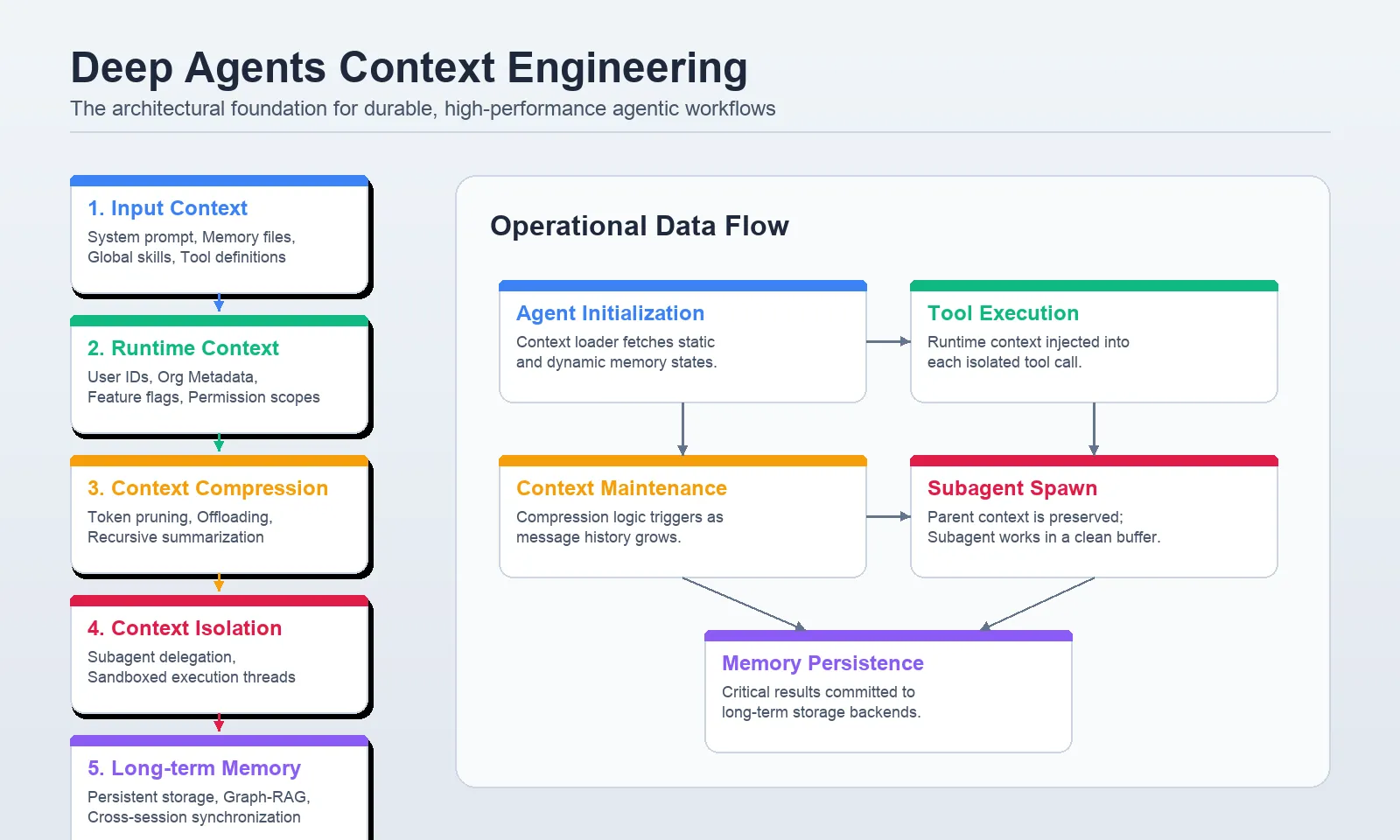
The evolution of artificial intelligence has transitioned from simple chat interfaces to "Deep Agents"—autonomous systems capable of multi-step planning, tool utilization, and complex state management. While the raw reasoning power of large language models (LLMs) provides the engine for these agents, their real-world performance is increasingly dictated by context engineering. Without a structured approach to managing information, even the most sophisticated agents succumb to "context drift," where messy memory, irrelevant input, or excessive token usage leads to hallucinations, increased latency, and prohibitive operational costs. To address these challenges, a new architectural standard has emerged, organizing agentic context into five distinct layers: input context, runtime context, compression, isolation, and long-term memory.

The Evolution of Agentic Reasoning and the Context Bottleneck
In the early stages of generative AI deployment, developers focused primarily on prompt engineering—the art of refining a single input to elicit a better response. However, as agents began performing longer tasks, such as managing software projects or conducting multi-source research, the "single-prompt" model failed. The industry observed a sharp degradation in performance as conversation histories grew. This phenomenon, often referred to as "lost in the middle," occurs when an LLM fails to retrieve relevant information buried within a massive context window.
Furthermore, the economic implications of poor context management are significant. Modern LLMs charge per token, and feeding an agent thousands of lines of irrelevant historical data for every sub-task results in exponential cost increases. Deep Agents solve this by treating context not as a static block of text, but as a dynamic, layered resource. By implementing the create_deep_agent Python interface, developers can now programmatically control how an agent perceives, stores, and forgets information.
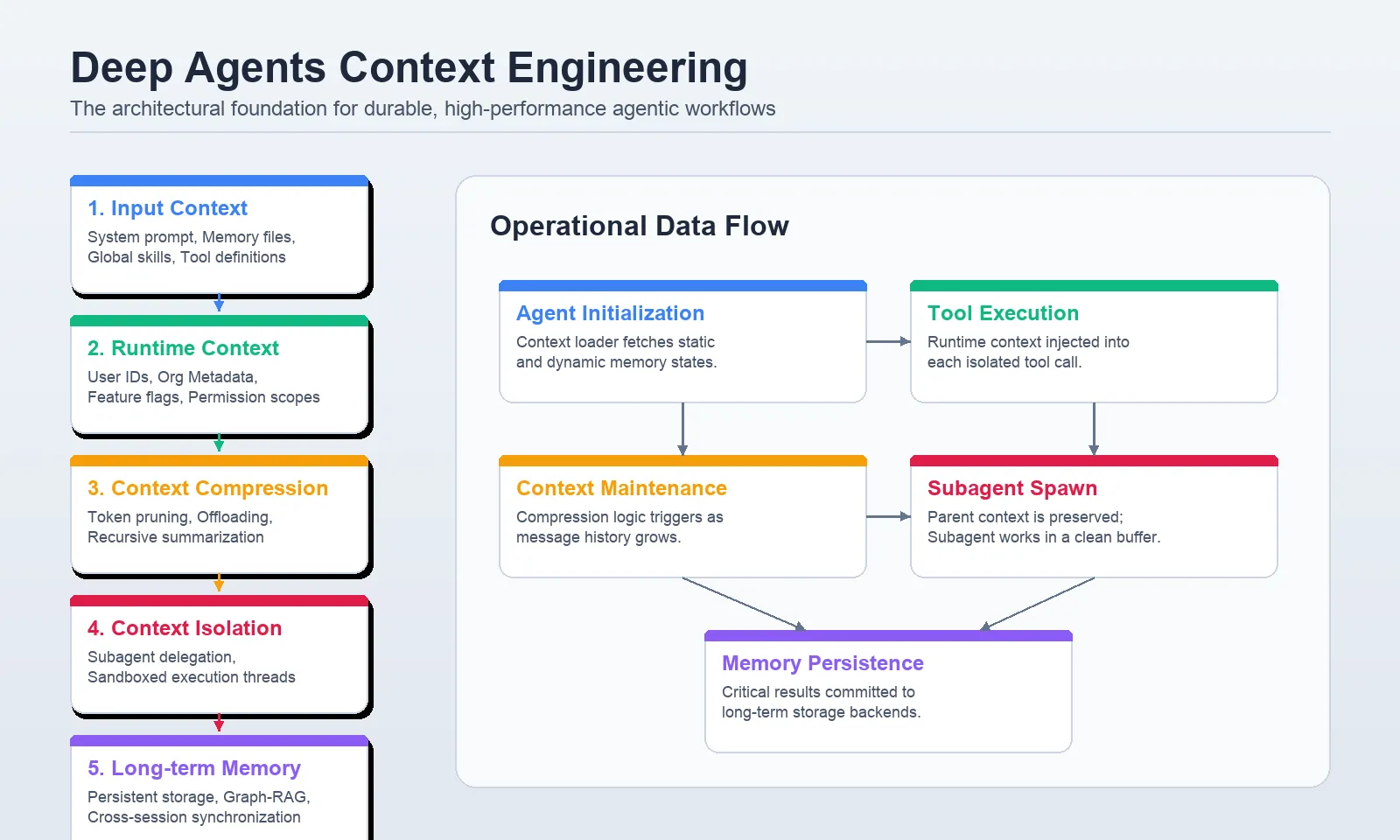
Layer 1: Input Context and the Architecture of Identity
The first layer, input context, defines the agent’s "factory settings." Unlike a standard chat prompt, input context in Deep Agents is a composite of several high-signal components. This includes the core system prompt, which establishes identity and behavioral boundaries, and specialized files such as AGENTS.md and SKILL.md.
In professional deployments, developers are moving away from hard-coding instructions into strings. Instead, they utilize a "progressive disclosure" model. For instance, an agent might have access to a library of "Skills"—reusable workflows for specific tasks like "Weekly Reporting" or "Code Review." The framework only loads the full body of a skill when the agent determines it is relevant to the user’s request. This design ensures that the model’s reasoning capacity is not wasted on instructions it does not currently need.
Supporting data from recent benchmarks indicates that agents utilizing progressive disclosure see a 30% improvement in task accuracy compared to those with "flat" system prompts. By keeping the initial system prompt focused strictly on identity and delegating workflows to skill files, developers create a cleaner "reasoning space" for the model.
Layer 2: Runtime Context and Operational Security
Runtime context represents the data passed during the moment of invocation. Crucially, this information is often kept separate from the model’s direct view. In a secure enterprise environment, runtime context includes sensitive identifiers such as User IDs, Organization IDs, and database connection strings.
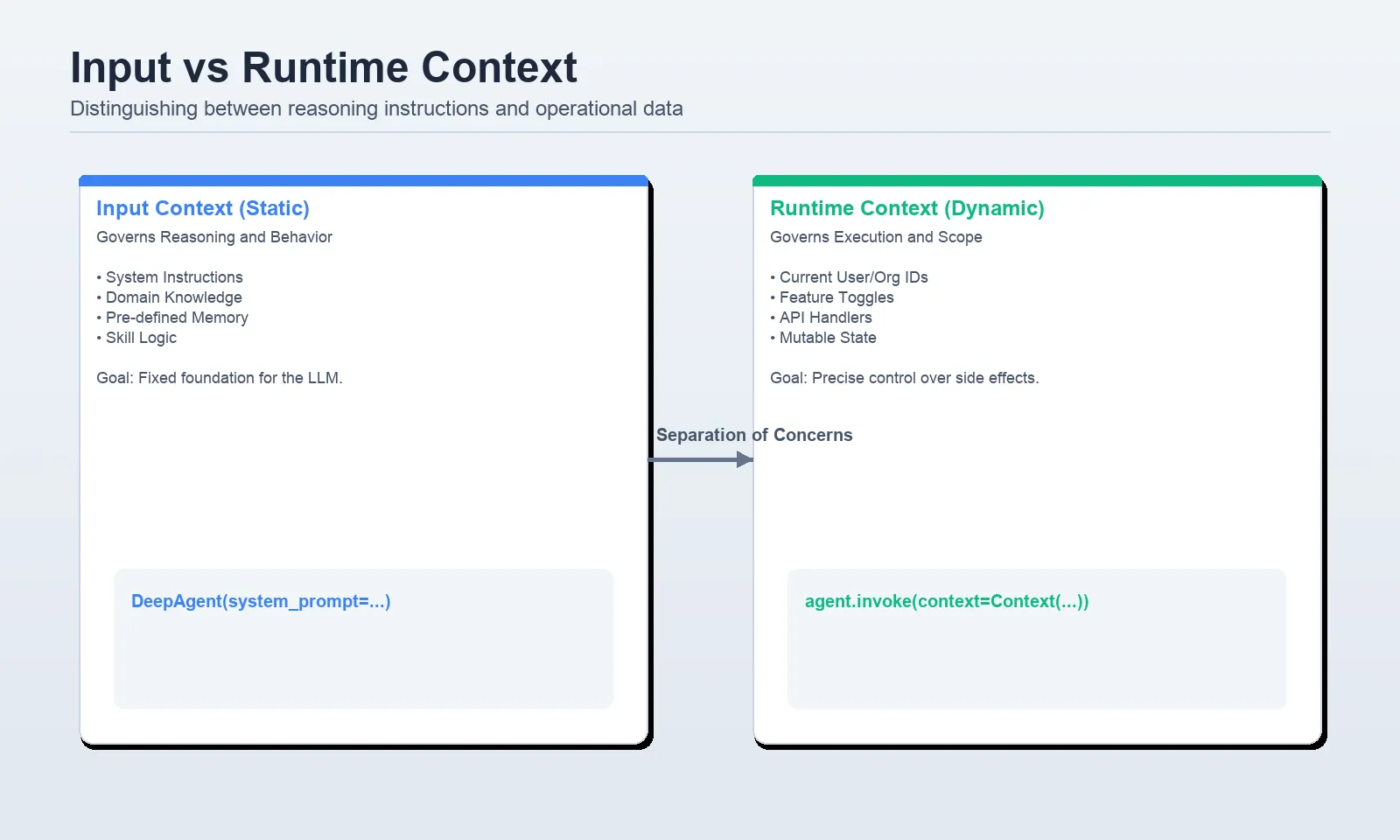
The primary innovation in this layer is the use of ToolRuntime. When an agent calls a tool—for example, a function to fetch a user’s tasks—it does not need the LLM to "know" the database password. Instead, the tool reads the password from the runtime context, executes the query, and returns only the filtered results to the model. This creates a "clean cut" between reasoning and execution, significantly enhancing security and reducing the risk of prompt injection attacks where a user might attempt to trick the model into revealing internal configuration data.
Layer 3: Context Compression and the Economics of Scale
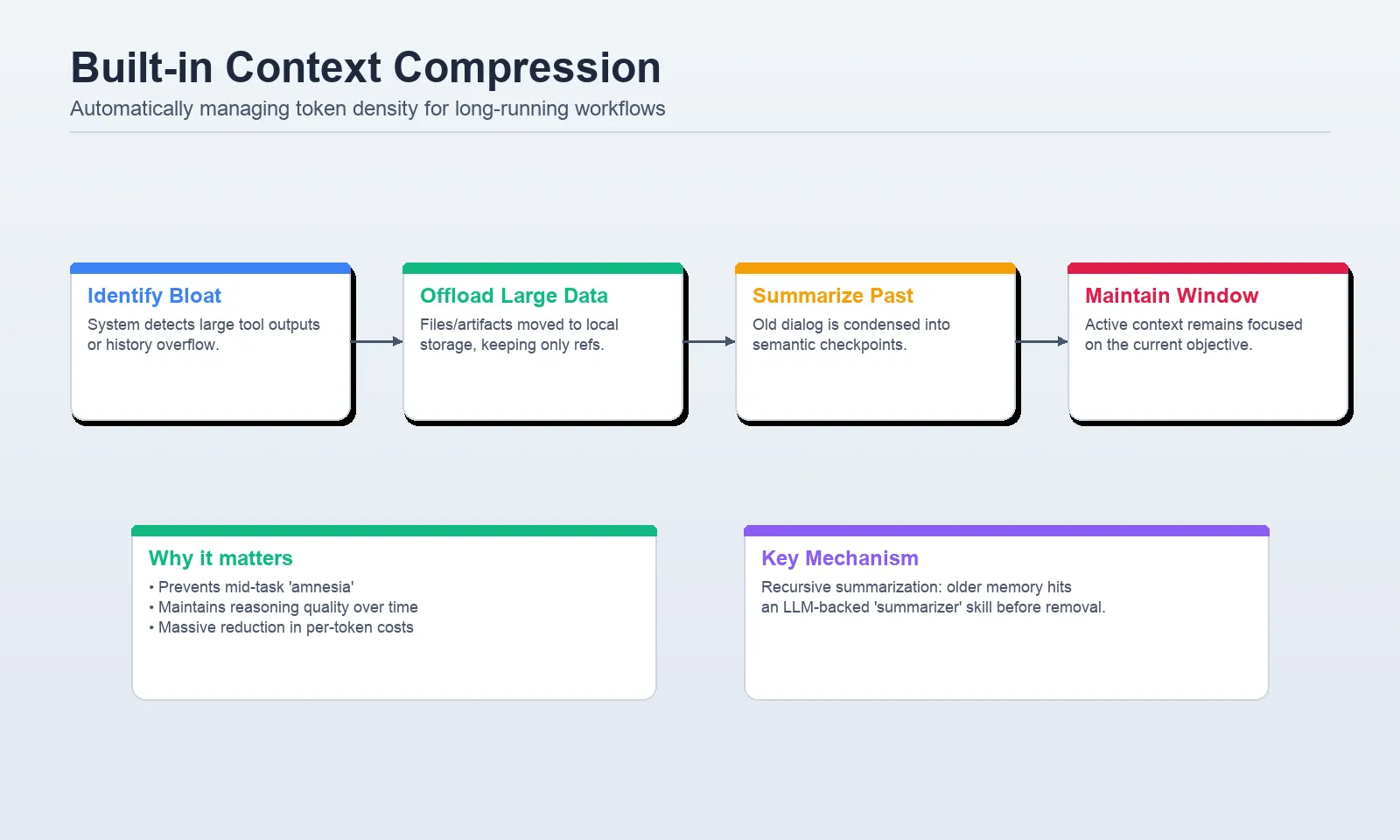
As tasks progress, agents generate massive amounts of data, particularly when interacting with external APIs or processing large documents. Layer 3, context compression, addresses the physical limits of the LLM’s context window through two primary mechanisms: offloading and summarization.

Content offloading occurs when tool outputs exceed a specific threshold, typically 20,000 tokens. Rather than clogging the chat history with a massive raw data dump, the Deep Agents framework persists the data to a virtual filesystem and provides the agent with a concise reference. If the agent needs to revisit specific details later, it can "read" the file on demand.
Summarization acts as the second line of defense. When an agent nears its token limit, internal middleware triggers a "logical checkpoint." Instead of simply cutting off the oldest messages (which might contain critical instructions), the system generates a high-density summary of the conversation to date. This ensures the agent maintains a "working set" of information that is always relevant to the current objective.
Layer 4: Context Isolation Through Subagent Delegation
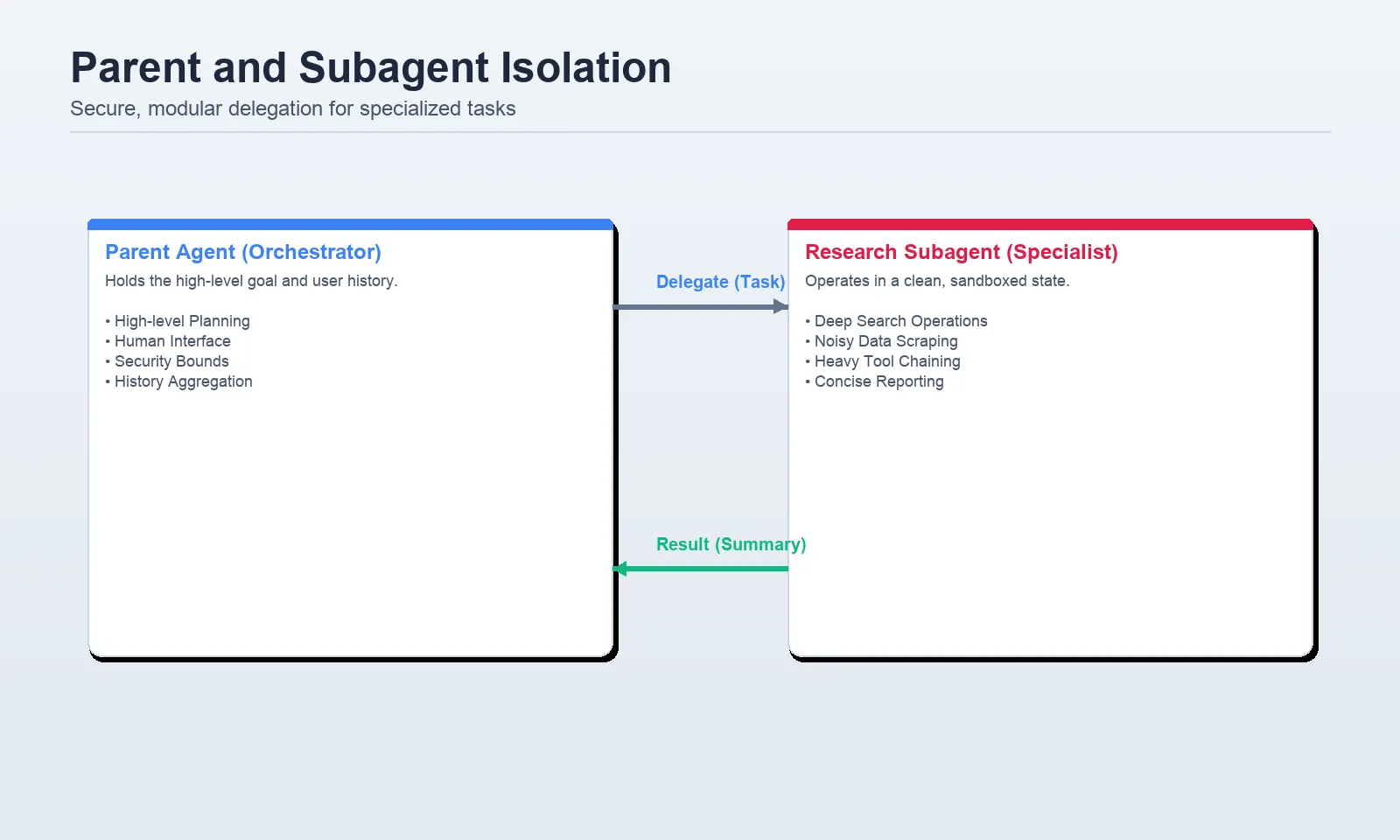
One of the most effective ways to manage complex context is to not manage it all in one place. Context isolation involves spinning up "subagents" to handle specific, data-heavy tasks. This is analogous to a CEO delegating a deep-dive research task to a specialized department.
When a parent agent delegates to a subagent, it creates a fresh context window. The subagent can ingest thousands of lines of research, process them, and return a 200-word summary to the parent. This isolation prevents the parent’s memory from being "polluted" by the raw, messy details of the research process.

Industry analysts note that this hierarchical structure is becoming the standard for enterprise-grade AI. By confining specific toolsets and model requirements to subagents, organizations can use cheaper, faster models (like GPT-4o-mini) for sub-tasks while reserving high-intelligence models for the "orchestrator" parent agent, leading to cost savings of up to 60% in complex workflows.
Layer 5: Long-Term Memory and Cross-Session Persistence
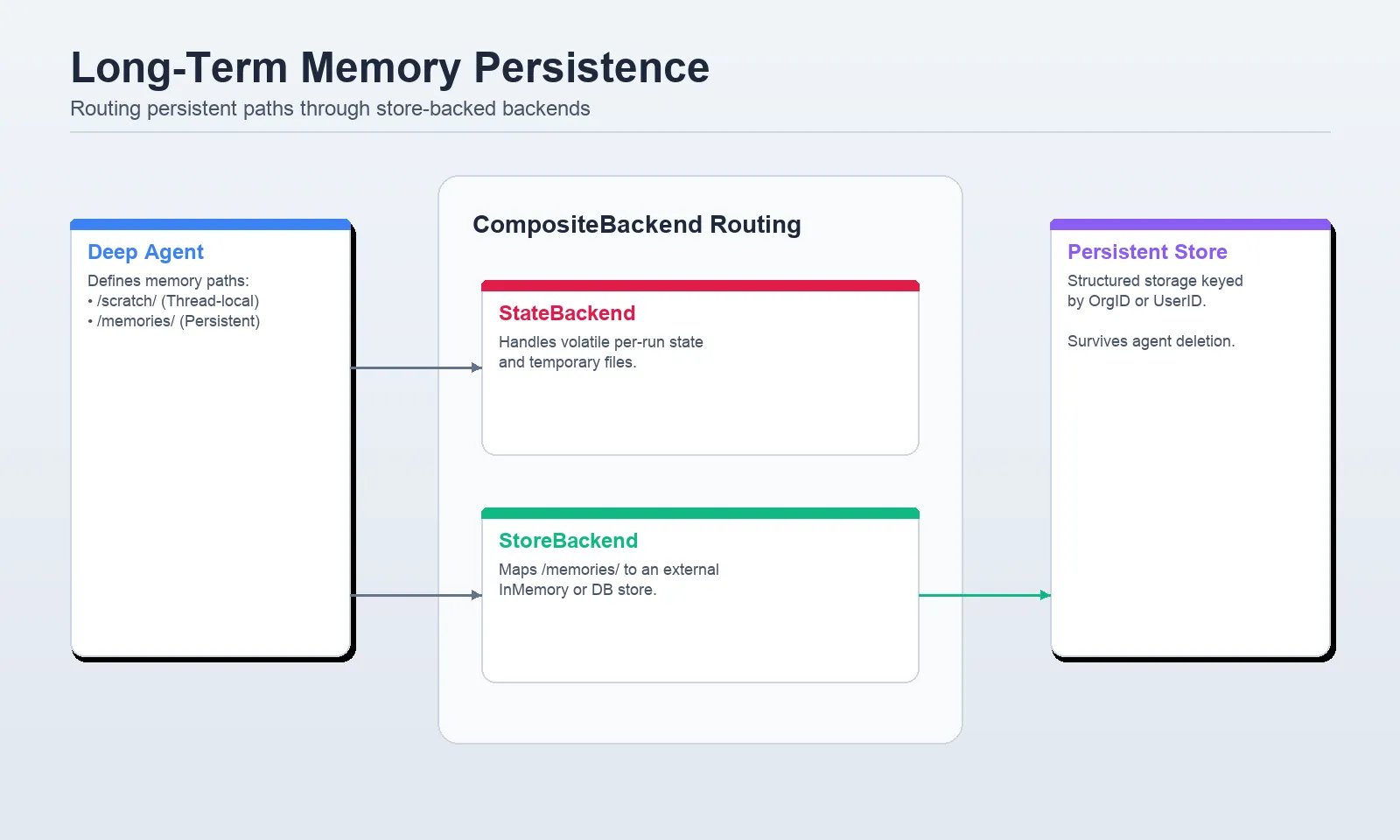
The final layer, long-term memory, is what allows Deep Agents to evolve from session-based tools into true digital assistants. This layer utilizes persistent storage—often backed by a StoreBackend or CompositeBackend—to maintain information across different conversations and users.
A critical challenge in long-term memory is "namespace isolation." In multi-user applications, it is vital that the memory of "User A" does not leak into the session of "User B." Deep Agents manage this by using the user_id from the runtime context to route memory requests to specific, isolated storage paths. This allows the agent to remember a user’s coding preferences or organizational policies without manual re-entry, creating a personalized experience that improves over time.
Chronology of Development in Agentic Frameworks
The transition to this five-layer model did not happen overnight. The following timeline illustrates the rapid evolution of the field:
- Late 2022: The rise of "Zero-Shot" prompting, where users provided a single instruction and expected a complete result.
- Early 2023: Introduction of Chain-of-Thought (CoT) and ReAct patterns, allowing agents to "think" before they act and use basic tools.
- Late 2023: The "Context Window Wars," where providers like Anthropic and OpenAI expanded windows to 100k+ tokens, leading to the discovery that "more context" often resulted in "less accuracy."
- 2024: Emergence of Deep Agent frameworks, shifting the focus from model size to context architecture and the five-layer hierarchy.
Expert Analysis: The Implications of Context Engineering
The shift toward structured context engineering signifies a maturing of the AI industry. We are moving away from the "black box" approach where developers simply hope the model understands the prompt. Instead, we are seeing the rise of "AI Orchestration," where the goal is to provide the agent with exactly what it needs, exactly when it needs it.
The implications for software development are profound. Future AI systems will likely spend more compute cycles on managing their own memory and context than on generating the final response. This "metacognition" allows for agents that are not only more reliable but also more auditable. When an agent makes a mistake, developers can now look at the specific layer—was it a failure in the system prompt (Layer 1)? Or did the summarization middleware (Layer 3) omit a key detail?
Common Pitfalls and Strategic Recommendations
Despite the robustness of the five-layer framework, several common mistakes continue to plague agent deployments:
- Over-prompting: Attempting to put everything into the system prompt, which dilutes the model’s focus.
- Context Leakage: Failing to isolate subagent outputs, leading to bloated parent histories.
- Ignoring Token Latency: Forgetting that larger contexts, even if within the model’s limit, significantly increase "Time to First Token" (TTFT).
To mitigate these, architects recommend a "minimalist" approach to context. If a fact is not required for the immediate next step, it should be moved to Layer 5 (Memory) or Layer 3 (Offloaded Storage).
Conclusion
Context engineering is no longer a luxury; it is the fundamental requirement for moving AI agents from experimental prototypes to production-ready tools. By leveraging the five layers of input, runtime, compression, isolation, and long-term memory, developers can build systems that are more than just the sum of their prompts. These agents are capable of handling high-stakes, multi-step tasks with the precision and reliability required by modern enterprises. As models continue to evolve, the frameworks that manage their "worldview" will remain the true differentiator in the quest for autonomous intelligence.