The global artificial intelligence landscape underwent a seismic shift this week with the release of DeepSeek-V4, a new generation of open-source models that challenges the long-standing hegemony of proprietary systems. For years, the industry had braced for the launch of closed-door iterations like GPT-5.5, assuming that the most advanced reasoning capabilities would remain locked behind expensive subscription paywalls and restrictive APIs. However, the arrival of DeepSeek-V4 has effectively tilted the balance of power toward the open-source community. By integrating a staggering 1.6 trillion parameter Mixture-of-Experts (MoE) architecture with a massive 1 million token context window, DeepSeek-V4 has transitioned from being a mere competitor to a market-defining force that commoditizes high-level reasoning.
DeepSeek, the Hangzhou-based research lab, has consistently punched above its weight, but V4 represents a different order of magnitude in technical ambition. The model family arrives at a critical juncture in 2026, a year defined by the "reasoning wars" where raw data processing has been superseded by the need for agentic autonomy and complex problem-solving. By offering these capabilities through an open-weight license, DeepSeek-V4 is forcing a radical reassessment of AI deployment costs, particularly for startups and enterprise-level developers who were previously tethered to the pricing whims of Silicon Valley’s largest tech conglomerates.
A Chronology of Innovation: The Path to V4
To understand the impact of DeepSeek-V4, one must look at the trajectory of the DeepSeek family over the last few years. The lab first gained international attention with DeepSeek-V2, which pioneered an efficient Mixture-of-Experts (MoE) architecture that allowed for high performance with significantly lower computational overhead. This was followed by DeepSeek-V3, which refined the training process using massive datasets and improved latent space representations.

In early 2025, the release of DeepSeek-R1 marked a turning point, as it introduced "reasoning-first" training methodologies that allowed the model to "think" through problems before responding, a technique similar to OpenAI’s o1 series. This set the stage for DeepSeek-V4, which synthesizes these reasoning capabilities with unprecedented scale. While previous versions were seen as "highly capable alternatives," V4 is being framed by industry analysts as a "frontier-leading" model that matches or exceeds the performance of the most advanced proprietary systems available in mid-2026.
Technical Breakthroughs: Beyond Brute Force
The performance of DeepSeek-V4 is not merely the result of scaling parameters; it is the product of three specific architectural innovations that address the "long-context problem" and inference efficiency.
First, the model introduces Manifold-Constrained Hyper-Connections (mHC). In traditional transformer architectures, residual connections can become unstable as the network depth and context window increase. mHC solves this by projecting weight matrices onto a constrained manifold, ensuring that the signal remains stable even when processing a full million tokens. This stability is what allows the model to maintain a 97% reliability rate in retrieving information from the middle of a massive document—a feat that often causes "hallucinations" in other large models.
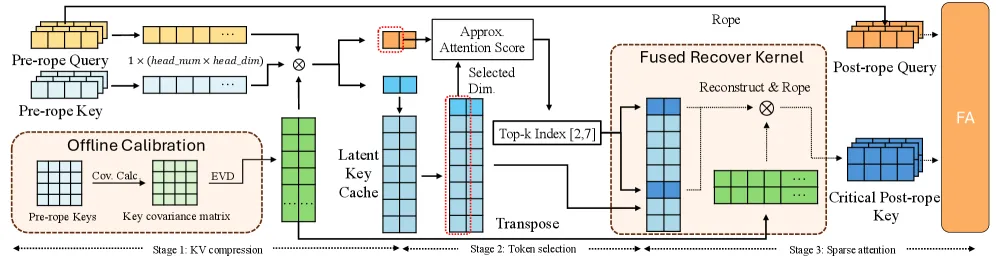
Second, the architecture utilizes SALS, or Sparse Attention with Latent Selection. This is a three-stage process designed to minimize the computational burden of the KV (Key-Value) Cache. In the first stage, the model performs multi-head KV cache compression; in the second, it selects relevant tokens within a latent space; and in the third, it applies sparse attention only to the most critical data points. This innovation reduces the KV cache size to just 12% of a standard transformer’s baseline, allowing for much faster inference and lower hardware requirements for local deployment.
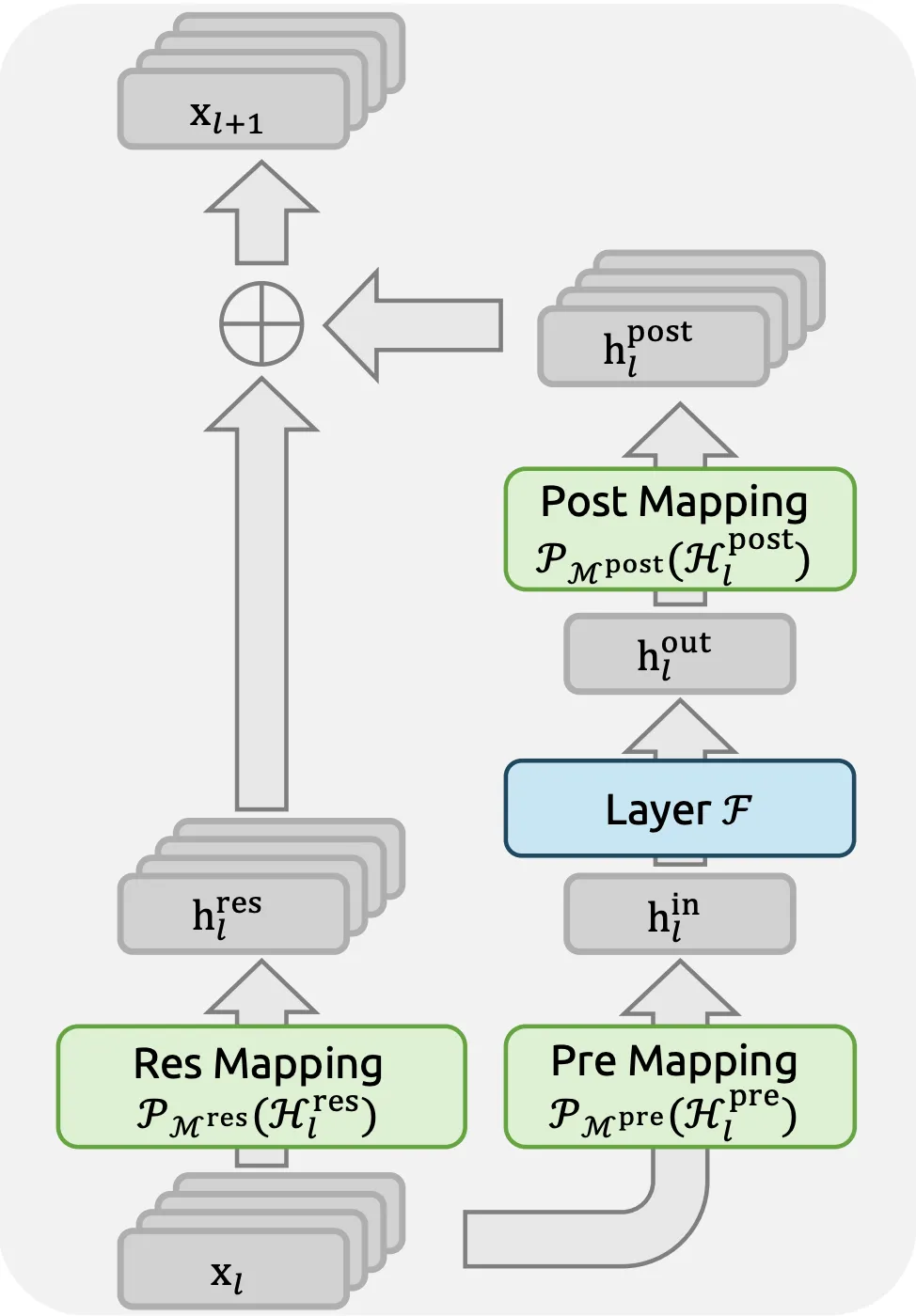
Finally, DeepSeek-V4 employs "Muon," a second-order optimization algorithm. While most models use first-order optimizers like AdamW, Muon allows for more precise updates to the model’s weights during training. When combined with a 4-step multi-token prediction mechanism—where the model predicts four tokens simultaneously rather than one at a time—the result is a "reasoning engine" that processes logic with the fluid speed of a standard text generator.
Economic Disruption: The Price War of 2026
The most immediate and visceral impact of DeepSeek-V4 is its pricing strategy. The model’s efficiency has allowed DeepSeek to initiate what economists are calling a "race to the bottom" for intelligence costs.
In a direct comparison with GPT-5.5, the price disparity is stark. DeepSeek-V4 Flash is priced at approximately $0.14 per 1 million input tokens and $0.28 per 1 million output tokens. In contrast, the base version of GPT-5.5 commands $5.00 for input and $30.00 for output per million tokens. This makes DeepSeek’s offering roughly 36 times cheaper for standard queries.
The disruption goes deeper with "Cache Hit" pricing. For agentic workflows where the same context—such as a massive codebase or a legal library—is prompted repeatedly, DeepSeek-V4 offers a rate of $0.028 per million tokens. This effectively enables "perpetual AI agents" that can monitor and interact within a system for cents per day. For developers, this removes the "intelligence tax" that has historically limited the scope of AI integration.
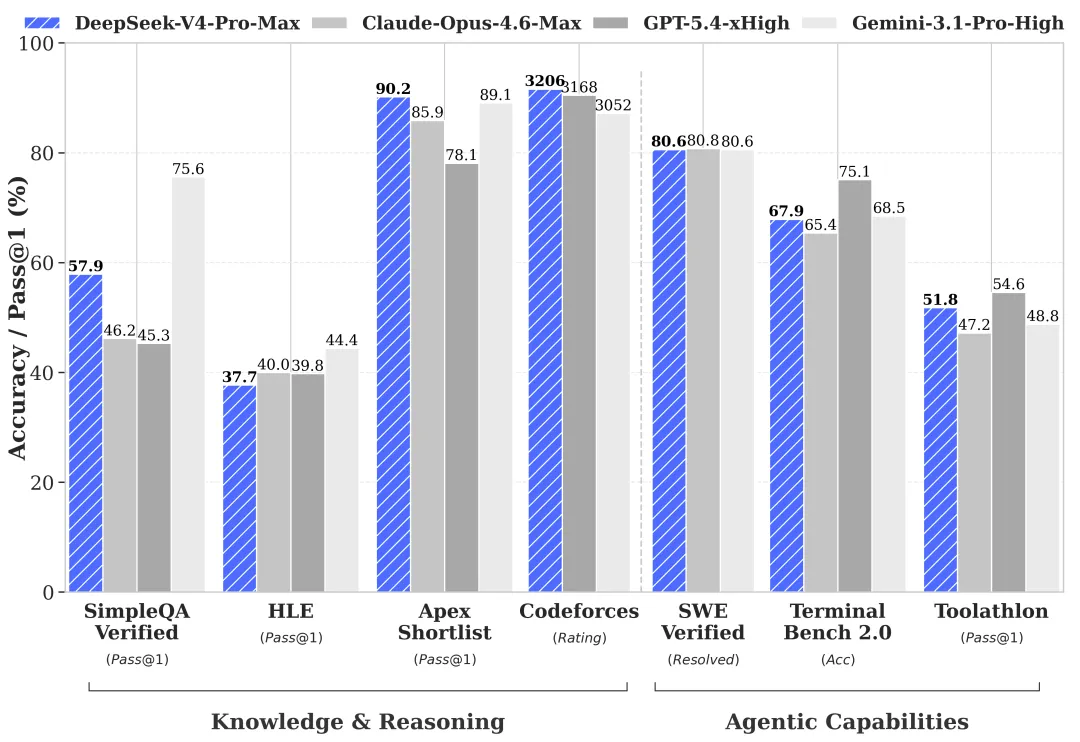
Benchmarks and Performance: Closing the Gap
DeepSeek-V4 has officially closed the gap in applied engineering and agentic autonomy, areas where OpenAI and Anthropic have traditionally held a lead. On the SWE-bench Verified test, which measures an AI’s ability to resolve real-world GitHub issues, DeepSeek-V4 Pro achieved a score of 80.6%, nearly identical to GPT-5.5’s 80.8%. However, in context reliability—the ability to utilize the full 1 million token window without losing track of instructions—DeepSeek-V4 Pro scored 97.0%, significantly outperforming GPT-5.5’s 82.5%.
In the realms of mathematics and PhD-level science, the "DeepSeek-Reasoner V4" mode has shown it can trade blows with the "O-series" models from OpenAI. On competitive math benchmarks like AIME and scientific reasoning tests like GPQA, the model’s ability to engage in extended internal "Chain of Thought" processing has made it a top-tier choice for academic and industrial research.
Industry Reactions and Market Sentiment
The release has sparked a flurry of reactions from the global tech community. Developers on platforms like X (formerly Twitter) and Reddit have expressed a mix of shock and enthusiasm, particularly coming so soon after the release of GPT-5.5. The consensus among the developer community is that the "barrier to entry" for building sophisticated, long-context AI applications has been permanently lowered.
"The economics of DeepSeek-V4 change the fundamental math of my startup," noted one Silicon Valley engineer. "Last month, I was budgeting five figures for API costs to analyze our repository. With V4-Flash and cache hits, that cost has effectively vanished."
Market analysts suggest that this release puts immense pressure on closed-source providers to justify their premium pricing. If an open-source model can match the reasoning capabilities of a proprietary one at a fraction of the cost, the "moat" around closed systems begins to look more like a puddle. There is also a geopolitical dimension to the reaction; DeepSeek’s success highlights the growing capability of Chinese AI labs to innovate at the architectural level, rather than just catching up to Western benchmarks.
Broader Implications: The Era of Persistent Collaboration
The launch of DeepSeek-V4 represents a fundamental transition in how we perceive artificial intelligence. It is no longer just a query-response tool; it is becoming a persistent collaborator. The combination of open-source accessibility, unprecedented context depth, and "Flash" pricing makes it perhaps the most significant release of 2026.
For the enterprise, the implications are profound. Companies can now host these models on their own infrastructure, ensuring data privacy while benefiting from frontier-level intelligence. The ability to process a million tokens means that an entire corporate knowledge base can be "read" by the model in a single session, allowing for holistic analysis that was previously impossible.
For the individual developer, the message is even clearer: the bottleneck is no longer the cost of intelligence, but the imagination of the person prompting it. As DeepSeek-V4 begins to be integrated into IDEs, legal platforms, and scientific research tools, the industry is entering a new phase where high-reasoning AI is a utility, as ubiquitous and affordable as electricity or cloud storage.
Conclusion and Future Outlook
As we move further into 2026, the success of DeepSeek-V4 will likely trigger a wave of new open-source projects built upon its architecture. While the model does not currently support native multimodal inputs (images and video), the developers have confirmed that these features are in the final stages of testing and will be rolled out in the coming months.
The "DeepSeek License" allows for broad commercial use, which will likely lead to a surge in specialized "fine-tuned" versions of V4 tailored for specific industries like medicine, law, and high-frequency trading. By democratizing access to trillion-parameter reasoning, DeepSeek-V4 has not just released a model; it has sparked a new era of AI transparency and economic accessibility. The frontier is now open, and the race to define the future of autonomous intelligence has truly begun.