The landscape of artificial intelligence is currently undergoing a fundamental transition as organizations move beyond general-purpose large language models (LLMs) toward specialized, data-grounded systems. At the heart of this evolution is Retrieval-Augmented Generation (RAG), a framework that allows AI to access external, private, or real-time data to provide accurate and context-aware responses. However, as enterprise requirements become more complex, a significant debate has emerged over the two primary architectures driving this field: Vector RAG and the more structured GraphRAG. While Vector RAG has established itself as the industry standard for rapid, similarity-based search, GraphRAG is emerging as a critical solution for multi-hop reasoning and holistic data synthesis. This analysis explores the architectural differences, implementation strategies, and strategic implications of these two approaches for modern data-driven organizations.
The Foundation of Retrieval-Augmented Generation
To understand the current tension between Vector and Graph approaches, one must first recognize the “hallucination” problem that plagued early LLM deployments. LLMs, while capable of generating fluent prose, often lack access to specific, up-to-date facts. RAG addressed this by introducing a retrieval step: when a user asks a question, the system searches a curated database, finds relevant information, and provides it to the LLM as a reference.
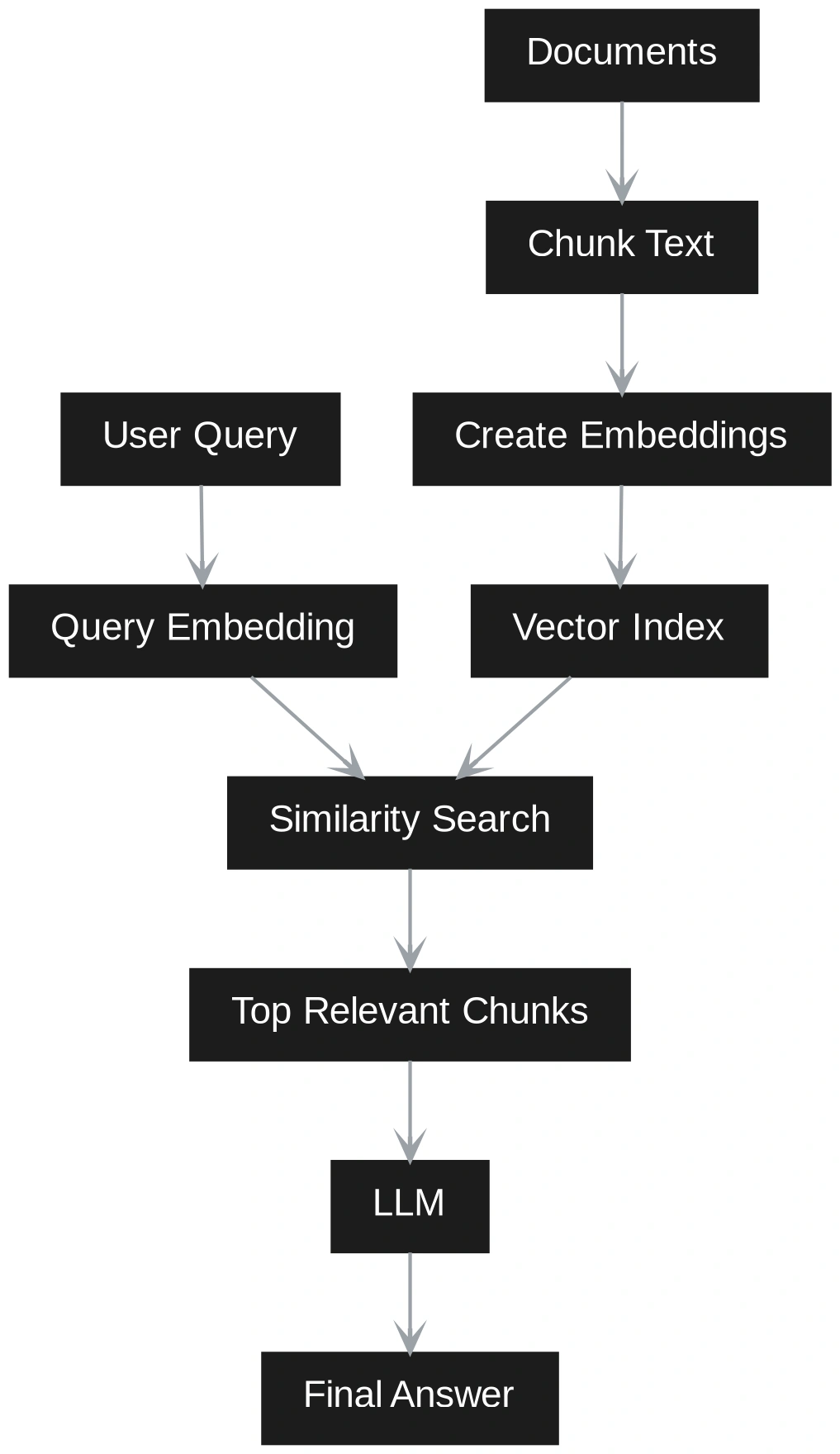
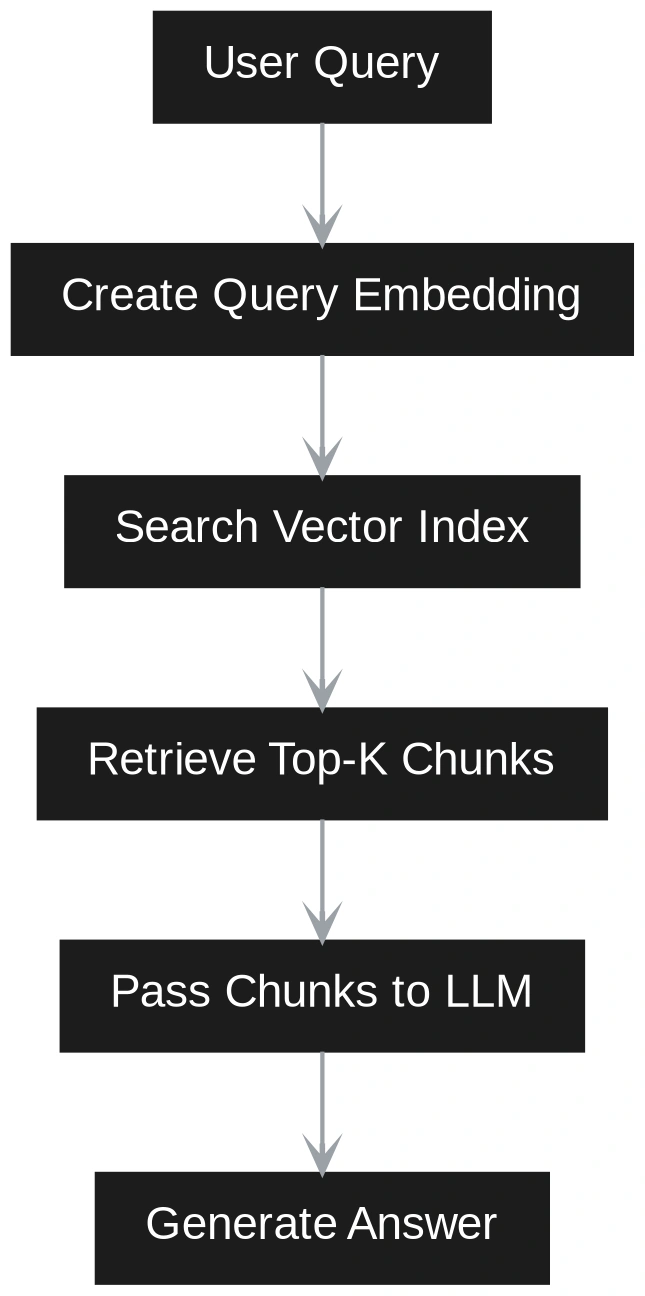
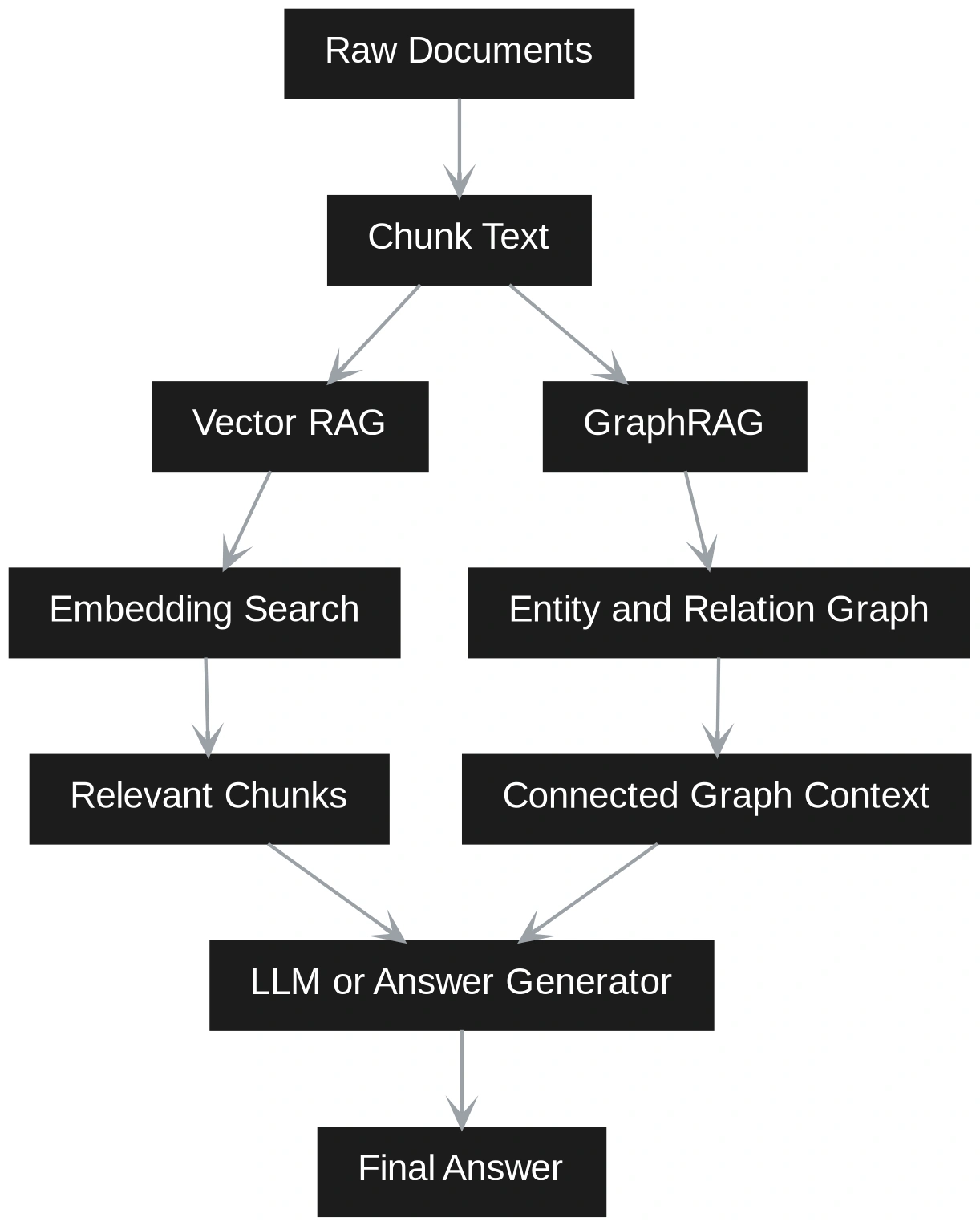
Vector RAG operates on the principle of semantic similarity. It breaks documents into discrete “chunks,” converts these chunks into high-dimensional mathematical representations called embeddings, and stores them in a vector database. When a query is made, the system finds chunks that are mathematically “closest” to the question. This method is highly effective for direct factual inquiries, such as “What is the company’s vacation policy?” where the answer likely resides within a single paragraph of a specific document.
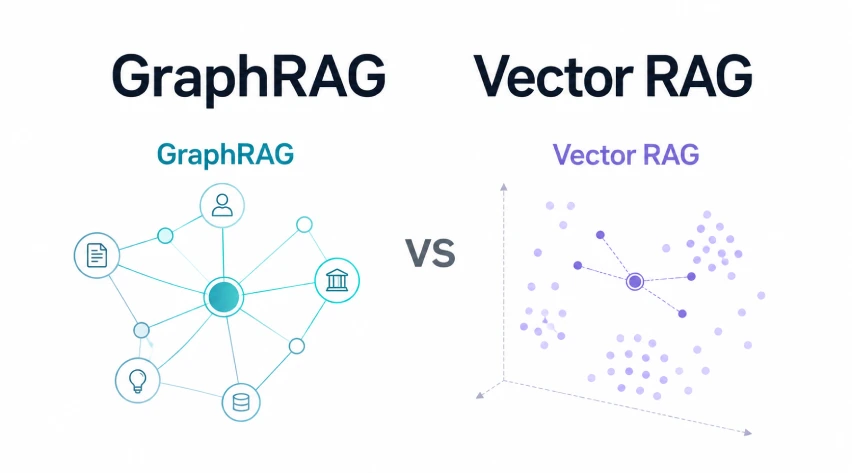
However, industry experts have identified a “connectivity gap” in traditional Vector RAG. Because it treats data as isolated chunks, it often fails to see the relationships between concepts that are mentioned in different parts of a document or across different files. This limitation led to the development of GraphRAG, which incorporates Knowledge Graphs (KGs) to map the explicit relationships between entities, providing a more structured and interconnected view of the information landscape.
Chronology of Development: From Similarity to Structure
The development of these technologies has followed a rapid timeline. In early 2023, the focus was primarily on optimizing vector databases like Pinecone, Milvus, and FAISS. These tools allowed developers to build RAG systems in days, fueling a wave of “Chat with your PDF” applications. By late 2023, however, enterprise users began reporting failures in scenarios requiring complex reasoning. A common failure mode occurred when an answer required synthesizing information from five different documents—a task Vector RAG often failed because it would only retrieve the top two or three most “similar” chunks, missing the broader context.
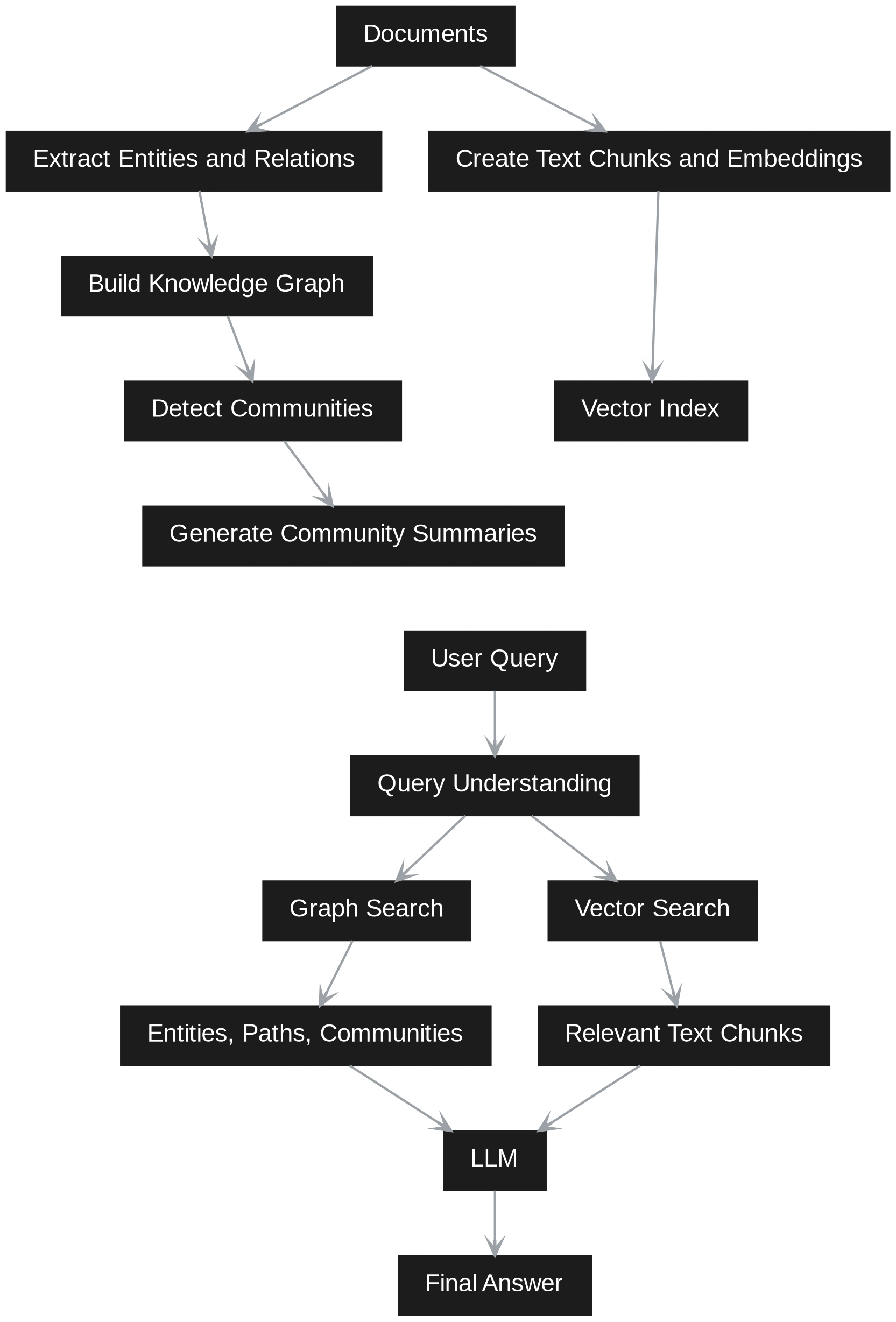
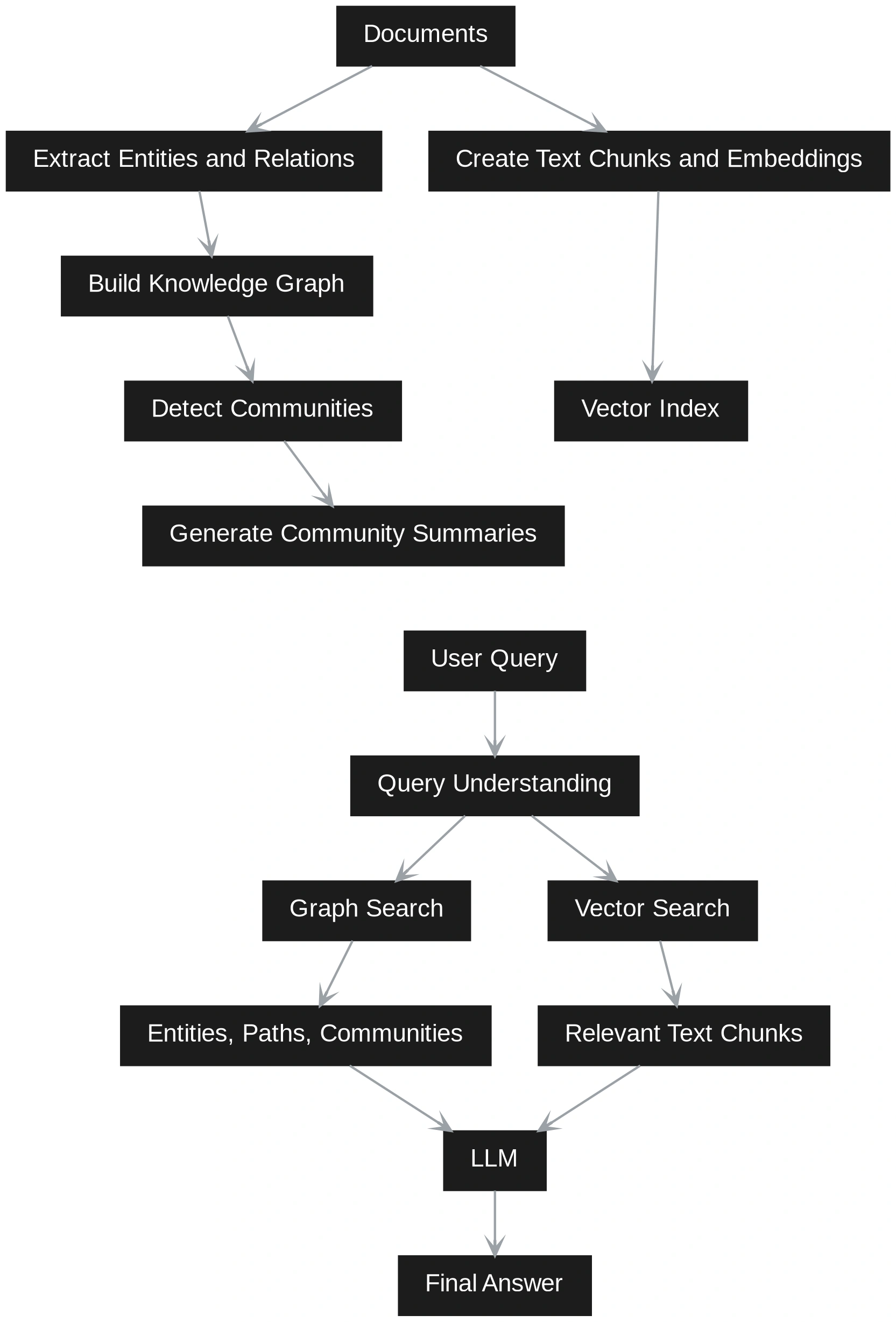
In mid-2024, the narrative shifted toward GraphRAG, popularized in part by research from Microsoft and the open-source community. This approach introduced a more rigorous indexing phase where LLMs are used to identify entities (people, places, products) and the relationships between them. This shift represents a move from “probabilistic retrieval” (finding what looks right) to “deterministic relationship mapping” (finding how things are actually connected).
Architectural Deep Dive: How the Systems Differ
The technical distinction between these two systems begins at the indexing stage. In Vector RAG, the process is linear: document ingestion, chunking, embedding, and storage. The retrieval is equally straightforward, relying on algorithms like Hierarchical Navigable Small World (HNSW) to find similar vectors.
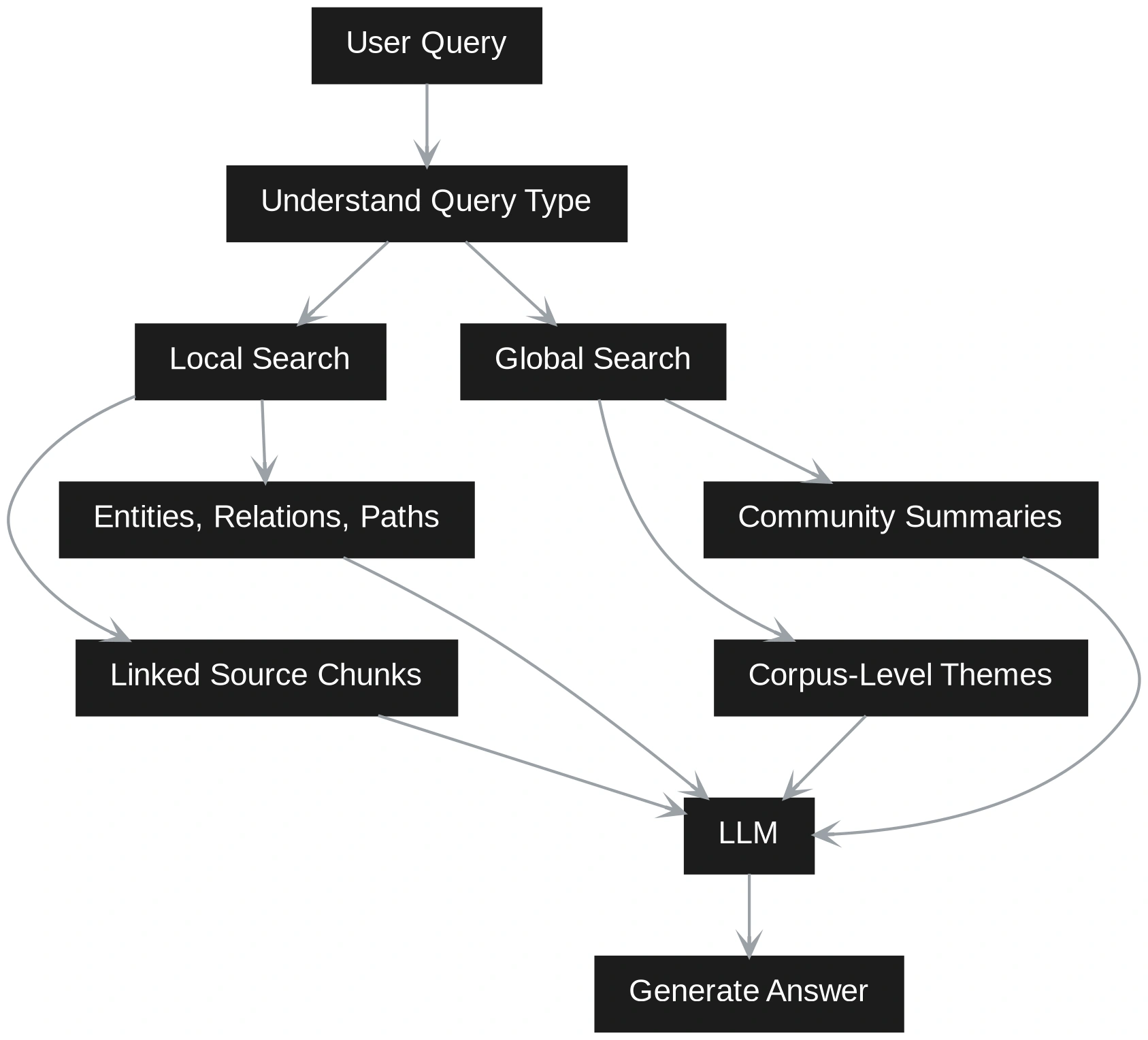
GraphRAG introduces a significantly more sophisticated indexing pipeline. The system must extract triplets—composed of a subject, a predicate, and an object (e.g., “Vendor A” -> “causes” -> “Delivery Delays”). These triplets are then used to construct a graph. Modern GraphRAG implementations also utilize community detection algorithms, such as the Leiden algorithm, to group related nodes into “communities.” This allows the system to summarize entire themes across a corpus before a user even asks a question.
At query time, Vector RAG treats every question as a search for a needle in a haystack. GraphRAG, by contrast, determines if a question is “local” (about a specific entity) or “global” (about a broad theme). For a local query, the system traverses the graph to find immediate neighbors of the entity in question. For a global query, it accesses the pre-generated community summaries to provide a high-level synthesis of the entire dataset.
Hands-on Implementation: A Comparative Case Study
To illustrate the practical differences, consider a corporate logistics scenario involving a company named NourishCo. In a typical Vector RAG setup, the system might index several reports regarding logistics costs in the “North Region” and performance issues with “Vendor A.”
Using Python-based tools such as SentenceTransformers for embeddings and FAISS for indexing, a Vector RAG system would respond efficiently to a query like “What are the logistics issues in the North Region?” by retrieving chunks that mention those specific terms. However, if a user asks, “How is Vendor A connected to financial pressure in the North?” the Vector RAG system might retrieve a document about Vendor A and a separate document about financial pressure, but it may fail to bridge the logical gap if the connection is indirect—for instance, if Vendor A causes delays, which increase inventory buffers, which in turn increase working capital pressure.
A GraphRAG implementation using NetworkX or a graph database like Neo4j would explicitly map these connections. During the indexing phase, the system identifies “Vendor A” and “Working Capital Pressure” as entities. It records the relationship “Vendor A causes Delivery Delays” and “Delivery Delays increase Inventory Buffers,” which “increase Working Capital Pressure.” When the query is processed, the system performs a multi-hop traversal of the graph, allowing it to explain the causal chain to the user with a level of clarity that vector similarity cannot match.
Performance, Cost, and Maintenance Trade-offs
The decision to deploy one system over the other involves significant strategic trade-offs. Supporting data suggests that while GraphRAG offers superior accuracy for complex queries, it comes with a higher “Total Cost of Ownership” (TCO).

- Indexing Costs: GraphRAG requires significantly more LLM calls during the indexing phase to extract entities and relationships. This can make the initial setup 5 to 10 times more expensive than Vector RAG.
- Latency: Vector RAG is optimized for speed, often returning results in milliseconds. GraphRAG retrieval can be slower, especially if it involves complex graph traversals or the synthesis of multiple community summaries.
- Update Complexity: Vector databases are easily updated by adding new chunks. Updating a knowledge graph can be more difficult, as new information might change the relationships between existing entities, requiring a partial or full re-calculation of graph communities.
Broad Impact and Implications for the AI Sector
The shift toward hybrid models—combining Vector and Graph RAG—is becoming the preferred strategy for enterprise-grade AI. Industry analysts suggest that a “one-size-fits-all” approach to retrieval is no longer viable. For instance, a customer support bot might use Vector RAG to answer routine questions about product specifications but switch to GraphRAG to diagnose complex, multi-component technical failures.
The implications for data governance are also profound. GraphRAG requires a higher degree of data “cleanliness.” If a system incorrectly identifies two different “John Smiths” as the same person, the resulting knowledge graph will be flawed, leading to incorrect reasoning. This is driving a renewed interest in data quality and master data management (MDM) within the AI pipeline.

Furthermore, the “explainability” factor of GraphRAG is a major draw for regulated industries such as finance and healthcare. Because GraphRAG can point to specific nodes and edges to justify its answer, it provides a “paper trail” for its reasoning process. This transparency is much harder to achieve with the “black box” nature of vector embeddings.
Conclusion: The Path Toward Hybrid Intelligence
As the AI field matures, the “Vector vs. Graph” debate is likely to resolve into a collaborative framework. Vector RAG will remain the “fast-thinking” component of AI systems, handling simple lookups and semantic searches with unmatched efficiency. GraphRAG will serve as the “slow-thinking” or reasoning layer, providing the structural grounding and cross-document synthesis required for strategic decision-making.

The ultimate goal for organizations is not to choose the most complex technology, but to build a system that retrieves the right context to generate reliable, actionable answers. For most enterprises, the journey will begin with the simplicity of Vector RAG, with GraphRAG being integrated as the need for deeper reasoning and connectivity becomes apparent. In the high-stakes environment of corporate AI, the ability to understand not just what the data says, but how it is all connected, will be the true differentiator.