The landscape of artificial intelligence and computer vision has reached a new milestone with the official release of YOLO26 by Ultralytics, a model that marks a significant leap in the "You Only Look Once" lineage. This latest iteration is designed to serve as a comprehensive, multi-task framework capable of performing object detection, instance segmentation, pose estimation, and image classification simultaneously in real-time environments. As industries increasingly demand high-speed processing without sacrificing accuracy, YOLO26 arrives as a pivotal solution for developers and enterprises looking to integrate advanced visual intelligence into security systems, autonomous vehicles, and industrial automation.

The release of YOLO26 follows a period of intense development aimed at refining the balance between computational efficiency and predictive precision. Historically, computer vision tasks were often siloed, requiring separate models for detecting an object and identifying its specific keypoints or segmenting its exact boundaries. YOLO26 collapses these requirements into a single, unified architecture. This integration allows the model to process visual data with a level of fluidity that was previously unattainable on consumer-grade hardware, making it accessible to a broader range of applications from mobile devices to edge computing units.
The Technical Paradigm: Multi-Task Learning and Efficiency
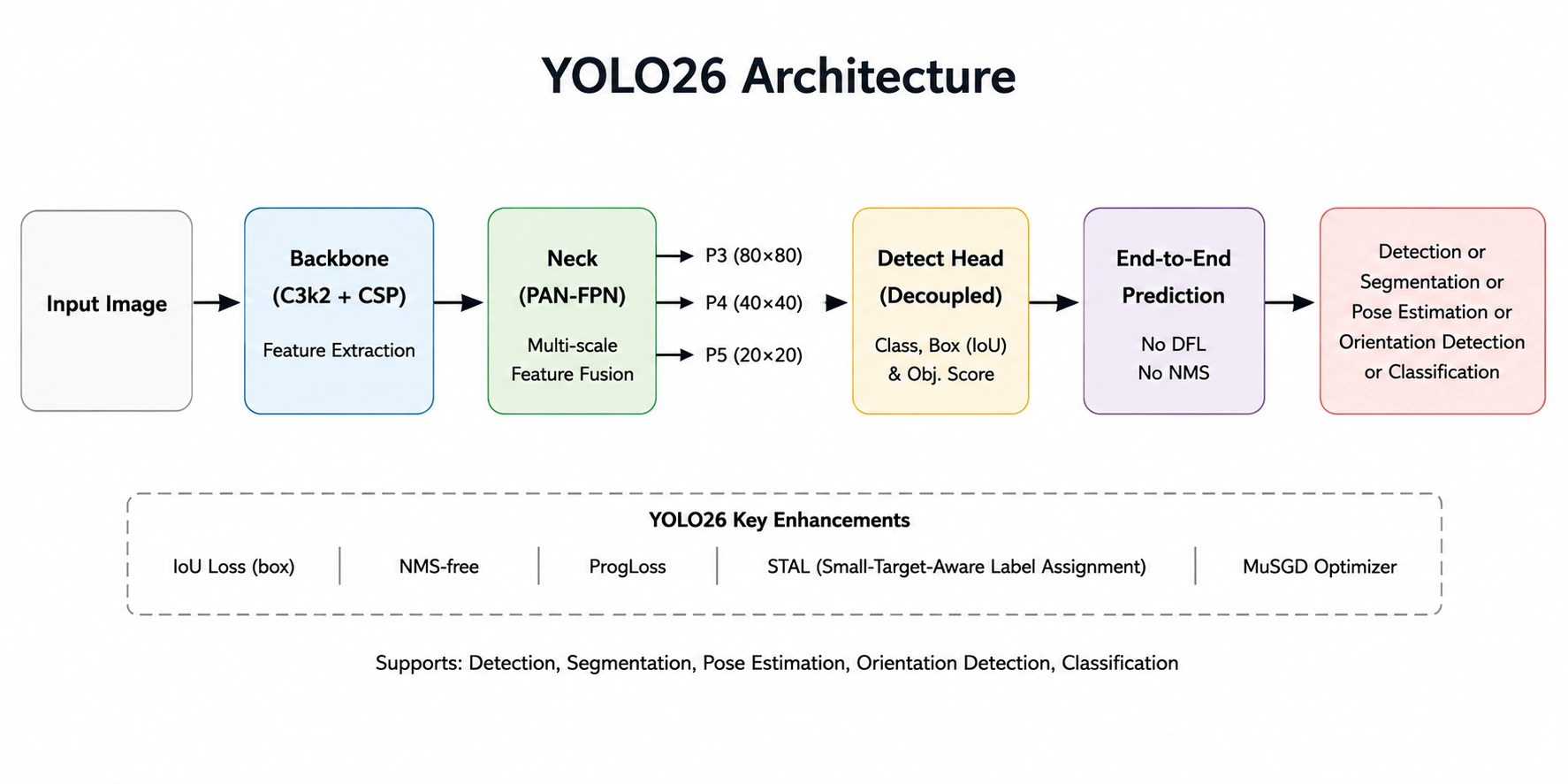
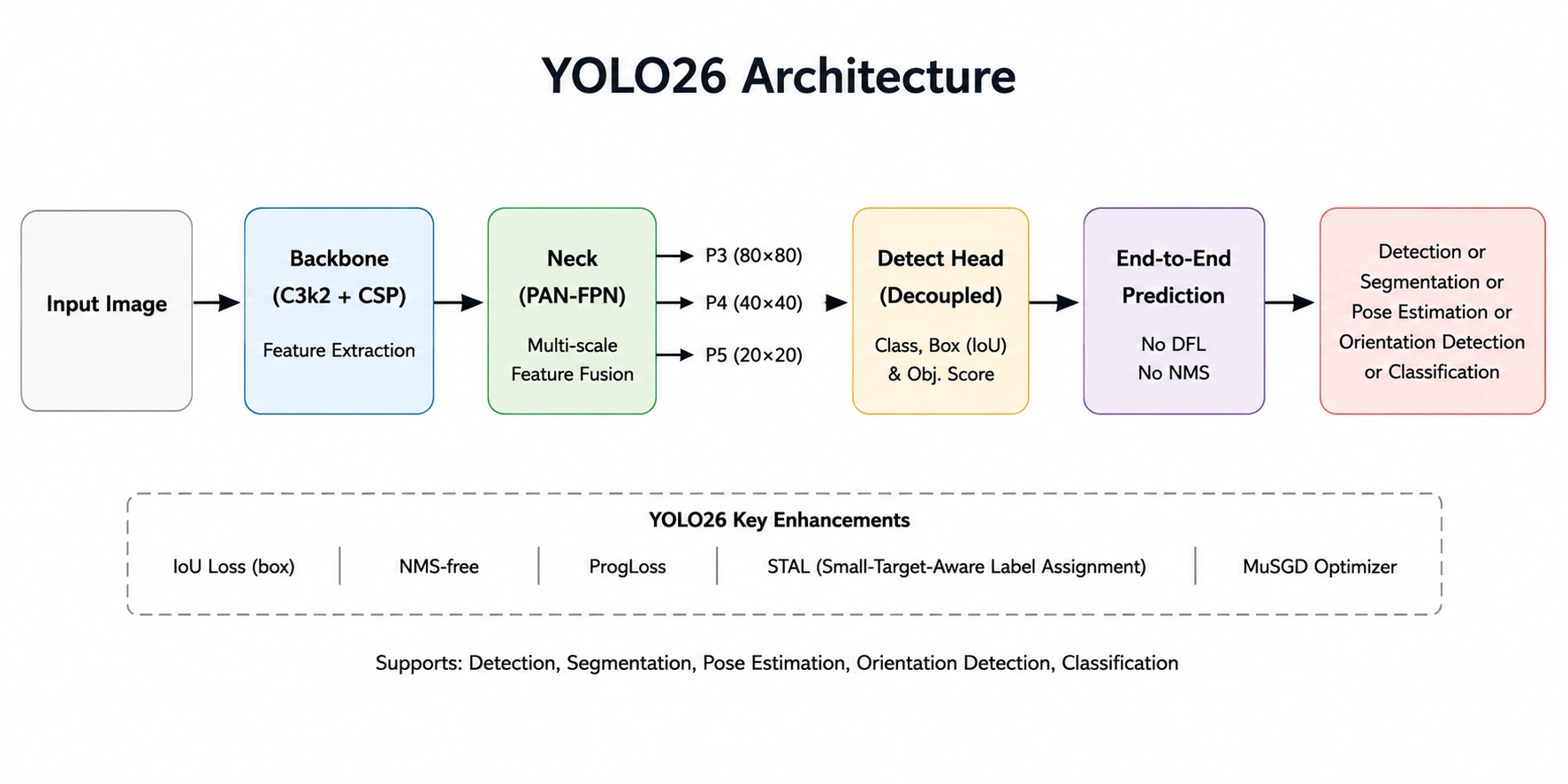
At its core, YOLO26 is built upon the foundational logic of localization and classification, but it introduces architectural enhancements that optimize the way features are extracted and processed. In traditional object detection, the model identifies the coordinates of an object (localization) and assigns a probability to its category (classification). YOLO26 extends this by incorporating high-fidelity masks for instance segmentation and skeletal keypoints for pose estimation within the same inference pass.
The architecture of YOLO26 is engineered to handle varying scales of input, allowing it to be fine-tuned for the detection of extremely small objects—a common challenge in satellite imagery and medical diagnostics. By utilizing a more sophisticated backbone and neck structure, the model minimizes information loss as data passes through its neural layers. This results in a higher Mean Average Precision (mAP) compared to its predecessors, while maintaining the signature low-latency performance that has made the YOLO family a standard in the industry.
One of the standout features of the YOLO26 release is the variety of model scales available. These range from "Nano" (yolo26n.pt), optimized for ultra-fast performance on mobile and CPU-based systems, to larger variants designed for high-end GPUs where maximum accuracy is the priority. This scalability ensures that developers can deploy the model in diverse environments, from low-power IoT sensors to robust cloud-based surveillance networks.
A Chronology of Innovation: From YOLOv1 to YOLO26
To understand the impact of YOLO26, it is essential to trace the trajectory of the YOLO framework. The original YOLO model, introduced by Joseph Redmon in 2015, revolutionized the field by treating object detection as a single regression problem, moving away from the slower "region proposal" methods used by R-CNN. Over the years, the project saw various iterations, with versions like YOLOv3 and YOLOv4 introducing significant improvements in feature extraction and data augmentation.
The transition of the YOLO project to Ultralytics marked a new era of accessibility and performance, particularly with the release of YOLOv5 and later YOLOv8. These versions focused on a user-friendly Pythonic interface and seamless integration with modern deep learning libraries like PyTorch. YOLO26 represents the culmination of a decade of research, incorporating the latest advancements in transformer-based backbones and attention mechanisms while staying true to the real-time constraints that define the "You Only Look Once" philosophy.

Implementation and Practical Application
The accessibility of YOLO26 is one of its most significant advantages. Unlike many high-performance models that require complex setups, YOLO26 can be implemented with minimal code, as demonstrated in recent developer previews using environments like Google Colab. The process begins with a simple installation of the ultralytics package, which provides all the necessary dependencies.
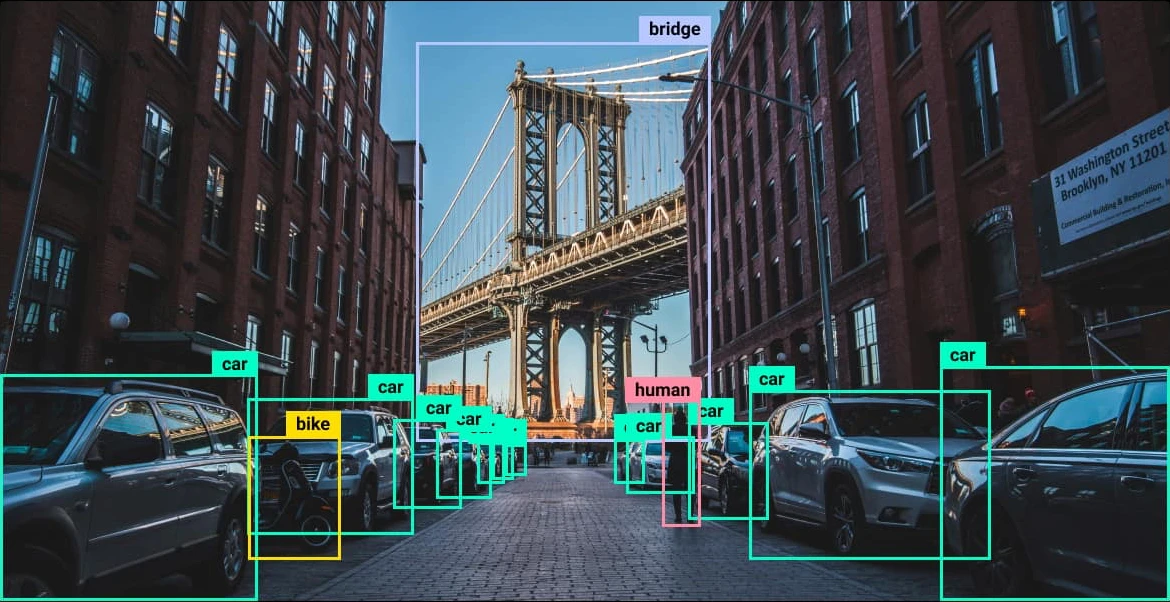
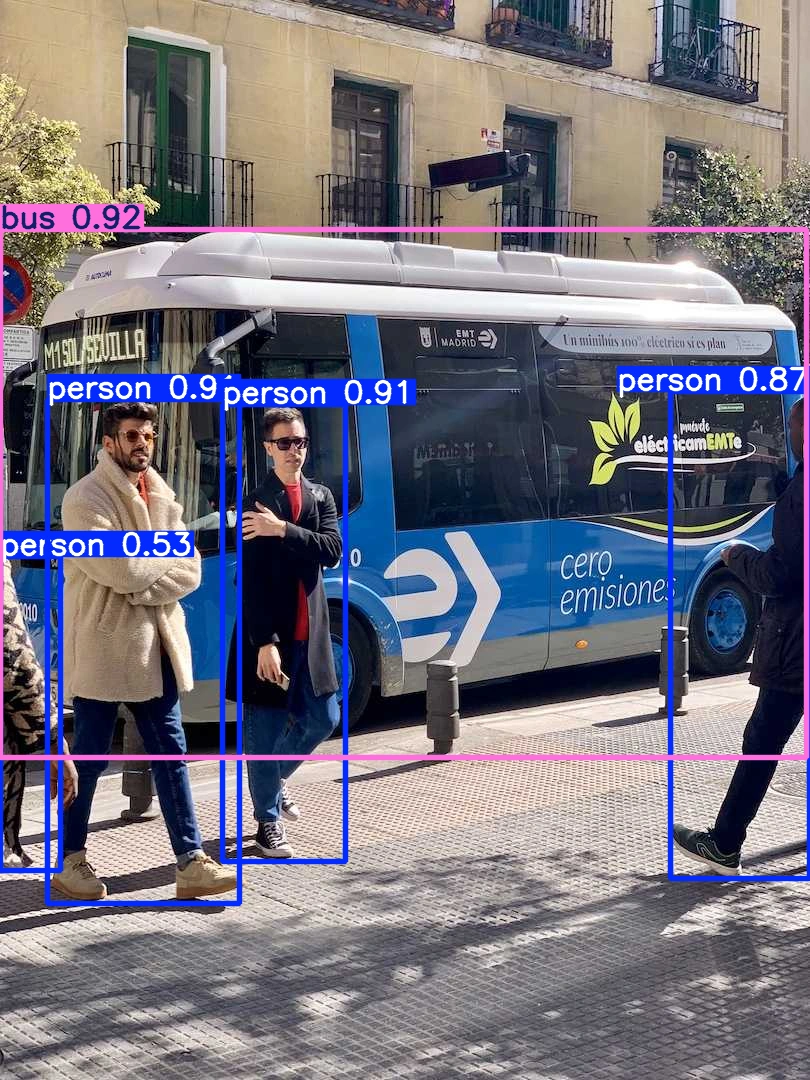
For instance, performing object detection on standard imagery—such as the classic "bus" benchmark—requires only a few lines of code. The model loads a pre-trained weight file, such as yolo26n.pt, and processes the image to identify entities like passengers and vehicles with high confidence scores. Beyond simple detection, the instance segmentation capabilities allow the model to generate pixel-perfect masks, which is crucial for applications like autonomous driving where understanding the exact shape of an obstacle is as important as knowing its location.

Pose estimation is another area where YOLO26 excels. By identifying human body keypoints, the model can track movement patterns in real-time. This has immediate implications for the healthcare and fitness industries, where it can be used for physical therapy monitoring or athletic form analysis. In security contexts, pose estimation can help detect suspicious behavior or falls in elderly care facilities, providing a layer of automated oversight that is both efficient and scalable.
Specialized Capabilities: Oriented Bounding Boxes (OBB)
A unique addition to the YOLO26 suite is the specialized support for Oriented Bounding Boxes (OBB). Traditional object detection uses axis-aligned rectangles, which often fail to accurately represent objects that are tilted or rotated, such as ships in a harbor or buildings in aerial photography. The yolo26n-obb.pt model is specifically trained to handle these rotations, providing a much tighter fit for objects viewed from top-down or satellite perspectives.
This capability is expected to see rapid adoption in the geospatial and maritime sectors. By providing more accurate spatial data for rotated objects, YOLO26 enables better density estimation and tracking in crowded environments. This is particularly relevant for environmental monitoring, where researchers track wildlife or changes in land use through drone-captured imagery.
Industry Reactions and Market Implications
The announcement of YOLO26 has prompted a wave of positive reactions from the tech community and industrial sectors. Data scientists have noted that the ability to run multiple tasks—detection, segmentation, and pose—on a single model significantly reduces the "technical debt" associated with maintaining multiple neural networks. By streamlining the pipeline, companies can reduce their cloud computing costs and improve the response times of their AI-driven products.

Hardware manufacturers are also expected to respond to the YOLO26 launch. Companies like NVIDIA and Intel have historically optimized their inference engines (such as TensorRT and OpenVINO) for YOLO architectures. The efficiency of YOLO26 is likely to drive further innovation in edge-AI hardware, as manufacturers seek to provide chips that can handle the model’s multi-task requirements at even higher frame rates.
From a market perspective, the release of YOLO26 positions Ultralytics as a dominant force in the "AI for Vision" space. As more businesses move away from experimental AI and toward production-ready deployments, models that offer a "plug-and-play" experience with high reliability become the preferred choice. YOLO26 addresses this market need by offering a robust, well-documented, and highly performant toolset.

Broader Impact and Future Outlook
The implications of YOLO26 extend beyond technical efficiency; they touch upon the democratization of high-end artificial intelligence. Because the model can run on standard CPUs and doesn’t strictly require expensive GPU clusters for inference, it opens the door for startups and researchers in developing regions to build world-class computer vision applications. This accessibility is a core tenet of the open-source philosophy that has surrounded the YOLO project since its inception.
Looking forward, the success of YOLO26 is expected to influence the development of future models that may incorporate even more modalities, such as depth estimation or visual-linguistic integration. As we move closer to a world of ubiquitous sensing, the ability of a single model to "see" and understand the world in real-time—recognizing what things are, where they are, how they are moving, and what they are doing—will be the foundation of the next generation of smart cities and autonomous systems.

In summary, YOLO26 is not merely an incremental update; it is a comprehensive vision platform. By mastering object detection, instance segmentation, pose estimation, and classification within a single, real-time framework, it provides the tools necessary for the next wave of technological innovation. Whether it is improving the safety of our streets through better traffic monitoring or enabling the next generation of robotic assistants, YOLO26 stands as a testament to the rapid progress and bright future of computer vision.