The integrity of digital experimentation is facing a critical challenge as organizations increasingly prioritize "winning" tests over the pursuit of objective truth. This phenomenon, known as p-hacking, involves the manipulation of experiment data—either intentionally or through procedural negligence—until a result appears statistically significant. As businesses transition toward data-driven decision-making, the prevalence of p-hacking threatens to undermine the very foundations of growth marketing and product development. By understanding the mechanics of statistical significance, the pitfalls of human bias, and the implementation of rigorous guardrails, organizations can protect their experimentation programs from the costly consequences of false positives.

The Statistical Reality of Modern Experimentation
At its core, p-hacking is a byproduct of Goodhart’s Law, which states that when a measure becomes a target, it ceases to be a good measure. In the context of A/B testing, when a "winning" experiment becomes the primary KPI for a marketing or product team, the pressure to find significance often overrides the commitment to scientific rigor. This behavior is not merely a technical error; it is a systemic risk that inflates the number of reported "wins" that are actually nothing more than statistical noise.
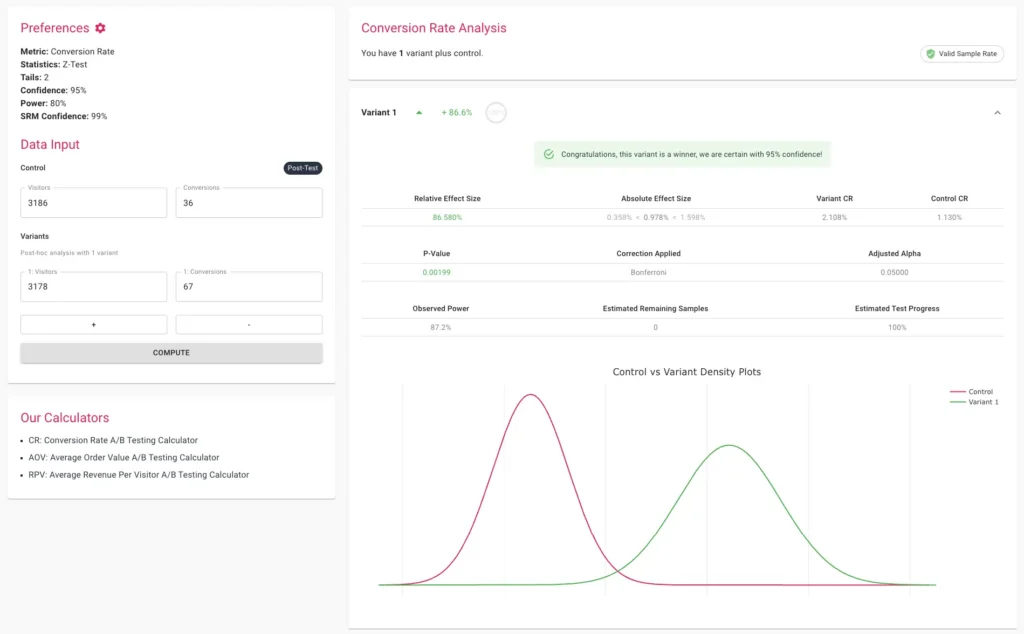
The scale of this issue was highlighted in a comprehensive 2018 analysis of 2,101 commercially run A/B tests. The study found that approximately 57% of experimenters engaged in some form of p-hacking once their results reached a 90% confidence level. The mathematical implications of this trend are severe. At a standard 90% confidence threshold, a disciplined testing program typically carries a False Discovery Rate (FDR) of approximately 33%. However, when p-hacking behaviors are introduced, the FDR jumps to 42%. This means that nearly half of all reported "winners" in such environments are likely false positives—changes implemented under the guise of improvement that actually have no impact or, in some cases, a negative one.

The Chronology of P-Hacking: From Design to Analysis
P-hacking does not occur in a vacuum; it creeps into the experimentation workflow at various stages, often disguised as "agility" or "deep-dive analysis." To prevent it, one must first identify the specific moments where data integrity is compromised.
The Pre-Experiment Phase: Planning Failures
The most common precursor to p-hacking is the failure to define statistical parameters before a test begins. Without a pre-calculated sample size and a fixed test duration, experimenters often fall into the trap of "continuous peeking." When a test is run without a predetermined end date, the probability of encountering a "significant" p-value by pure chance increases dramatically. If a tester stops the experiment the moment the p-value dips below 0.05, they are effectively cherry-picking a moment of random fluctuation rather than observing a stable trend.
The Execution Phase: The Peeking Problem
During the experiment, the temptation to monitor results daily is high. However, repeated significance testing is mathematically dangerous. Every time a tester "peeks" at the data and considers stopping the test, they are performing a new statistical test. Without adjusting for these multiple comparisons, the cumulative Type I error rate (the probability of a false positive) begins to climb. What was intended to be a 5% risk of error can easily double or triple depending on the frequency of these checks.
The Post-Experiment Phase: Metric Switching and Data Slicing
Perhaps the most deceptive form of p-hacking occurs after a test has failed to reach significance on its primary goal. Testers may begin "fishing" for a win by switching the success criteria to a secondary metric that happened to show a positive movement. Alternatively, they may engage in post-test segmentation, slicing the data by geography, device type, or traffic source until they find a specific subgroup that shows a "win." While segmentation is valuable for generating new hypotheses, reporting a segment-specific win as a successful outcome of the original test—without a prior hypothesis—is a classic p-hacking maneuver.
Technical Safeguards and Methodological Solutions
To combat these pitfalls, industry leaders are increasingly adopting "statistical guardrails"—technical and procedural limits that enforce rigor. Modern experimentation platforms, such as Convert Experiences, have integrated these safeguards directly into their workflows to minimize human error.
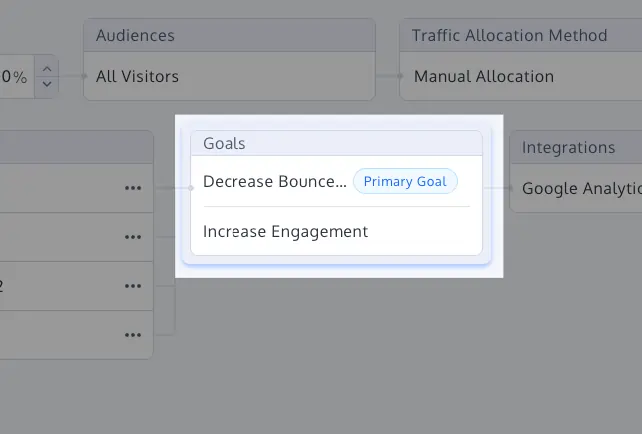
1. Primary Goal Labeling and Metric Locking
One of the simplest yet most effective defenses is the strict labeling of a "Primary Goal" before the test is launched. By designating one metric as the ultimate arbiter of success, organizations prevent the "moving of goalposts" after the data has been collected. Secondary metrics should be treated strictly as guardrails—indicators used to ensure that the primary change didn’t inadvertently break another part of the business—rather than alternative success metrics.
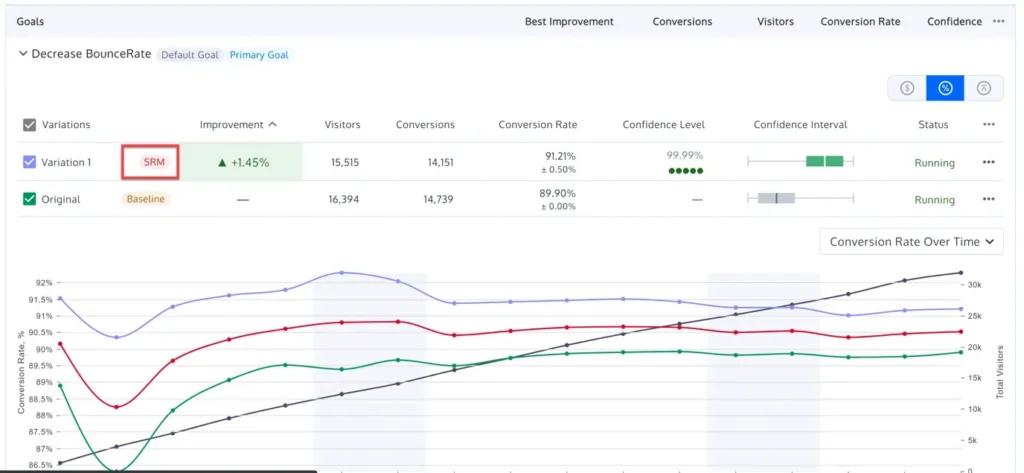
2. The Implementation of Sequential Testing
For organizations that require the ability to monitor tests in real-time without compromising integrity, sequential testing offers a mathematical solution. Unlike traditional fixed-horizon frequentist testing, sequential testing uses confidence sequences (often based on Waudby-Smith et al., 2023) that provide valid inference at any point during data collection. This allows teams to stop tests early if a result is overwhelmingly positive or negative, without inflating the false positive rate.
3. Multiple Comparison Corrections: Bonferroni and Sidak
When testing multiple variants against a single control, the probability of at least one variant appearing as a false winner increases. To counter this, statisticians use corrections like the Bonferroni or Sidak methods. These adjustments lower the significance threshold for each individual variant to ensure the overall "family-wise error rate" remains at the desired level (e.g., 5%). While the Sidak correction is often preferred for being slightly less conservative than Bonferroni, both are essential for maintaining the credibility of multi-variant tests.
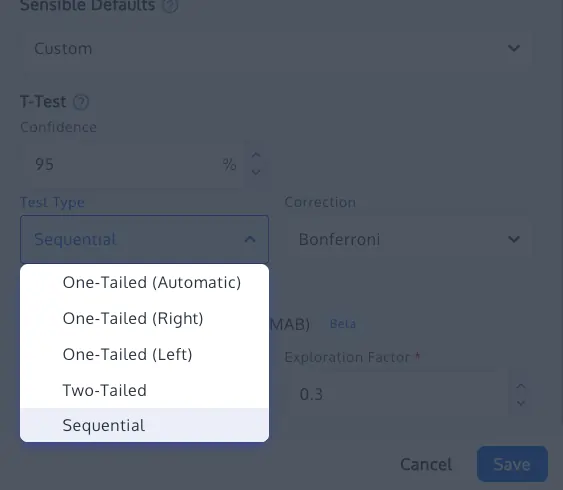
4. Sample Ratio Mismatch (SRM) Checks
Even a perfectly designed test can be invalidated by technical glitches. A Sample Ratio Mismatch occurs when the actual distribution of visitors across variants deviates from the intended allocation (e.g., a 50/50 split that ends up being 52/48). This is often a sign of tracking errors, bot interference, or redirect issues. Implementing an automated SRM check using a Chi-square goodness-of-fit test ensures that if the traffic split is broken, the results are discarded regardless of what the p-value suggests.
Expert Perspectives on Data Integrity
Sundar Swaminathan, author of the experiMENTAL newsletter and a prominent voice in the experimentation community, emphasizes that p-hacking is fundamentally a threat to professional credibility. "P-hacking is one of the most dangerous pitfalls because it makes random noise look like significant results," Swaminathan notes. "When testers stop experiments prematurely, they are jeopardizing the entire testing program. You start to roll out changes you think are impactful but aren’t, which undermines your standing with stakeholders."
The consensus among data scientists is that the "win rate" of a testing program is a vanity metric. A more accurate measure of a program’s health is the "False Discovery Rate" and the "Replication Rate"—the frequency with which winning experiments actually produce the predicted revenue or behavior change once fully implemented.
Broader Impact and Business Implications
The long-term consequences of p-hacking extend far beyond a single failed experiment. When an organization bases its product roadmap on false positives, it enters a cycle of "phantom growth." On paper, every test is a winner, yet the company’s core business metrics—such as total revenue or active user count—remain stagnant.

This discrepancy eventually leads to a loss of institutional trust. Executives may begin to doubt the value of the experimentation team, leading to budget cuts or the abandonment of data-driven processes in favor of "gut feeling" decision-making. Furthermore, the technical debt created by implementing dozens of "winning" features that do nothing can bloat the codebase and degrade the user experience.
In contrast, a program that embraces statistical rigor builds a foundation of "cumulative gains." While the number of reported wins may be lower, each win is a genuine insight that contributes to a deeper understanding of the customer. Over time, these small, verified improvements compound into significant competitive advantages.
Conclusion: The Path Forward
Preventing p-hacking requires a cultural shift as much as a technical one. Organizations must move away from a "culture of winning" and toward a "culture of learning." This involves celebrating "neutral" results as valuable data points that prevent the company from making wrong turns.
By adhering to rigid stopping rules, pre-defining success metrics, and utilizing advanced statistical methods like sequential testing and SRM checks, businesses can ensure their growth is built on a foundation of truth rather than a mirage of noise. In an era where data is the most valuable asset a company possesses, protecting the integrity of that data is not just a technical requirement—it is a strategic imperative. Organizations that fail to address p-hacking are not just testing poorly; they are making decisions in the dark. Those that prioritize rigor will find that their experiments eventually lead them to the only place that matters: sustainable, evidence-based growth.