. For example, a prompt describing a "drone flying over snow-covered mountains at sunrise" requires the AI to synthesize physics-based lighting, fluid motion, and environmental textures. The model’s ability to maintain "character consistency"—ensuring that a subject remains identical across different shots—remains one of its most touted features, addressing a common failure point in earlier generative video technologies.

The Image-to-Video feature allows for the animation of static assets, a tool particularly useful for digital marketing and social media content. By uploading a single image, such as a character silhouette or a landscape, users can instruct the model to "breathe life" into the visual. Technical tests have shown that the model can infer depth and hidden geometry; for instance, if provided with a portrait, it can generate a subtle head turn or eye movement that reveals perspectives not present in the original 2D file.
Finally, the Video-to-Video editing capability introduces a "style transfer" mechanism. This allows users to upload raw footage—such as a mobile phone recording or gameplay video—and apply a thematic overlay. A user could, for example, request that a standard video be converted into a black-and-white noir aesthetic or a hand-drawn anime style. This level of manipulation suggests a future where high-end post-production effects are accessible through simple conversational commands.
Technical Performance and Prompt Engineering
The efficacy of Gemini Omni is heavily dependent on "prompt engineering," the practice of crafting detailed instructions to guide the AI’s output. In testing scenarios, such as the creation of an animated short titled "The Cloud Painter," the model required a sophisticated hierarchy of instructions. This included a "Style" block to establish the aesthetic (e.g., "whimsical storybook"), a "Prompt" block for the narrative action, and a "Negative Prompt" block to explicitly forbid certain errors, such as distorted anatomy, flickering objects, or inconsistent proportions.

Industry analysts note that the use of "Negative Prompts" acts as a crucial safety and quality guardrail. By telling the model what not to do, users can mitigate the "hallucinations" common in generative models, such as the spontaneous appearance of extra limbs on a character or the sudden changing of a character’s clothing between frames. The model’s success in these tests indicates a high level of "visual coherence," meaning the AI maintains a stable understanding of the 3D space it is simulating over time.
Market Context and Competitive Landscape
The release of Gemini Omni comes at a time of intense competition in the generative AI sector. Google is currently vying for dominance against OpenAI, whose "Sora" model stunned the industry with its photorealistic 60-second clips, and emerging players like Luma AI and Kling. While Sora is currently limited to a select group of visual artists and red-teamers, Google’s strategy with Gemini Omni is focused on immediate accessibility and integration.
Supporting data from market research firms suggests that the generative video market is expected to grow at a compound annual growth rate (CAGR) of over 35% through 2030. Google’s advantage lies in its existing user base; by embedding Omni into Gemini Advanced (a $20/month subscription) and the Google AI Studio, the company provides a low-friction entry point for enterprises and creators who are already part of the Google Cloud or Workspace environments.
Institutional Challenges and Content Guardrails
Despite its technical prowess, the rollout of Gemini Omni has faced significant friction regarding content moderation and copyright policies. The model is governed by strict "third-party guardrails" designed to prevent the generation of deepfakes, copyrighted material, or sensitive content.
Reports from early adopters indicate that the model frequently refuses prompts that it deems a violation of safety protocols, even when the intent is benign. This "constant denial" of generation has become a point of contention for professional creators who require more flexibility. Furthermore, Google’s policy regarding the use of likenesses—such as public figures or characters from existing media—is notably more restrictive than some of its competitors. This is largely a defensive posture aimed at avoiding the legal entanglements currently facing AI companies regarding data scraping and intellectual property.
Secondary limitations include the duration of the generated clips, which are currently restricted to short bursts (often under 10 seconds), and the "compute-based limits" that vary based on the user’s subscription plan. High-resolution video generation is computationally expensive, leading to usage caps that can hinder the workflow of power users.

Implications for the Future of Media
The broader implications of Gemini Omni extend beyond simple entertainment. In the corporate sector, the ability to generate rapid video prototypes could revolutionize the advertising industry, allowing for "A/B testing" of visual concepts in minutes rather than weeks. In education, complex scientific concepts can be visualized through AI-generated animations, providing a more immersive learning experience.
However, the "mainstreaming" of AI video also raises ethical concerns regarding the authenticity of digital content. As these tools become more integrated into daily-use assistants, the line between reality and synthetic media continues to blur. Google has addressed some of these concerns by implementing "SynthID," a digital watermarking technology that embeds an invisible, tamper-resistant identifier into the pixels of AI-generated videos to aid in their identification.
Conclusion
Gemini Omni represents a pivotal moment in the democratization of artificial intelligence. It signals the end of the era where video production was a specialized skill requiring expensive hardware and software. While current limitations—such as short clip durations and aggressive content filtering—remain significant hurdles, the underlying technology demonstrates a sophisticated leap in multimodal understanding. As Google continues to refine its models and expand its computational infrastructure, Gemini Omni is poised to transform the AI assistant from a text-based helper into a comprehensive creative partner, capable of visualizing human ideas with unprecedented speed and scale. The "future of video" is no longer a distant prospect; it is a feature now being integrated into the palm of the user’s hand.