The rapid advancement of Large Language Models (LLMs) has highlighted a persistent technical bottleneck: the inability of artificial intelligence to maintain consistent, long-term memory across multiple interactions. While modern AI systems excel at processing immediate prompts, they frequently suffer from "contextual amnesia," forgetting past user preferences or requiring computationally expensive Retrieval-Augmented Generation (RAG) pipelines that depend on constant external data access. MemPalace has emerged as a disruptive open-source solution to this challenge, introducing a local-first, hierarchical memory framework designed to provide AI agents with structured, persistent, and high-precision recall.
The Problem of AI Amnesia and the RAG Limitation
Current AI memory solutions generally fall into two categories: short-term "buffer" memory and RAG-based long-term storage. Short-term memory is limited by the LLM’s context window, meaning the agent eventually "forgets" the beginning of a conversation as new messages arrive. Traditional RAG systems attempt to solve this by segmenting data into chunks, creating vector embeddings, and retrieving relevant snippets during inference. However, RAG often loses the nuanced "connective tissue" of a conversation because it prioritizes retrieval efficiency over context richness.
Furthermore, many agentic frameworks rely on LLM-driven summarization, where a model periodically condenses past interactions into brief reports. This process is inherently lossy; the LLM must decide what is "important" at a specific moment, often discarding subtle details that might become critical in future contexts. MemPalace addresses these deficiencies by adopting a "store everything" philosophy, maintaining a verbatim record of all messages while organizing them within a sophisticated spatial hierarchy.
The Architectural Foundation: The Method of Loci
The design of MemPalace is rooted in the ancient mnemonic technique known as the "Method of Loci" or the "Memory Palace." This technique involves associating information with specific physical locations in a visualized space to improve recall. MemPalace translates this concept into a digital multi-tiered framework:

- Wings: These represent the broadest category, typically designated for specific people or major projects.
- Rooms: Situated within Wings, Rooms are dedicated to specific topics or sub-projects, ensuring that context remains compartmentalized.
- Halls: These categorize the type of memory being stored, such as technical transcripts, personal preferences, or project requirements.
- Drawers: These serve as the storage units for raw, verbatim transcripts of messages and data.
- Closets: These are reserved for summaries or compressed versions of the data stored in Drawers, providing a "quick-look" capability without replacing the source material.
By using this hierarchical structure, MemPalace allows AI agents to navigate stored data with higher precision than flat vector databases, reducing the "noise" often encountered during large-scale retrieval.
Verbatim Memory vs. Lossy Summarization
A core differentiator of MemPalace is its rejection of immediate summarization. Tools like Mem0 or Zep typically analyze chat content to create essential fact sheets. While efficient for storage, this results in a loss of tone, sequence, and secondary details. MemPalace’s verbatim approach ensures that the original data remains intact.
This method provides three primary advantages:
- Traceability: Every response generated by an AI using MemPalace can be traced back to the exact message or data point in the history.
- Contextual Integrity: By keeping the raw text, the system preserves the evolution of a project or a user’s thought process over time.
- Superior Reasoning: When an agent has access to the full transcript rather than a summary, it can perform more complex cross-referencing and deductive reasoning.
Technical Implementation and Ingestion Pipeline
The MemPalace pipeline operates through a dual-action mechanism: "Writing Memory" for ingestion and "Reading Memory" for retrieval. During data ingestion, the system monitors every turn of a conversation, capturing user messages, AI responses, and associated metadata.
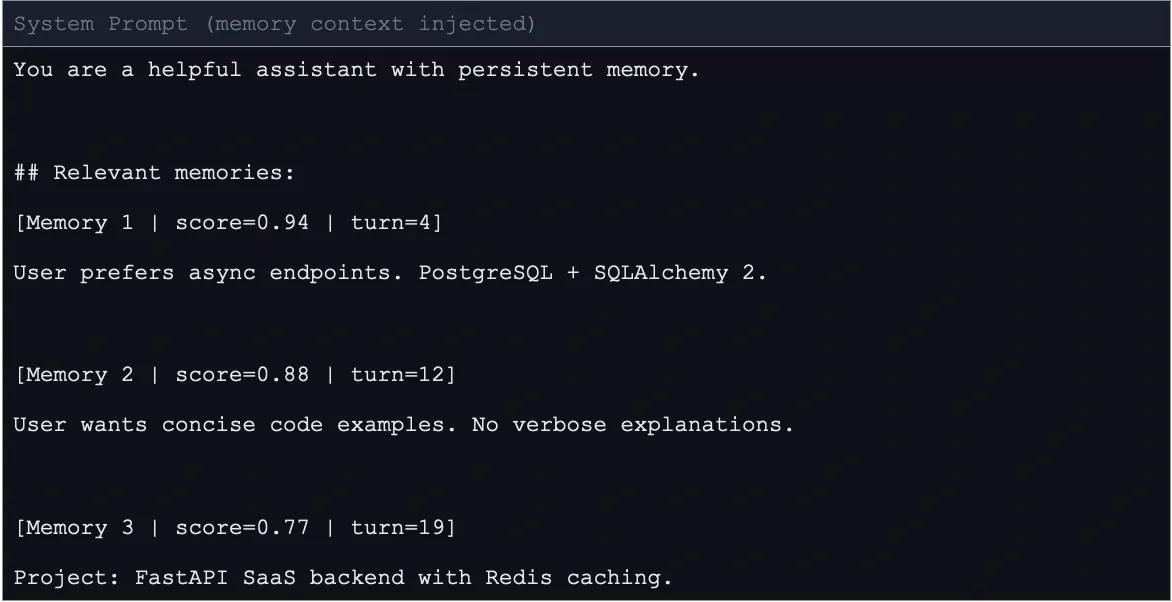
The indexing process utilizes a sentence-transformer model to convert raw text into high-dimensional numerical vectors. These vectors are stored in ChromaDB, an open-source vector database, alongside the original text. To maintain performance, MemPalace utilizes a query-time retrieval and ranking system. When a user sends a message, it is transformed into a query vector. The system then searches ChromaDB for the most similar entries, applying a strict similarity threshold (typically 0.70 or higher) to ensure only highly relevant memories are injected into the LLM’s prompt.
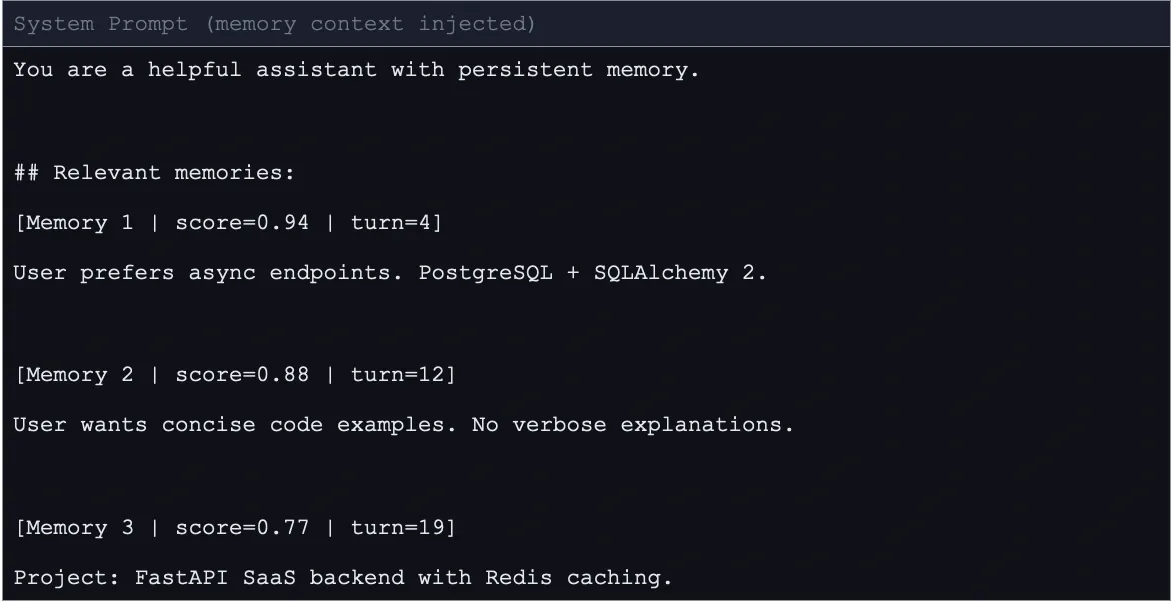
To address the potential for "token bloat"—where the history becomes too large for the model to process—MemPalace introduces an optional compression mechanism called AAAK. This functions as a lossy shorthand system using regular expressions to transform words into abbreviations and extract key sentences. This mechanism can achieve an approximately 30-fold reduction in token usage while maintaining the core logic of the data.
Integrating MemPalace within Agentic Frameworks (LangGraph)
For developers building sophisticated AI agents, MemPalace integrates seamlessly with LangGraph, a library for building stateful, multi-actor applications with LLMs. In a LangGraph implementation, MemPalace operates through specialized nodes within a state machine.
Step 1: Environment Setup and Configuration
Integration begins with the installation of mempalace, langgraph, chromadb, and sentence-transformers. Developers configure environment variables to define the database path, the collection name, and the specific embedding model (such as all-MiniLM-L6-v2).
Step 2: Initialization
The system initializes a persistent ChromaDB client. If a memory collection already exists, MemPalace loads it; otherwise, it creates a new one. This ensures that memory persists even after the application is restarted.
Step 3: Node Definition
In a standard LangGraph flow, the process follows a specific chronology:
- Retrieval Node: This node activates before the chat node. it takes the most recent human message, searches the "Palace" for relevant past interactions, and formats them into a "memory context" block.
- Chat Node: The AI receives the current message along with the "memory context" injected into the system prompt. This allows the LLM to "remember" previous sessions without having the entire history in its active window.
- Auto-Save Node: After a set number of turns (e.g., every 15 messages), a conditional edge triggers the saving node. This node writes the recent batch of messages to ChromaDB with session IDs, roles, and timestamps.
- Summarization Node: Once the "Palace" exceeds a certain size threshold (e.g., 50 documents), the system can trigger an LLM-based summarizer to compress the oldest raw chunks into a single summary, deleting the originals to optimize storage while preserving the "essence" of the interaction.
Comparative Analysis: MemPalace vs. Traditional Systems
When compared to standard RAG pipelines and commercial agent memory frameworks, MemPalace offers distinct advantages in organization and control:
| Aspect | RAG Pipelines | Vector Databases | MemPalace |
|---|---|---|---|
| Primary Function | Static document retrieval (PDFs/Wikis). | Flat storage for similarity search. | Persistent, structured dialogue memory. |
| Temporal Context | Low; struggles with conversation flow. | None; treats all data as equal points. | High; tracks turns, sessions, and roles. |
| Data Structure | Segmented chunks. | Unstructured embeddings. | Hierarchical (Wings, Rooms, Halls). |
| User Privacy | Often cloud-dependent. | Varies by provider. | Local-first; full user control. |
The Future of Context-Aware AI
The emergence of MemPalace signifies a broader shift in the AI industry toward "permanent agents"—systems that do not start from zero with every new session. By providing a local-first alternative to paid services like Letta or specialized cloud memory APIs, MemPalace empowers developers to build privacy-centric assistants capable of long-term learning.
Future iterations of the system are expected to integrate with the Model Context Protocol (MCP), allowing MemPalace to act as a standardized memory layer across different AI tools and platforms. As AI agents move from being simple task-executors to becoming long-term collaborators, the ability to maintain a "verbatim" yet "organized" memory will be the defining characteristic of a truly intelligent system.
Conclusion
MemPalace establishes a new benchmark for AI memory by prioritizing the preservation of full user experiences over lossy summarization. Its hierarchical design allows for a more "human-like" organization of information, while its integration with tools like LangGraph and ChromaDB provides a robust path for developers to implement long-term recall. By solving the persistent problem of AI amnesia through a structured, local-first approach, MemPalace marks a significant step toward the realization of autonomous agents that truly understand and remember their users.