The landscape of open-weight artificial intelligence has reached a significant milestone with the release of Google’s Gemma 4, specifically regarding its native support for structured tool calling. While previous generations of language models were largely confined to the data contained within their training sets, Gemma 4 introduces a robust mechanism for interacting with the physical and digital world in real-time. By enabling a model to recognize when a query requires external data—such as current weather, stock prices, or database entries—and allowing it to generate the precise parameters needed to invoke a local Python function, Google has effectively bridged the gap between passive text generation and active agentic behavior. When combined with the Ollama framework for local execution, this capability allows developers to build sophisticated, non-cloud-dependent AI agents that maintain data privacy and eliminate subscription costs.
The Evolution of Agentic AI: From Hallucination to Verification
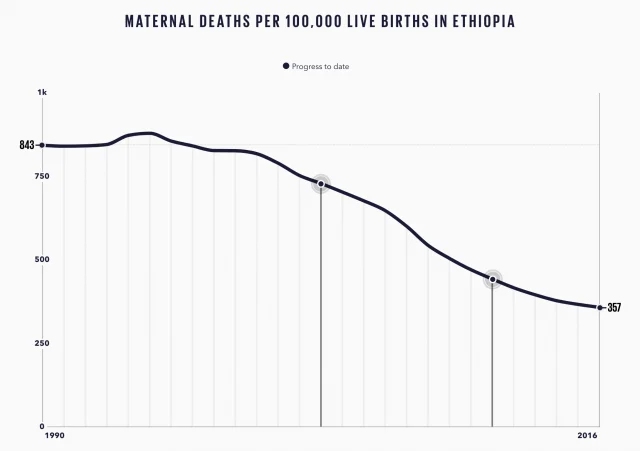
For years, the primary limitation of conversational AI has been its "knowledge cutoff." Large Language Models (LLMs) are static snapshots of information; if a model was trained in 2023, it cannot inherently know the weather in Tokyo today or the current exchange rate of the Indian Rupee. Historically, users attempted to solve this by providing "context" via Retrieval-Augmented Generation (RAG). However, RAG is often limited to static documents.
Function calling, or "tool use," represents the next stage of this evolution. Instead of the model guessing or "hallucinating" an answer based on outdated patterns, it acts as a reasoning engine. It identifies that it lacks specific information, selects an appropriate tool from a provided list, and formats a request to that tool. This architectural shift transforms the AI from a simple oracle into the "brain" of a system, where external functions serve as the "hands" that interact with the world.
Google’s Gemma 4 distinguishes itself in this arena through its high degree of reliability in producing structured JSON output. In the world of programming, a single missing comma or a mismatched bracket in a tool call can cause an entire system to crash. Gemma 4 has been specifically fine-tuned to adhere to rigid schemas, making it one of the most capable open-weight models for autonomous agentic workflows.

The Architecture of Local Tool Calling
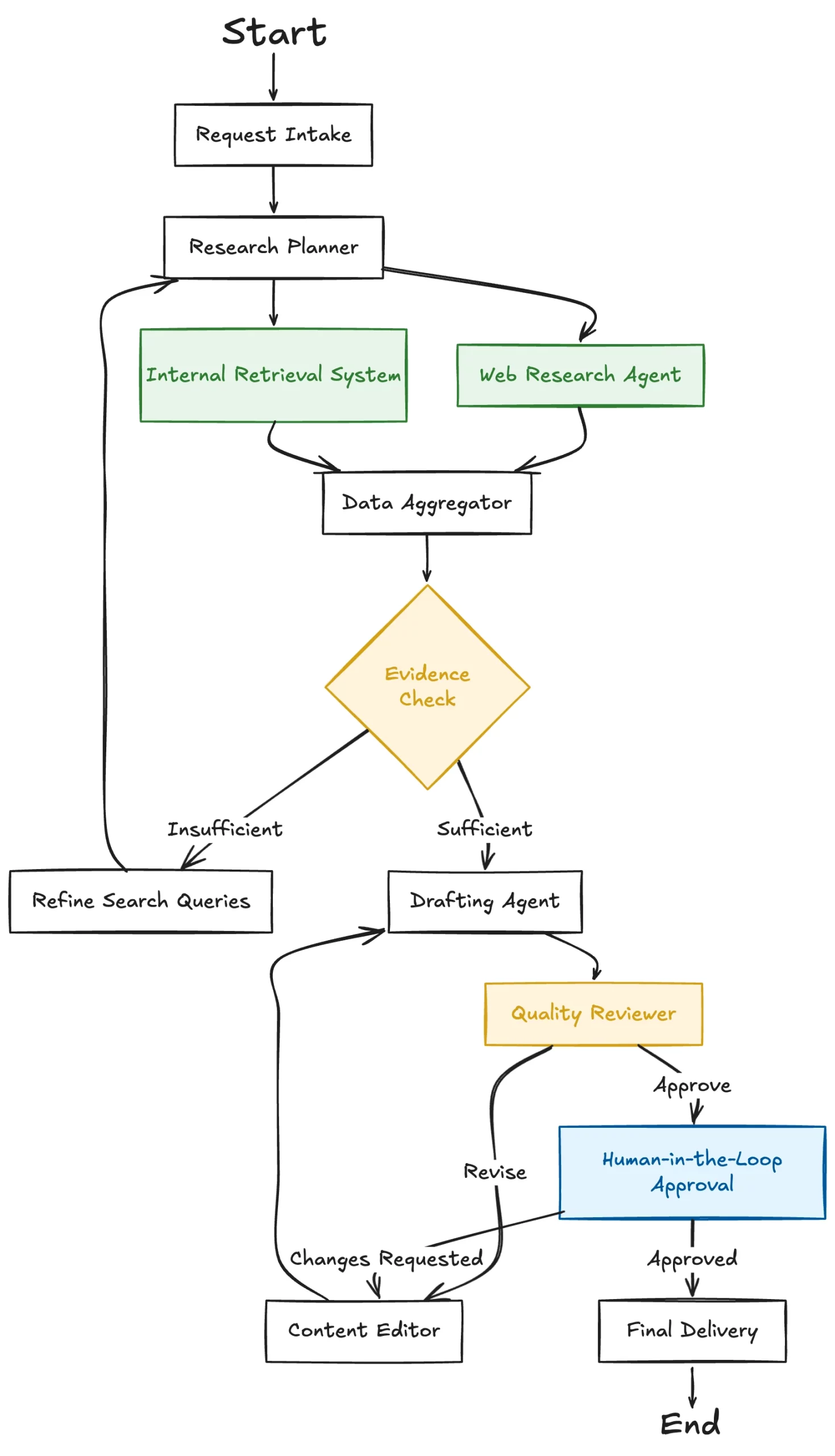
Understanding the lifecycle of a tool call is essential for developers looking to implement these systems. The process follows a "two-pass" pattern that ensures the model remains the coordinator while the local environment remains the executor.
- The Intent Phase: The user submits a natural language query (e.g., "What is the current time in London?").
- The Tool Identification Phase: The model analyzes the query against a list of available "tool schemas" provided by the developer. It recognizes that a specific function—such as
get_current_time—is required. - The Argument Generation Phase: The model generates a structured JSON object containing the necessary arguments (e.g.,
"city": "London"). It then pauses its generation. - The Local Execution Phase: The developer’s local code receives this JSON, executes the actual Python function, and fetches the data from an API or database.
- The Feedback Phase: The result of the function is sent back to the model as a "tool role" message.
- The Synthesis Phase: The model receives the raw data, interprets it, and composes a natural language response for the user.
This loop ensures that the AI model never actually "runs" the code itself—a critical security feature. The model merely suggests the call; the user’s local environment maintains full control over what code is executed and what data is accessed.
Setting Up the Local Environment with Ollama
To implement these features without relying on cloud providers, developers are increasingly turning to Ollama, an open-source project that simplifies the deployment of LLMs on local hardware. For this implementation, the Gemma 4 Edge 2B (E2B) model is particularly effective due to its small footprint (approximately 2.5 GB) and optimized performance on consumer-grade hardware.
The installation process begins with the deployment of Ollama via a standard terminal command:
# Install Ollama (macOS/Linux)
curl --fail -fsSL https://ollama.com/install.sh | sh Once Ollama is running, the Gemma 4 model must be pulled to the local machine:

# Download the Gemma 4 Edge Model
ollama pull gemma4:e2bTo facilitate communication between Python and the local AI instance, a simple helper function using Python’s standard library can be used to send requests to the Ollama API, which resides by default at http://localhost:11434.
Hands-on Implementation: Real-World Scenarios
To demonstrate the power of Gemma 4’s tool calling, three distinct tasks highlight the model’s ability to handle live data, complex calculations, and multi-intent queries.
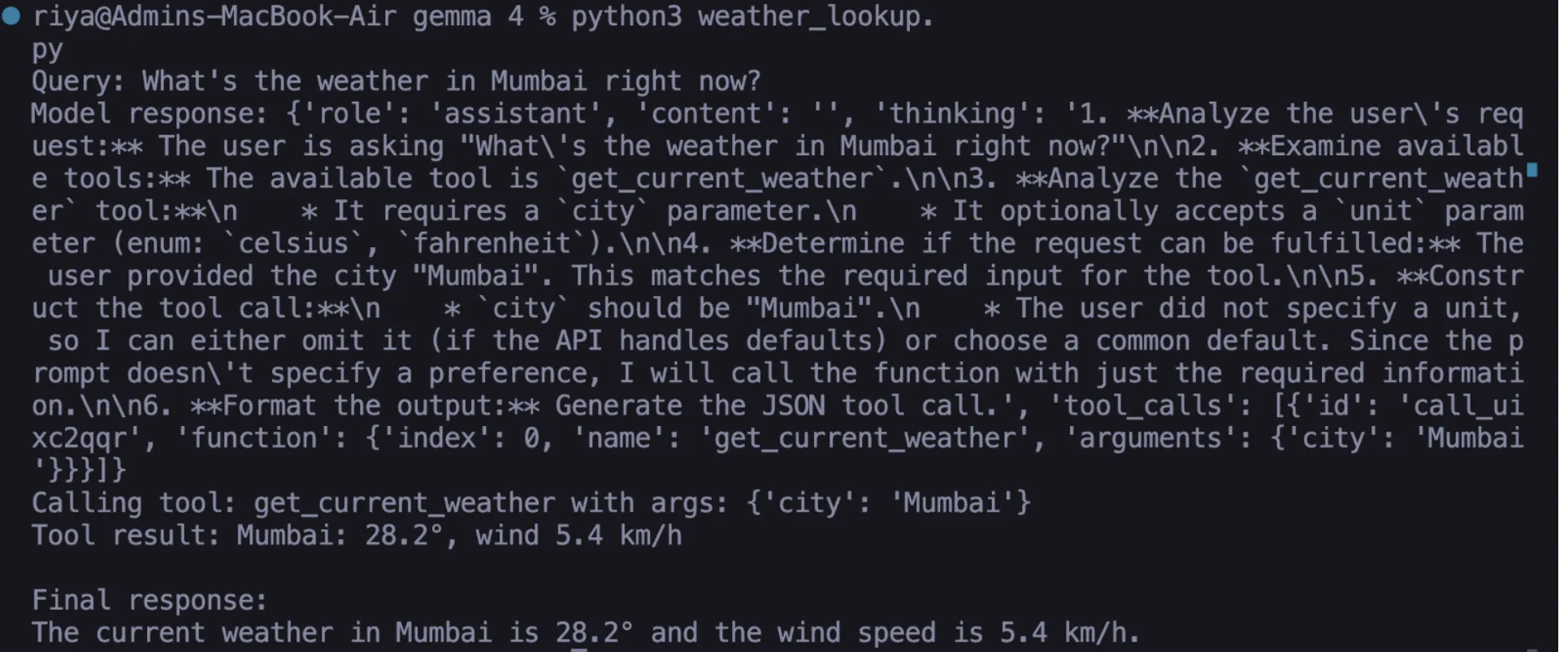
Task 1: Live Weather Integration
Using the Open-Meteo API, which requires no API key, a developer can create a function that fetches real-time meteorological data. The Python function handles the geocoding (converting a city name to coordinates) and the subsequent weather lookup. Crucially, the developer must define a JSON schema that tells Gemma 4 exactly what parameters the function expects, such as the "city" string and the "unit" (Celsius or Fahrenheit). When a user asks about the weather, Gemma 4 populates this schema, the Python script runs the API call, and the model reports the live temperature and wind speed.
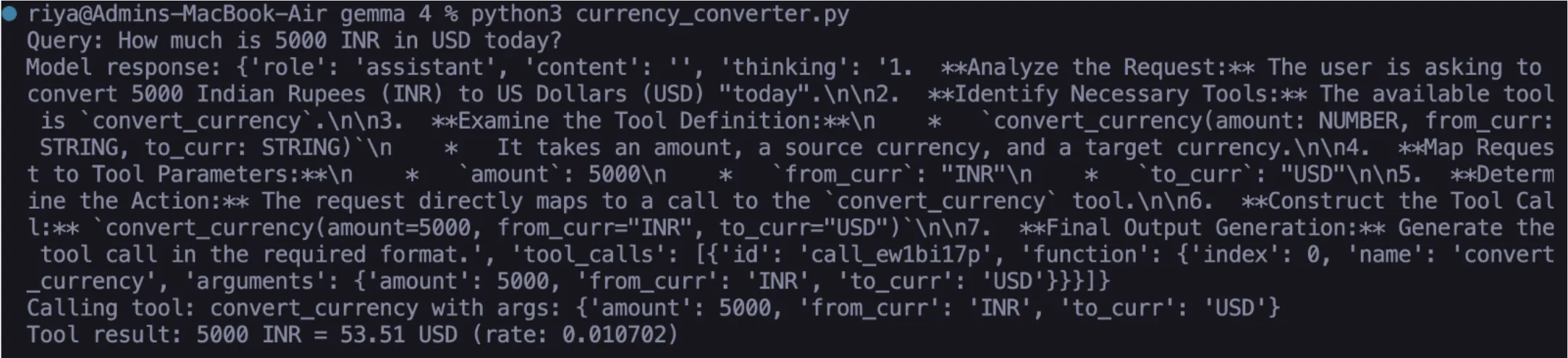
Task 2: Accurate Currency Conversion
LLMs are notoriously poor at math and lack access to fluctuating financial markets. By connecting Gemma 4 to an exchange rate API, the model can provide precision that was previously impossible. When a user asks, "How much is 5,000 INR in USD today?", the model recognizes the source currency, the target currency, and the amount. It generates the tool call, the local script fetches the latest rate, and the model delivers a response that is factually grounded in current market conditions rather than training data.
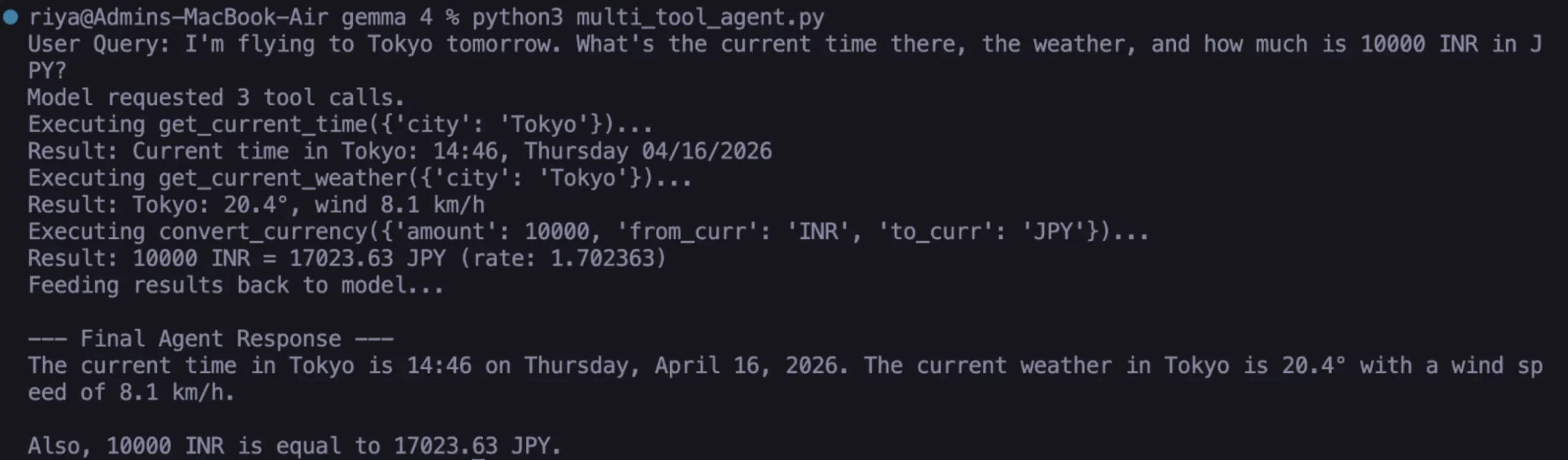
Task 3: The Multi-Intent Agent
The true strength of Gemma 4 lies in its ability to handle "compound queries." A user might say: "I’m flying to Tokyo tomorrow; what’s the current time there, what’s the weather, and what is the conversion for 10,000 INR to JPY?"
In this scenario, Gemma 4 generates multiple tool calls in a single response. The local agent loop iterates through these calls, executes the corresponding functions for time, weather, and currency, and feeds all results back to the model. The model then synthesizes this disparate data into a coherent, helpful itinerary for the user.
Why Gemma 4 Changes the Paradigm for Edge AI
The transition of tool-calling capabilities from proprietary models like GPT-4 to open-weight models like Gemma 4 has profound implications for the industry.
1. Data Sovereignty and Privacy: In industries such as healthcare, legal, and finance, sending data to a third-party cloud provider for processing is often a deal-breaker due to regulatory requirements (like HIPAA or GDPR). Gemma 4 allows these organizations to keep their data—and the tools that interact with it—entirely within their own firewalls.
2. Cost Efficiency: High-volume AI agents can incur significant costs when using pay-per-token cloud APIs. By running Gemma 4 locally on edge devices or internal servers, the marginal cost of a query drops to the cost of electricity.
3. Latency and Reliability: Local execution eliminates the "round-trip" time to a cloud server and removes dependency on an internet connection for core logic. For industrial IoT applications or remote research, this reliability is paramount.
4. Schema Adherence: Early attempts at open-weight tool calling often resulted in "hallucinated" JSON—output that looked like code but contained syntax errors. Google’s fine-tuning of Gemma 4 has prioritized "structured output," ensuring that the model’s responses are consistently machine-readable.
Broader Impact and Future Implications
The ability for small, 2-billion parameter models to perform complex tool calling signals a shift toward "Micro-Agents." We are moving away from a single, monolithic AI that knows everything, toward a swarm of specialized, local agents that do everything.
Experts in the field suggest that the next step for Gemma 4 and its successors will be "recursive tool use," where a model can call a tool, look at the result, and decide it needs to call another tool to complete the task. This would allow for even more autonomous problem-solving, such as an AI agent that can not only look up a flight but also interact with a local calendar to suggest the best booking time and then draft a confirmation email.
The release of Gemma 4 with native tool calling is more than just a technical update; it is a democratization of AI agency. It provides the building blocks for developers to create tools that are not just conversational, but functional. As the open-weight ecosystem continues to evolve, the reliance on centralized AI providers will likely diminish, giving way to a more distributed, private, and capable era of local intelligence. For developers, the message is clear: the "brain" is now ready, and it is time to start building the "hands."