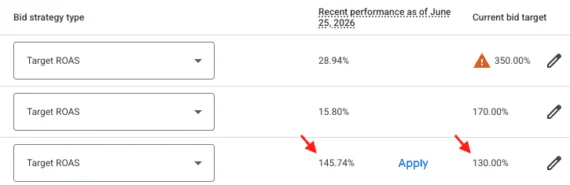
The practice of A/B testing has become the cornerstone of data-driven decision-making in the modern digital economy, yet a growing body of evidence suggests that a significant portion of these experiments is compromised by a phenomenon known as p-hacking. This practice, whether intentional or accidental, involves the manipulation of experimental data until statistical significance is achieved, often leading organizations to implement changes that provide no real value or, in worse cases, actively harm the user experience. As businesses increasingly rely on experimentation to drive growth, the need for rigorous statistical guardrails has moved from a technical preference to a commercial necessity.

At its core, p-hacking is a byproduct of Goodhart’s Law, which states that when a measure becomes a target, it ceases to be a good measure. In the context of conversion rate optimization (CRO) and product experimentation, when the primary objective shifts from gaining genuine insights to simply "finding a winner," the integrity of the data is often the first casualty. Testers, under pressure to show results, may succumb to various forms of data "torturing" until the numbers yield a favorable p-value. This creates a false sense of progress, where random noise is misinterpreted as a significant causal effect.
The Statistical Reality of False Discoveries
The scale of the p-hacking problem was highlighted in a comprehensive 2018 analysis of 2,101 commercially run A/B tests. The study revealed a staggering statistic: approximately 57% of experimenters engaged in p-hacking behaviors once their results reached a 90% confidence level. This behavior has a direct and measurable impact on the False Discovery Rate (FDR) of an experimentation program. Under normal conditions with a 90% confidence threshold, the FDR typically sits around 33%. However, for those who engage in p-hacking, that rate climbs to 42%.

This means that in programs where p-hacking is prevalent, nearly half of all reported "wins" are actually false positives. For a global enterprise, rolling out a false positive can lead to millions of dollars in lost revenue and significant technical debt. Sundar Swaminathan, author of the experiMENTAL newsletter, notes that p-hacking is particularly dangerous because it cloaks random fluctuations in the guise of significant results. According to Swaminathan, stopping experiments prematurely after seeing a favorable p-value is essentially cherry-picking data to support a pre-existing hypothesis while ignoring the fundamental laws of statistics. This jeopardizes not only individual test results but the credibility of the entire experimentation department.
The Chronology of Data Compromise
P-hacking does not occur in a vacuum; it typically creeps into the experimentation workflow at specific, identifiable stages. Understanding this timeline is essential for organizations looking to build more resilient testing cultures.
Phase 1: Pre-Experiment Planning and Metric Selection
The risk of p-hacking often begins before the first visitor is even assigned to a variant. Failure to pre-calculate the required sample size and test duration is a primary driver of future bias. Without a fixed horizon, testers are more likely to "peek" at results and stop the test as soon as the p-value dips below the 0.05 threshold. Furthermore, the failure to define a single primary metric leads to "metric switching" or "Texas sharpshooting," where a tester looks at twenty different secondary metrics and chooses the one that happened to perform well by chance.
Phase 2: The Mid-Experiment "Peeking" Problem
During the execution of the test, the most common form of p-hacking is repeated significance testing. In a standard frequentist A/B test, the statistical assumptions require the test to run until the pre-calculated sample size is reached. However, digital dashboards allow for real-time monitoring. Every time a tester checks the p-value before the test is complete, they increase the probability of a Type I error (a false positive). If a test is stopped the moment it looks "green," the tester is essentially catching the data during a temporary, random fluctuation.
Phase 3: Post-Experiment Data Slicing
After a test concludes without a significant result, the temptation to "find a win" remains. This often manifests as post-test segmentation. While analyzing segments (such as mobile vs. desktop) is valuable for generating new hypotheses, reporting a win based on a specific sub-segment after the original test failed is a classic p-hacking move. If you slice data into enough pieces, one of them will eventually show a significant result due to pure chance.
Advanced Mitigation Strategies and Technical Guardrails
To combat the erosion of data integrity, modern experimentation platforms like Convert Experiences have integrated automated statistical guardrails. These tools are designed to enforce discipline and remove the human element of temptation from the analysis process.
1. Implementation of Multiple Comparison Corrections
When testing multiple variants against a control, the probability of finding a false winner increases exponentially. To mitigate this, statisticians use corrections such as the Bonferroni or Sidak methods. The Bonferroni correction is the most conservative, adjusting the significance threshold by dividing it by the number of variants. The Sidak correction is often preferred for mission-critical experiments as it maintains more statistical power than Bonferroni while still strictly controlling the family-wise error rate.
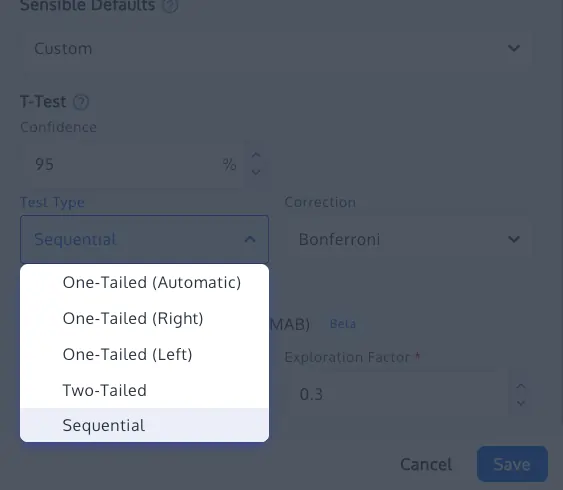
2. Adoption of Sequential Testing Frameworks
One of the most effective ways to allow for "peeking" without compromising integrity is the shift toward sequential testing. Based on the research of Waudby-Smith et al. (2023), sequential testing uses "always-valid" p-values. This mathematical framework allows testers to monitor results in real-time and stop tests early if a result is found, without inflating the Type I error rate. This provides a bridge between the need for speed in business and the need for rigor in science.
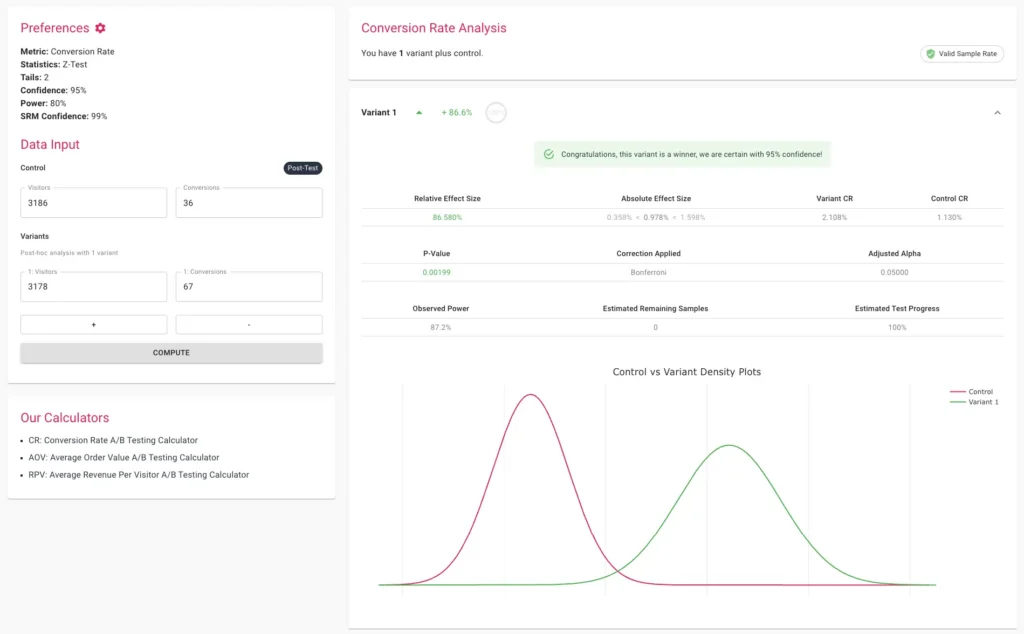
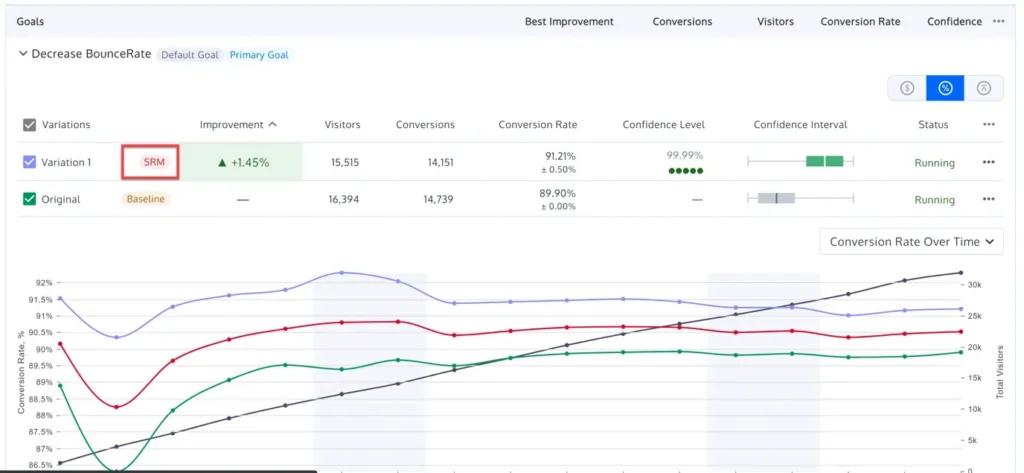
3. Sample Ratio Mismatch (SRM) Detection
Even a perfectly designed test can be invalidated by technical errors. A Sample Ratio Mismatch (SRM) occurs when the actual distribution of visitors between the control and variants does not match the intended allocation (e.g., a 50/50 split resulting in 48/52). This is often a sign of a tracking bug, bot interference, or redirect issues. Modern platforms now include built-in SRM checks using Chi-square goodness-of-fit tests. If an SRM is detected, the results are considered fundamentally unreliable, regardless of how high the "uplift" appears to be.
4. The Role of Multi-Armed Bandits (MAB)
In scenarios where the goal is rapid optimization rather than causal proof—such as a short-term holiday promotion—Multi-Armed Bandit algorithms offer an alternative. MAB dynamically reallocates traffic toward the winning variant while the test is still running. While this is not a substitute for classical A/B testing (as it does not provide the same level of statistical proof), it reduces the "regret" of sending traffic to losing variants and bypasses the p-hacking issues associated with fixed-horizon testing.
Expert Reactions and Organizational Implications
Industry leaders are increasingly vocal about the cultural shifts required to support these technical safeguards. The consensus among senior data scientists is that a "win at all costs" culture is the primary driver of p-hacking. Organizations that reward testers solely based on the number of "winning" experiments they produce are inadvertently incentivizing data manipulation.
Instead, leading firms are moving toward a "learning-centric" model. In this framework, an experiment that proves a hypothesis wrong is considered just as valuable as one that proves it right, provided the data is clean. This shift requires transparency in logging; every analysis, every segment explored, and every metric tracked must be documented to prevent the selective reporting of favorable outcomes.

The broader implications of p-hacking extend beyond individual company balance sheets. As the digital ecosystem becomes more interconnected, the proliferation of false "best practices" based on p-hacked data can lead to industry-wide stagnation. When dozens of companies implement a specific UI change because it was reported as a "winner" in a flawed case study, the collective user experience can suffer.
Conclusion: The Path Forward for Experimentation Programs
The prevention of p-hacking requires a dual approach: the adoption of sophisticated statistical tools and the cultivation of a disciplined experimentation culture. By pre-calculating sample sizes, defining clear primary metrics, and utilizing modern techniques like sequential testing and SRM checks, organizations can protect themselves from the lure of false positives.
In an era where data is often called the "new oil," its value is entirely dependent on its refinement and the integrity of the processes used to extract insights from it. As experimentation programs mature, the focus must shift from the quantity of tests to the quality of the evidence. Only through rigorous adherence to statistical guardrails can businesses transform their testing programs from "winner-finding machines" into genuine engines of insight and sustainable growth. The credibility of the CRO industry depends on this transition from intuitive "peeking" to disciplined, automated rigor.