Autoregressive models represent one of the most significant pillars in the fields of time series forecasting, econometrics, and modern sequence modeling. While the terminology may appear daunting to those outside the mathematical sciences, the underlying logic is a fundamental principle of data science: the past is a prologue to the future. In its simplest form, an autoregressive model is a statistical framework that predicts the next value in a sequence by analyzing and weighing previous values within that same sequence. This “self-predicting” nature is what distinguishes autoregressive models from other forms of regression, making them indispensable for everything from predicting global stock market fluctuations to the generation of human-like text in Large Language Models (LLMs).
The term “autoregressive” is derived from two distinct concepts. “Auto” signifies the self-referential nature of the process, while “regressive” refers to the technique of predicting a dependent variable based on its relationship with other independent variables. In this specific context, the independent variables are simply the historical iterations of the dependent variable itself. By utilizing the internal patterns of a dataset, these models can identify trends, seasonal cycles, and recurring anomalies that external variables might overlook.
The Historical Evolution of Autoregressive Theory
The conceptual roots of autoregressive modeling date back to the early 20th century, long before the advent of modern computing. The foundational work was pioneered by statisticians such as George Udny Yule and Gilbert Walker in the 1920s. Their development of the Yule-Walker equations provided a mathematical method for estimating the parameters of an autoregressive process, initially applied to understand the periodic nature of sunspots and the movement of pendulums.
Throughout the mid-20th century, these models became the bedrock of econometrics. Governments and financial institutions adopted Autoregressive (AR) and Autoregressive Integrated Moving Average (ARIMA) models to forecast Gross Domestic Product (GDP), inflation rates, and unemployment figures. The transition from purely linear statistical models to the sophisticated neural networks of the 21st century has seen the autoregressive principle evolve but remain central. Today, the same logic that predicted wheat prices in the 1940s is being used by companies like OpenAI and Google to determine the most likely next word in a sentence.
The Mathematical Framework of AR Models
To understand the mechanics of these models, one must examine the standard AR(p) notation. In this framework, “p” represents the “order” of the model—the number of preceding time steps the model considers when making a prediction.
A basic AR(1) model, or a first-order autoregressive model, is expressed as:
xt = c + ϕ1xt−1 + εt
In this equation, xt represents the current value being predicted. The constant c serves as a baseline intercept, while ϕ1 is the coefficient that determines how much influence the immediately preceding value (xt−1) has on the current one. Finally, εt represents “white noise” or random error—the unpredictable fluctuations that exist in any real-world data system.
When the complexity of the data increases, researchers utilize a general AR(p) model, which incorporates multiple past observations:
xt = c + ϕ1xt−1 + ϕ2xt−2 + … + ϕpxt−p + εt
For instance, an AR(3) model predicting electricity demand would look at the usage data from the previous three hours to estimate the requirements for the fourth hour. This allows the model to capture short-term momentum and “memory” within the data, providing a more nuanced forecast than a simple average would allow.
Industry Applications and Supporting Data
The utility of autoregressive models spans across diverse sectors, each relying on the model’s ability to turn historical data into actionable intelligence.
1. Financial Markets and High-Frequency Trading
In the financial sector, volatility is the only constant. Autoregressive Conditional Heteroskedasticity (ARCH) models, an advanced derivative of the AR family, are used to forecast the volatility of returns. According to industry reports, a significant portion of algorithmic trading volume on the New York Stock Exchange is influenced by models that utilize autoregressive components to identify “mean reversion” patterns—the tendency of a stock price to return to its historical average.
2. Climate Science and Meteorology
Meteorologists use autoregressive frameworks to model temperature anomalies and sea-level rises. By analyzing decades of daily temperature readings, these models can filter out seasonal noise to identify long-term warming trends. Data from the Intergovernmental Panel on Climate Change (IPCC) often relies on time-series analysis where autoregressive integrated models help project future climate scenarios based on historical carbon emission levels.
3. E-commerce and Supply Chain Management
Retail giants like Amazon and Walmart utilize autoregressive forecasting to manage inventory. If a specific product sees a 5% increase in sales every day for a week (e.g., Monday: 1,000 units, Tuesday: 1,050 units, Wednesday: 1,102 units), the model identifies this growth trajectory. This allows for precise “Just-in-Time” (JIT) manufacturing, reducing warehouse costs and preventing stockouts.
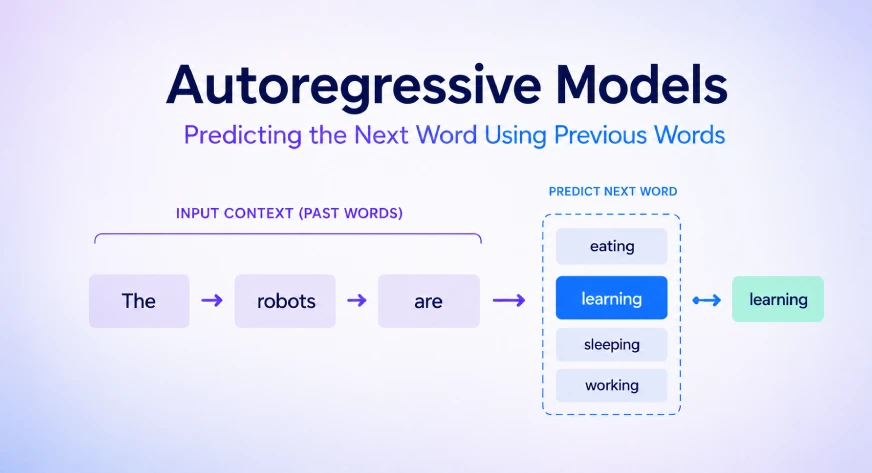
Autoregressive Models in the Age of Generative AI
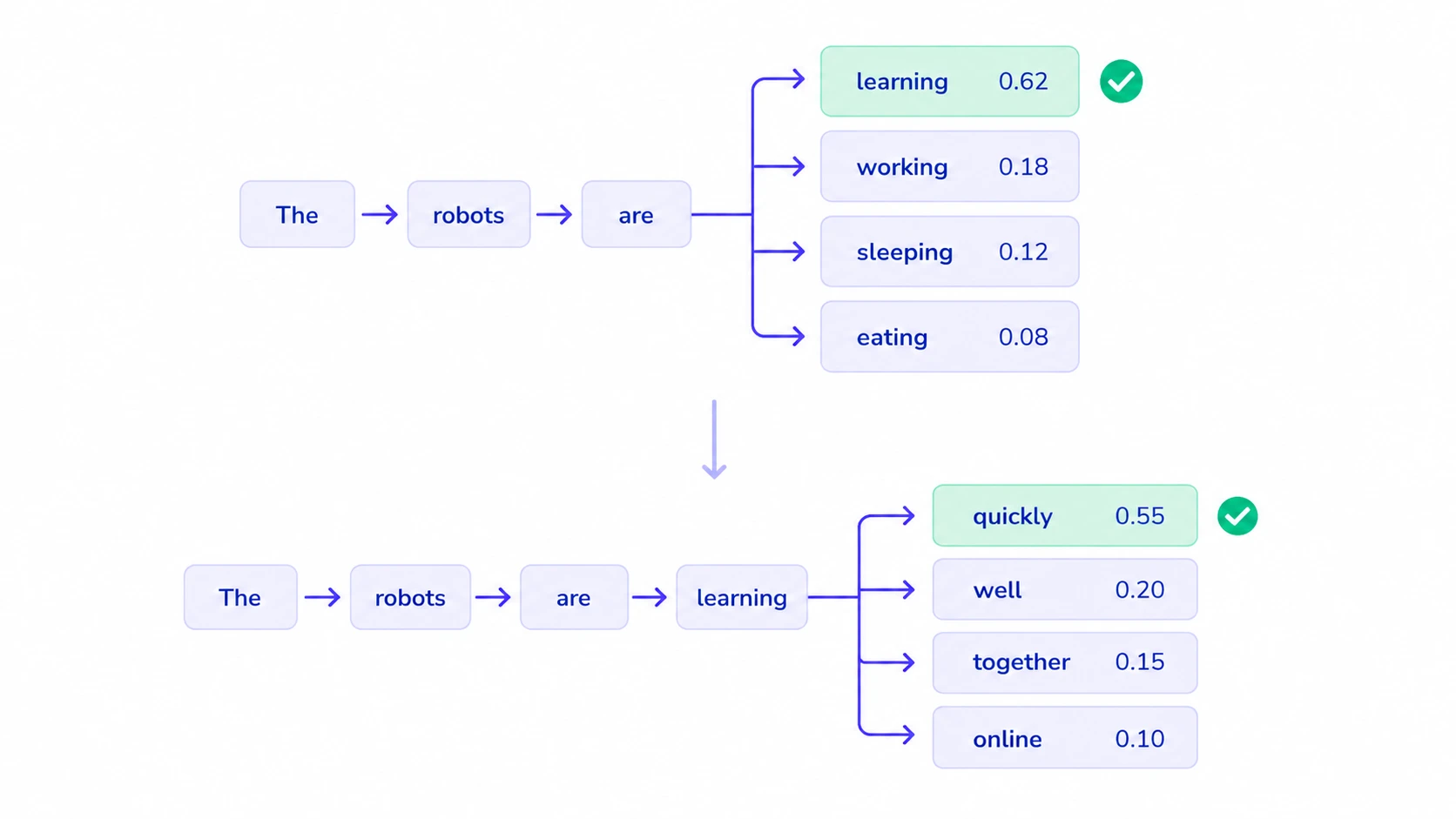
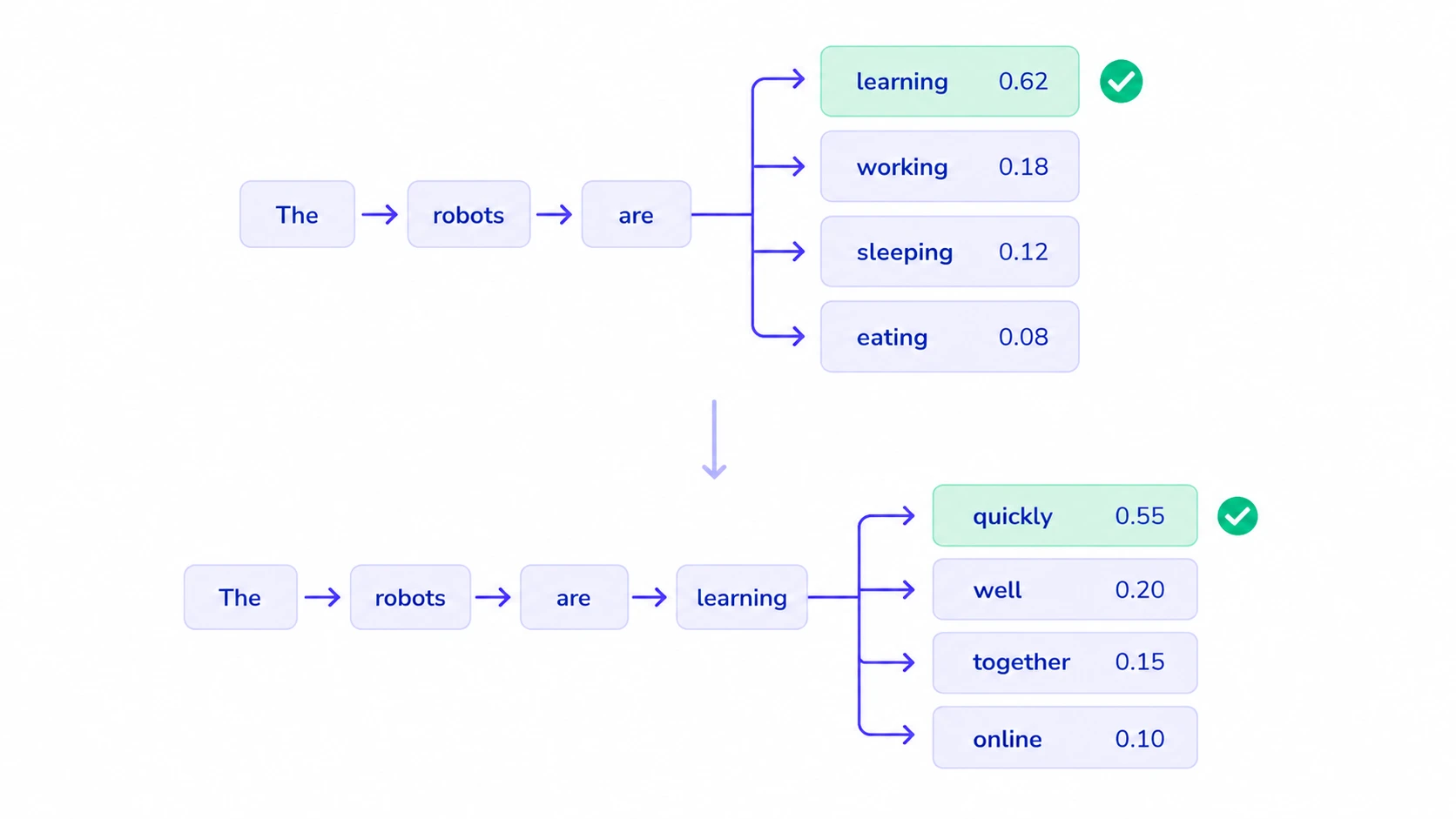
Perhaps the most visible application of autoregressive modeling today is in Natural Language Processing (NLP). Large Language Models, such as the GPT (Generative Pre-trained Transformer) series, are fundamentally autoregressive. They do not generate an entire paragraph instantaneously; instead, they predict text one “token” (a word or part of a word) at a time.
When a user provides a prompt like “The capital of France is,” the model calculates the probability of all possible next words based on the billions of sentences it has processed during training. It identifies “Paris” as the most statistically probable next token. Once “Paris” is generated, the model re-analyzes the entire string—”The capital of France is Paris”—to predict the next token, which might be a period or a supporting fact.
This sequential dependency is expressed through the joint probability of a sequence:
P(w1, w2, …, wn) = Π P(wi | w1, …, wi−1)
This mathematical structure ensures that each word generated is contextually grounded in every word that preceded it, allowing for the creation of coherent, long-form essays and complex code.
Comparative Analysis: Autoregressive vs. Non-Autoregressive Models
As AI research progresses, a debate has emerged regarding the efficiency of autoregressive generation versus non-autoregressive (NAR) alternatives.
| Feature | Autoregressive Models | Non-Autoregressive Models |
|---|---|---|
| Generation Method | Sequential (One by one) | Parallel (Simultaneous) |
| Consistency | High; maintains strong context | Variable; can suffer from repetition |
| Inference Speed | Slower due to step-by-step nature | Faster; utilizes GPU parallelism |
| Primary Use Case | Text generation, complex forecasting | Image generation, rapid translation |
| Examples | GPT-4, Llama 3, ARIMA | Diffusion Models, Parallel NAT |
While non-autoregressive models, such as certain types of Diffusion Models used in image generation (like Midjourney or DALL-E), are significantly faster because they generate all pixels or tokens at once, they often struggle with the logical “flow” required for language. Consequently, the industry standard for high-quality text remains firmly rooted in the autoregressive tradition.
Challenges, Limitations, and Technical Constraints
Despite their ubiquity, autoregressive models are not without significant limitations. Industry analysts and data scientists highlight three primary challenges:
1. Error Accumulation (Exposure Bias)
Because each prediction is based on the previous one, a single mistake early in a sequence can “compound.” In a weather forecast, a slight miscalculation of Monday’s humidity can lead to a completely inaccurate prediction for Friday. In AI, this often manifests as “hallucination,” where one incorrect word leads the model down a path of increasingly nonsensical text.
2. Computational Bottlenecks
The sequential nature of AR models means they cannot fully exploit the parallel processing power of modern GPUs. Since step B cannot begin until step A is finished, generating long documents is time-consuming and energy-intensive compared to parallel models.
3. Sensitivity to Sudden Shocks
AR models excel at predicting “business as usual” scenarios. However, they struggle with “Black Swan” events—unpredictable shocks like a global pandemic or a sudden market crash. Because the model only knows what has happened before, it cannot anticipate a future that looks fundamentally different from the past.
Broader Impact and Future Implications
The continued refinement of autoregressive models is central to the next phase of the digital economy. As businesses move from being “data-driven” to “prediction-driven,” the ability to accurately model sequences becomes a competitive necessity. We are seeing a shift where these models are being integrated into “Agentic AI”—systems that don’t just predict the next word but predict the next sequence of actions to solve a complex problem, such as booking a flight or managing a corporate budget.
Industry experts suggest that the future of the field lies in hybrid architectures. By combining the logical consistency of autoregressive modeling with the speed of non-autoregressive systems, the next generation of AI will likely be both more reliable and more efficient.
In conclusion, autoregressive models serve as a vital bridge between historical observation and future anticipation. From their humble beginnings in 1920s statistics to their current role as the engine of the AI revolution, they remain a testament to the idea that the patterns of the past are the most reliable guides to the mysteries of the future. For any organization or individual looking to navigate the complexities of modern data, understanding the mechanics and the “memory” of autoregression is no longer optional—it is a foundational requirement.