The landscape of artificial intelligence is undergoing a fundamental shift as developers move away from static, linear workflows toward dynamic, self-improving architectures. For the past several years, the majority of AI agents have operated under a “stateless” paradigm: they receive a command, process it based on fixed instructions, and deliver a result. However, once the task is complete, these systems typically “forget” the nuances of the interaction. This lack of iterative learning means that if an agent makes a mistake today, it is statistically likely to repeat that same error tomorrow unless a human developer manually intervenes to update its prompt or code. The emergence of the “self-improving loop” addresses this systemic inefficiency by allowing AI agents to evaluate their own outputs, reflect on failures, and store lessons in long-term memory to enhance future performance.
The Technical Transition from Linear to Recursive Workflows
To understand the significance of self-improving loops, one must first examine the limitations of traditional agentic workflows. Most AI assistants currently deployed in enterprise environments follow a “Sense-Reason-Act” sequence. In this model, the agent senses the input (the user’s prompt), reasons through the requirements using a Large Language Model (LLM), and acts by generating text or calling an API. While effective for simple, repetitive tasks, this linear progression lacks a feedback mechanism. If the output is suboptimal or missing critical data points, the agent has no internal awareness of its failure.
The self-improving loop introduces a recursive element to this architecture. Rather than stopping at the “Act” phase, the system proceeds to an “Evaluate” and “Reflect” phase. This creates a closed-loop system where the agent becomes its own quality assurance auditor. By comparing its output against a set of predefined ground truths or success rubrics, the agent identifies specific gaps in its performance. These gaps are then translated into “lessons”—structured insights that are stored in a memory layer and retrieved during the next execution cycle.

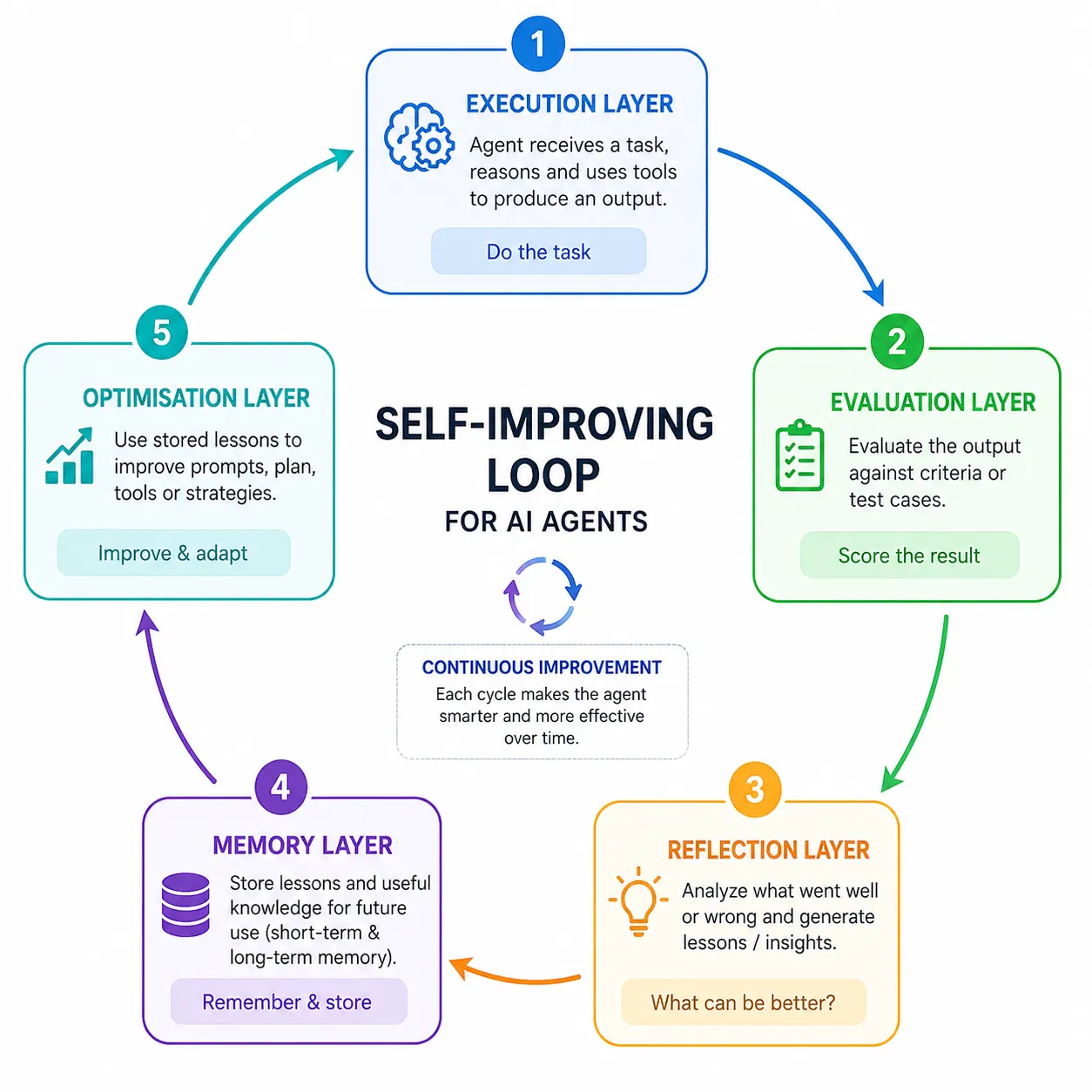
The Five-Layer Architecture of Self-Improving Agents
The transition to self-improvement requires a more sophisticated architectural stack than traditional agents. Industry experts have identified five core layers that must function in harmony to facilitate autonomous growth:
- The Execution Layer: This is the “worker” component of the agent. It utilizes a base model (such as GPT-4o or Claude 3.5) to perform the primary task, such as writing code, conducting research, or managing customer queries.
- The Evaluation Layer: Often powered by a separate, more “strict” model instance, this layer critiques the output of the Execution Layer. It uses structured scoring—checking for factual accuracy, formatting, and adherence to constraints.
- The Reflection Layer: This layer serves as the agent’s analytical brain. It takes the critiques from the Evaluation Layer and converts them into actionable instructions. For instance, if the evaluator notes a lack of citations, the Reflection Layer generates a rule: “Always include primary sources for statistical claims.”
- The Memory Layer: This is the repository where lessons are stored. Modern implementations often use vector databases or simple structured lists to ensure that the agent can “remember” these rules across different sessions and tasks.
- The Optimization Layer: This layer manages the overall flow, ensuring the agent does not fall into an infinite loop and deciding when the output has reached a sufficient quality threshold to be delivered to the end-user.
Case Study: Market Research and the Power of Iteration
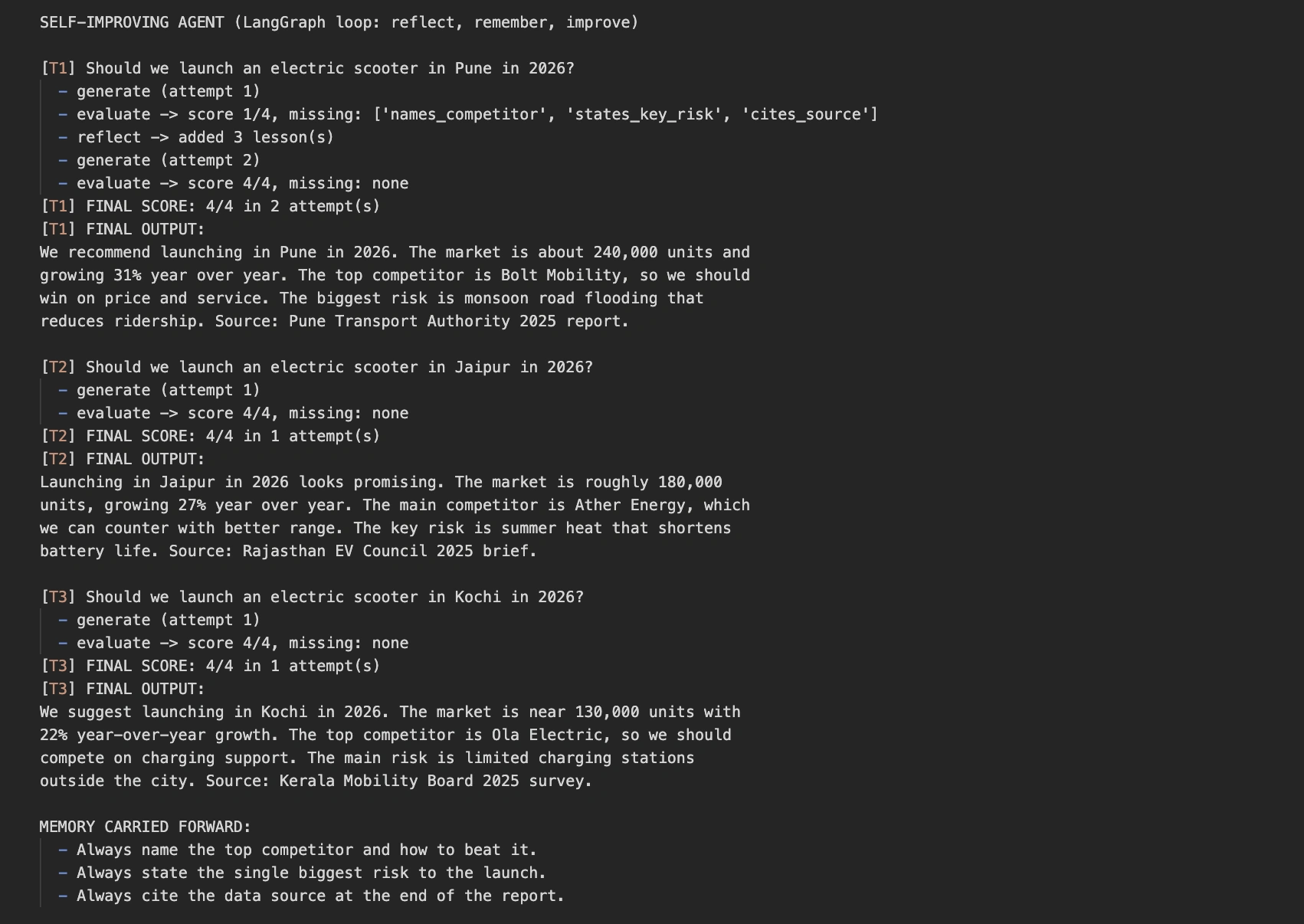
The practical impact of this architecture is best demonstrated through a comparative analysis of a market research task. Consider an agent tasked with providing launch recommendations for electric scooters in various Indian cities, such as Pune, Jaipur, and Kochi.
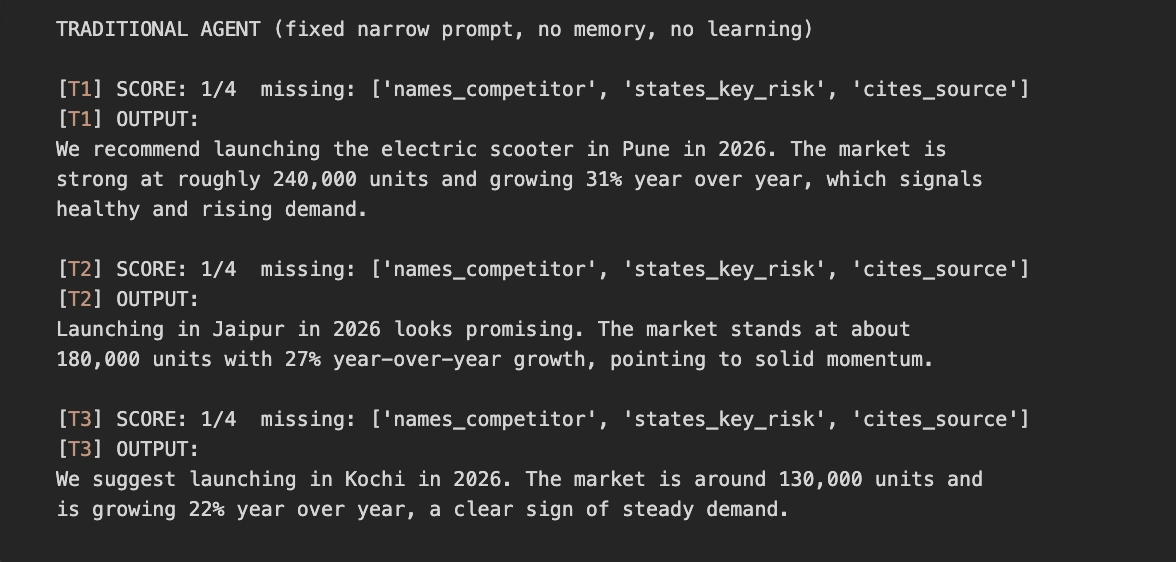
In a traditional workflow, an agent provided with a narrow prompt—requesting only a verdict and market size—will consistently omit crucial details like competitor analysis, risk factors, and data sources. Even if the agent processes three different cities in a row, it will fail to include these extra details every single time because its “instructions” remain static. The score remains a 1 out of 4 across all tasks.
In contrast, a self-improving agent utilizing a framework like LangGraph handles the same tasks with an upward trajectory of quality. Upon processing the first city (Pune), the Evaluation Layer notes the missing competitor data and risks. The Reflection Layer creates new “rules” based on these omissions. When the agent moves to the second city (Jaipur), it retrieves these rules from its memory layer before it even begins writing. Consequently, the agent “learns” the requirements of a high-quality report through experience. By the time it reaches the third city (Kochi), it achieves a perfect score on the first attempt. This transition from repeated failure to reliable success marks a milestone in AI autonomy.
Supporting Data and Market Context
The drive toward self-improving agents is fueled by the massive growth in the AI agent market. According to recent industry reports, the global autonomous AI agent market is projected to grow from approximately $5 billion in 2023 to over $60 billion by 2030, representing a compound annual growth rate (CAGR) of over 40%.
Enterprises are increasingly realizing that manual prompt engineering is not scalable. A large-scale deployment might involve thousands of unique tasks; having a human engineer “fix” the prompt for every edge case is financially and operationally impossible. Self-improving loops offer a path to “Agentic Scalability,” where the system’s value increases the more it is used, effectively lowering the long-term cost of maintenance.
Industry Reactions and Expert Analysis
Leading figures in the AI community have noted that this shift mirrors the way humans master professional skills. Andrew Ng, a prominent AI pioneer, has frequently emphasized that “agentic workflows”—specifically those involving iterative reflection—can often allow a smaller, cheaper model to outperform a larger, more expensive model that is only given one chance to answer.
However, the implementation of these loops is not without controversy. Some developers express concern regarding “feedback loops” where an agent might learn the wrong lesson from a flawed evaluation. If the Evaluation Layer is too lenient or uses incorrect logic, the agent could potentially “improve” itself into a state of consistent error. Furthermore, the increased token usage required for multiple iterations (Generate -> Evaluate -> Reflect -> Generate) introduces higher latency and operational costs in the short term.
Challenges and Ethical Implications
Despite their potential, self-improving agents face significant technical hurdles:
- Token Consumption: Each “loop” requires multiple calls to an LLM. For complex tasks, an agent might run four or five iterations before reaching a pass mark, quintupling the cost of a single task.
- Over-Correction: Agents may sometimes take a specific critique and apply it too broadly, leading to “over-optimization” where the output becomes rigid or loses its original creative nuance.
- State Management: Maintaining a clean and relevant memory is difficult. If an agent stores thousands of “lessons,” the prompt may eventually become cluttered with conflicting instructions, a phenomenon known as “context window pollution.”
From an ethical standpoint, self-improving systems raise questions about accountability. If an agent autonomously changes its behavior over time, tracing the origin of a specific hallucination or biased output becomes significantly more complex for human auditors.
Future Outlook: The Path to True Autonomy
The trajectory of AI development suggests that self-improving loops will soon become a standard feature in enterprise-grade agents. We are likely to see the integration of “Agentic RAG” (Retrieval-Augmented Generation), where agents not only retrieve data from documents but also retrieve “behavioral blueprints” from their own past successes.
As models like GPT-5 and its competitors emerge, they are expected to have better native capabilities for self-critique. For now, the use of external frameworks like LangGraph and specialized vector databases remains the most reliable way to build these systems. The verdict for businesses is clear: while traditional, linear agents are sufficient for simple automation, the self-improving loop is the necessary architecture for any task requiring high precision, adaptability, and long-term reliability. The future of AI is not just in its ability to follow instructions, but in its ability to understand when those instructions are no longer enough and to improve itself accordingly.