Digital marketing has long positioned A/B testing as the ultimate frontier for applying scientific rigor to business growth. By utilizing randomized controlled trials—the same gold standard used in physics, genetics, and clinical pharmacology—marketers aim to isolate variables and establish clear causal links between website changes and user behavior. However, a growing body of evidence suggests that the common practices and statistical foundations of modern A/B testing are lagging significantly behind contemporary scientific standards. Industry experts warn that many practitioners are relying on methodologies that are nearly half a century out of date, leading to a proliferation of "false positives" and inefficient resource allocation.
The central conflict arises from the misapplication of classical frequentist statistics to the fast-paced, real-time environment of digital commerce. While traditional statistical tests were designed for scenarios where data is collected in a single batch and analyzed once, digital marketing environments encourage constant monitoring. This friction has led to three systemic issues: the misuse of statistical significance, a disregard for statistical power, and a general lack of efficiency in experimental design. To address these vulnerabilities, a new framework known as the AGILE statistical approach is emerging, borrowing heavily from the rigorous sequential designs used in life-saving medical trials.
The Integrity Gap: The "Peeking" Problem in Significance Testing
The most pervasive issue in current A/B testing is the violation of the "fixed-horizon" requirement of classical significance tests, such as the Student’s T-test. In a strictly scientific setting, a researcher must determine the sample size in advance and only analyze the data once that threshold is reached. In the corporate world, however, the pressure to deliver results leads to "data peeking"—the practice of checking results daily or weekly and making decisions based on fluctuating confidence levels.
When a practitioner observes a "95% confidence" result after only three days of a planned fourteen-day test and decides to stop early to declare a winner, they are inadvertently inflating the Type I error rate (false positives). Statistical models show that conversion rates naturally fluctuate; a result that looks significant early on may simply be a "hiccup" in the data. If a test is peeked at five times throughout its duration, the actual error rate is not the nominal 5%, but closer to 16%. By peeking ten times, the probability of declaring a false winner increases fivefold. This phenomenon, identified by statisticians as early as 1969, remains a primary cause of "illusory gains" where a tested variant appears to be a winner in the lab but fails to produce a revenue lift once fully implemented.
The Sensitivity Crisis: The Overlooked Role of Statistical Power
While most marketers are familiar with the concept of "significance," far fewer account for "statistical power," or the test’s sensitivity. Statistical power is the probability that a test will correctly detect a true effect of a certain size. A test with low power is essentially a "blind" experiment; it may fail to identify a genuine improvement simply because the sample size was too small or the variance was too high.
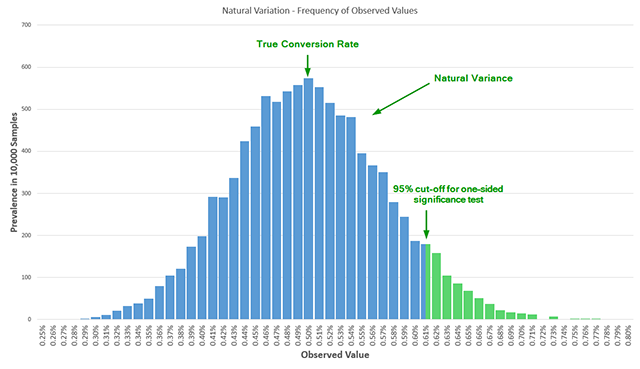
The lack of consideration for power creates a "false negative" trap. Organizations may abandon a potentially lucrative design change because a test failed to reach significance, unaware that the test was mathematically incapable of detecting the improvement in the first place. Historical reviews of influential literature on Conversion Rate Optimization (CRO) found that between 2008 and 2014, only one out of seven major textbooks discussed statistical power in a proper context. This systemic neglect means many companies are wasting weeks of development time on tests that are essentially coin tosses.
A Chronology of Experimental Evolution
The transition from traditional methods to the proposed AGILE framework represents a necessary evolution in the history of experimentation:
- 1920s–1930s: Ronald Fisher develops the foundations of frequentist statistics and experimental design, primarily for agricultural research where data is harvested in seasonal batches.
- 1950s: The rise of clinical trials necessitates more ethical testing methods, leading to the development of "sequential analysis" to allow trials to stop early if a drug is found to be either highly effective or dangerous.
- 1969: Peter Armitage and colleagues publish seminal work warning about the "multiplicity" problem in repeated significance testing, proving that frequent peeking destroys the validity of P-values.
- 2000s: The digital boom makes A/B testing accessible to non-statisticians through automated tools, but these tools often prioritize user-friendly dashboards over statistical validity.
- 2017–Present: The introduction of the AGILE statistical method and Bayesian alternatives seeks to reconcile the need for real-time decision-making with the requirement for mathematical integrity.
The AGILE Framework: Efficiency Through Sequential Design
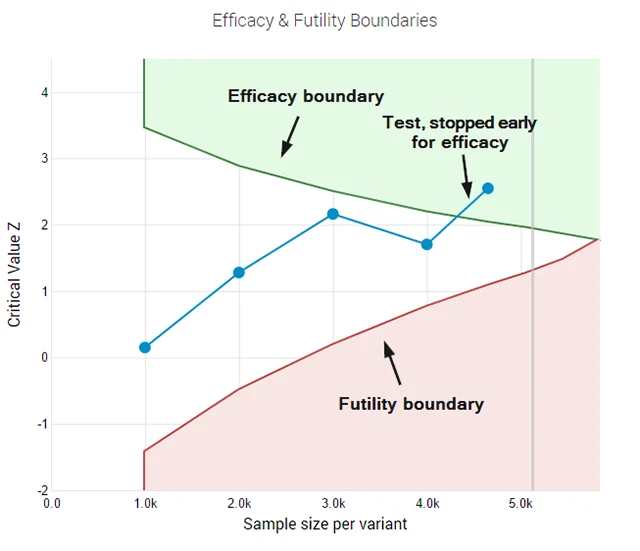
The AGILE statistical approach provides a solution to the "peeking" dilemma by utilizing error-spending functions. This method, rooted in Group Sequential Design used in medical research, allows for interim analyses while maintaining strict control over the overall error rate. Instead of requiring a single look at the end of a test, AGILE sets "boundaries" for significance that adjust based on how much data has been collected.
One of the most significant advantages of the AGILE method is the introduction of "futility stopping rules." In a classical test, a practitioner is technically required to run the test to completion even if the variant is performing abysmally. Under the AGILE framework, if a variant shows a high probability of failure early on, the test can be terminated for futility. This "fail fast" mentality prevents the "bleeding" of conversion rates and allows teams to redirect resources to more promising hypotheses.
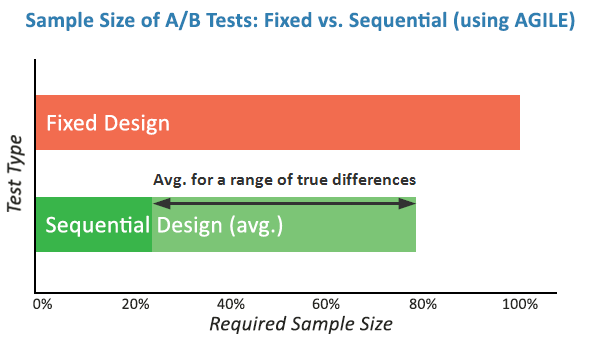
Simulations conducted during the validation of the AGILE method indicate that it can offer efficiency gains of 20% to 80%. This means that in many cases, a winner or loser can be identified in half the time it would take using a fixed-sample classical test, without sacrificing the reliability of the result.
Economic Implications and Industry Responses
The shift toward more robust statistical methods is not merely a theoretical exercise; it has profound economic implications. For a high-traffic e-commerce platform, a false positive—implementing a change that doesn’t actually work—can result in millions of dollars in lost opportunity costs and wasted engineering hours. Conversely, the ability to stop a failing test early can save significant revenue that would otherwise be lost during the remainder of the experimental period.
Data scientists at major tech firms like Google, Netflix, and Amazon have already moved toward similar "always-valid" p-values or Bayesian frameworks to handle the scale and speed of their experimentation. However, the broader digital marketing industry has been slower to adapt.
"The industry is reaching a tipping point," suggests one senior data analyst in the CRO space. "We are moving away from the ‘wild west’ of A/B testing where any green arrow was a victory. Stakeholders are starting to ask why the 20% lift reported in the testing tool never shows up in the quarterly earnings. The answer is usually bad statistics."
Strategic Recommendations for Modern Practitioners
To align A/B testing practices with modern scientific standards, organizations are encouraged to move beyond the "calculator-and-dashboard" approach. The following steps are recommended for a more rigorous experimental culture:
- Mandate Power Calculations: Before any test begins, teams must define the Minimum Effect Size of Interest (MESI) and ensure the sample size is sufficient to detect it.
- Adopt Sequential Monitoring: If the business requires interim results, move away from classical T-tests and adopt an AGILE or Bayesian framework that accounts for multiple looks at the data.
- Implement Futility Rules: Establish clear criteria for when a test should be abandoned to prevent resource drain.
- Prioritize Education: Ensure that marketing managers and stakeholders understand that "95% confidence" is not a static number, but a probability that is highly sensitive to the experimental design.
As digital landscapes become increasingly competitive, the margin for error in optimization continues to shrink. The adoption of the AGILE statistical method represents a maturation of the field, moving digital marketing closer to the precision of the laboratory sciences it has long sought to emulate. By embracing these more sophisticated models, businesses can finally ensure that their "data-driven" decisions are supported by data that is not only abundant but statistically sound.