The rapid integration of generative artificial intelligence into daily workflows has created a significant paradox for the modern digital consumer. While tools such as OpenAI’s ChatGPT, Anthropic’s Claude, and Google’s Gemini offer unprecedented productivity gains, they simultaneously introduce profound risks to data privacy and intellectual property. As these large language models (LLMs) become ubiquitous, the distinction between a private digital assistant and a public data harvester has blurred, prompting a surge in warnings from cybersecurity experts and regulatory bodies worldwide. The fundamental reality of the current AI landscape is that unless specific precautions are taken, the user is often the product, with their queries serving as raw material for the next generation of algorithmic training.
The Architecture of Exposure: How Chatbots Process Information
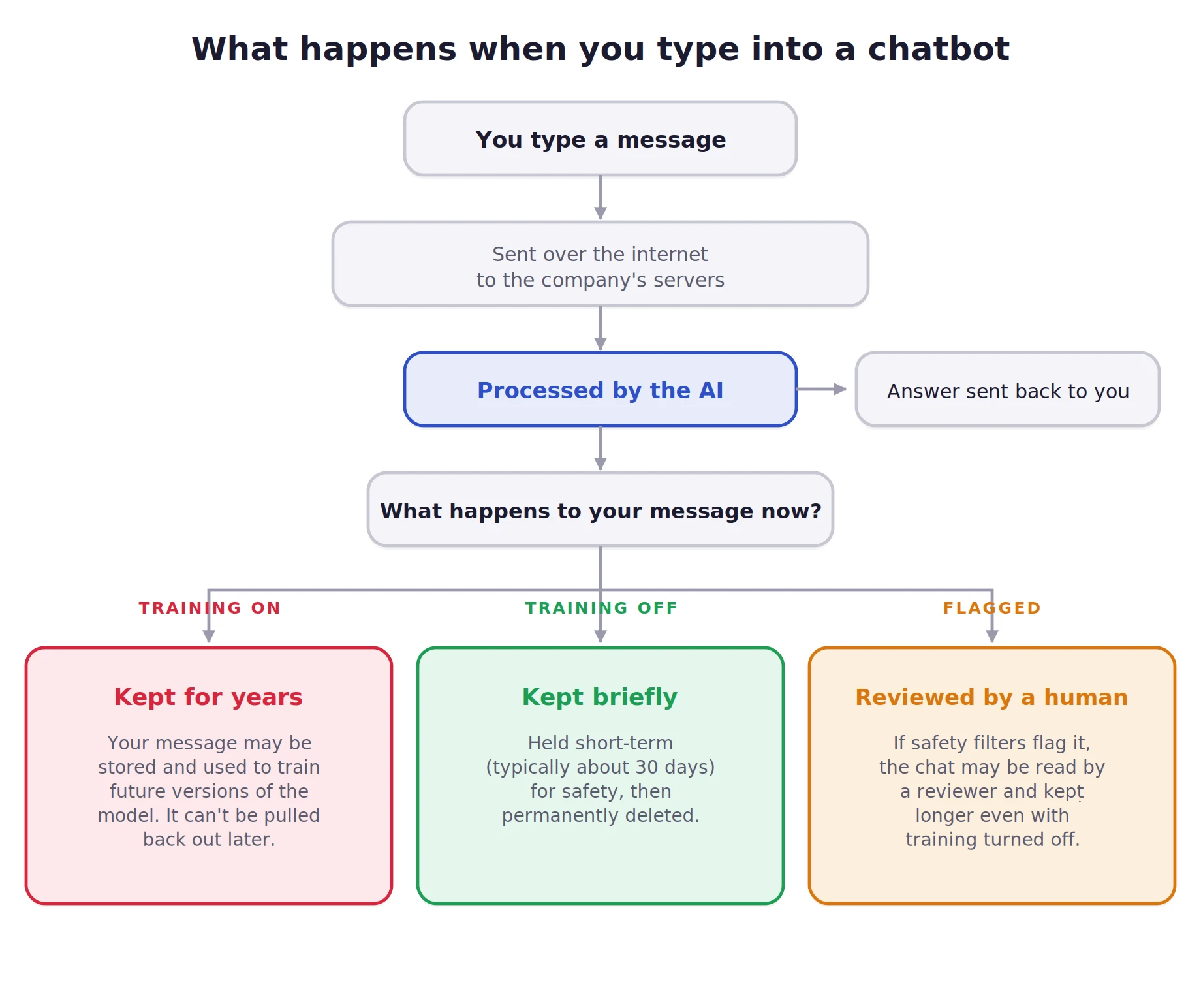
To understand the risks associated with AI usage, one must first dismantle the common misconception that a chatbot functions like a local word processor or a private notepad. When a user enters a prompt, the data does not remain on the local device; it is transmitted to a company’s centralized servers. This process involves several stages, including tokenization, safety filtering, and inference, where the model generates a response.

However, the lifecycle of a message does not necessarily end once the response is delivered. Most consumer-grade AI platforms are configured by default to retain these interactions. This data serves two primary purposes for the provider: service improvement and model training. In the latter case, human reviewers may eventually read anonymized or even identified snippets of conversations to refine the model’s Reinforcement Learning from Human Feedback (RLHF) systems. Consequently, any secret, proprietary code, or personal identifier shared with the AI enters a repository that is theoretically accessible to the service provider’s employees and potentially retrievable—in some form—by other users if the model "leaks" training data.
A Chronology of AI Privacy Concerns
The tension between AI utility and data security is not theoretical; it is rooted in a series of high-profile incidents that have shaped current corporate and regulatory policies.
In early 2023, just months after the public release of ChatGPT, a major security breach at Samsung highlighted the dangers of "Shadow AI." Several engineers at the electronics giant reportedly uploaded sensitive semiconductor source code and internal meeting notes to ChatGPT to assist with debugging and summarization. Because these interactions were stored on OpenAI’s servers, the proprietary information was effectively moved outside of Samsung’s controlled environment. This incident led to a temporary ban on generative AI tools within the company and served as a catalyst for other corporations, including JPMorgan Chase, Apple, and Verizon, to restrict or prohibit the use of consumer AI apps.
By mid-2023, the Federal Trade Commission (FTC) in the United States opened an investigation into OpenAI, focusing on whether the company’s data collection practices resulted in reputational harm or privacy violations. Simultaneously, the European Union began drafting the AI Act, the world’s first comprehensive framework for AI regulation, which emphasizes transparency and the right of users to control how their data is utilized.
In 2024 and 2025, the industry shifted toward "Privacy by Design" in response to these pressures. Major providers introduced "Temporary Modes" and "Enterprise Tiers" specifically designed to sequester user data. Despite these advancements, the burden of security remains largely on the end-user to navigate complex settings and opt-out mechanisms.
The Three Layers of Digital Defense
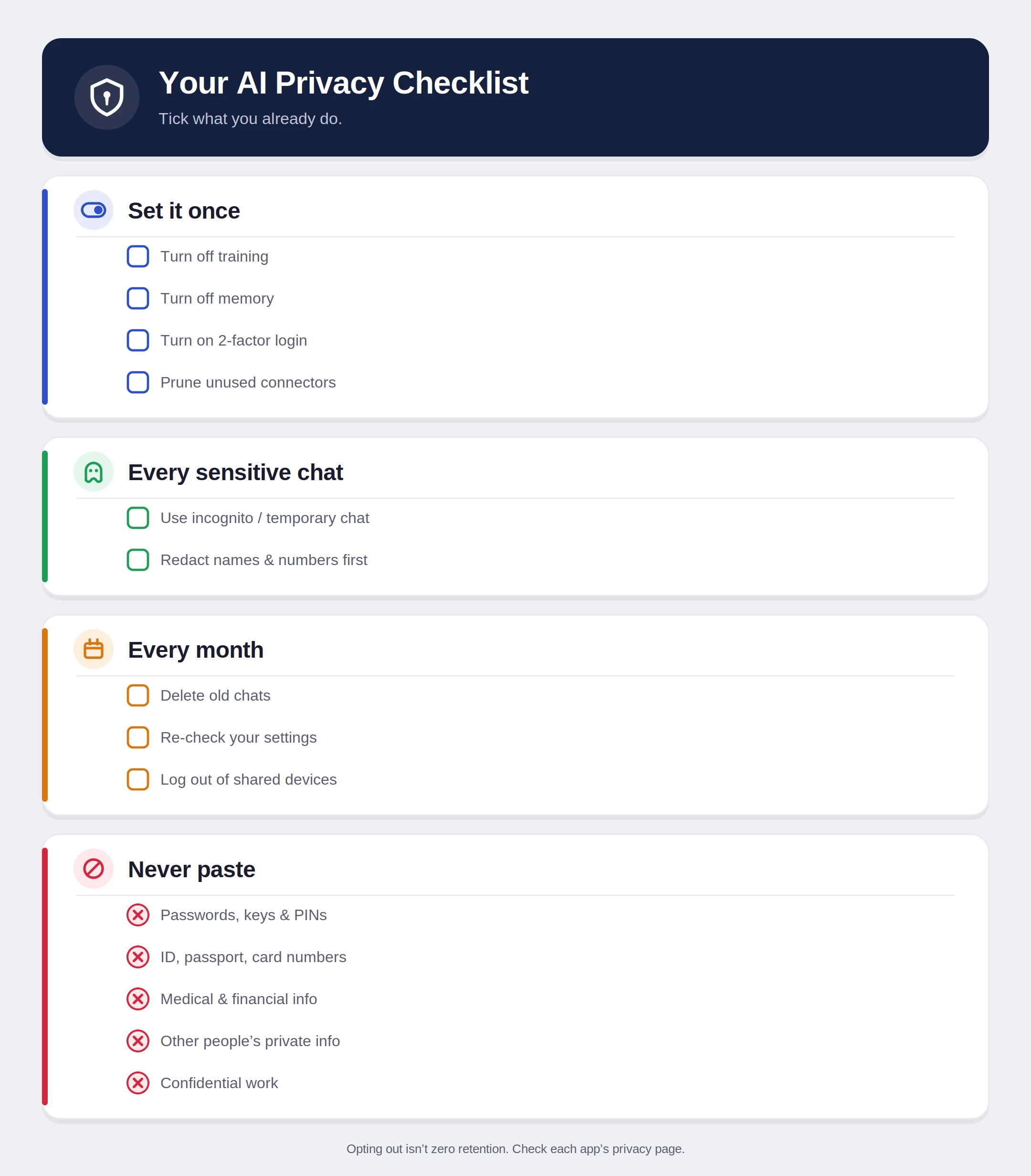
Achieving a balance between AI utility and privacy requires a layered defense strategy. Cybersecurity professionals recommend a three-tiered approach to minimize exposure while maintaining access to AI capabilities.
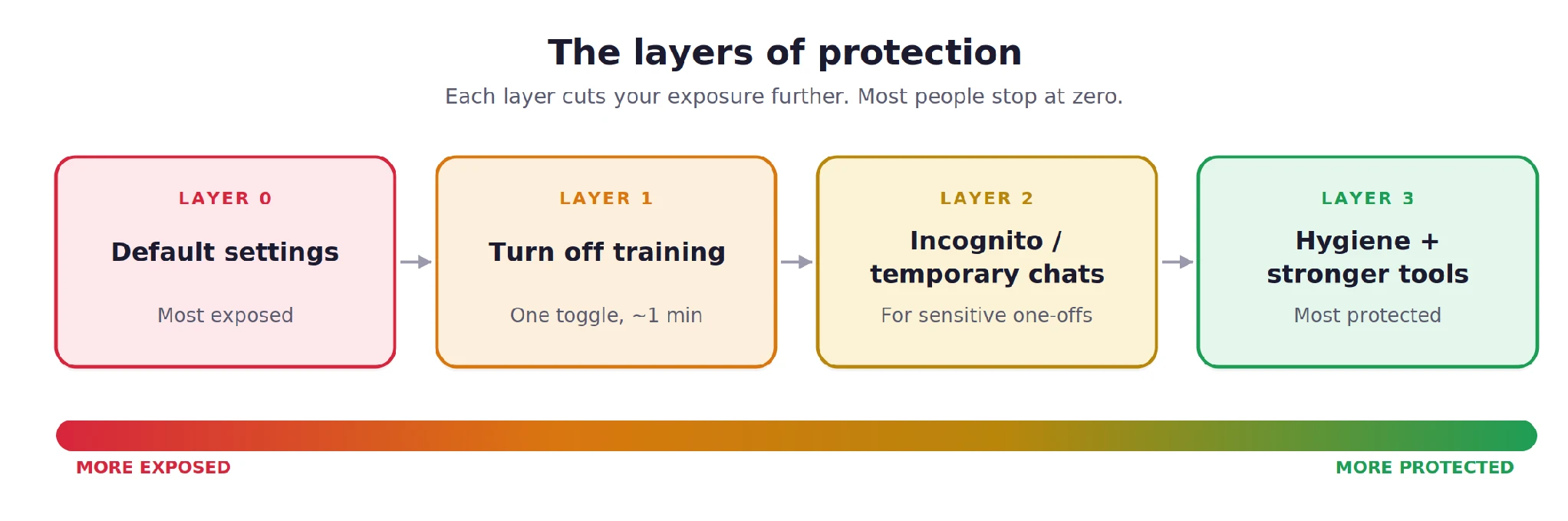
Layer 1: Disabling Model Training
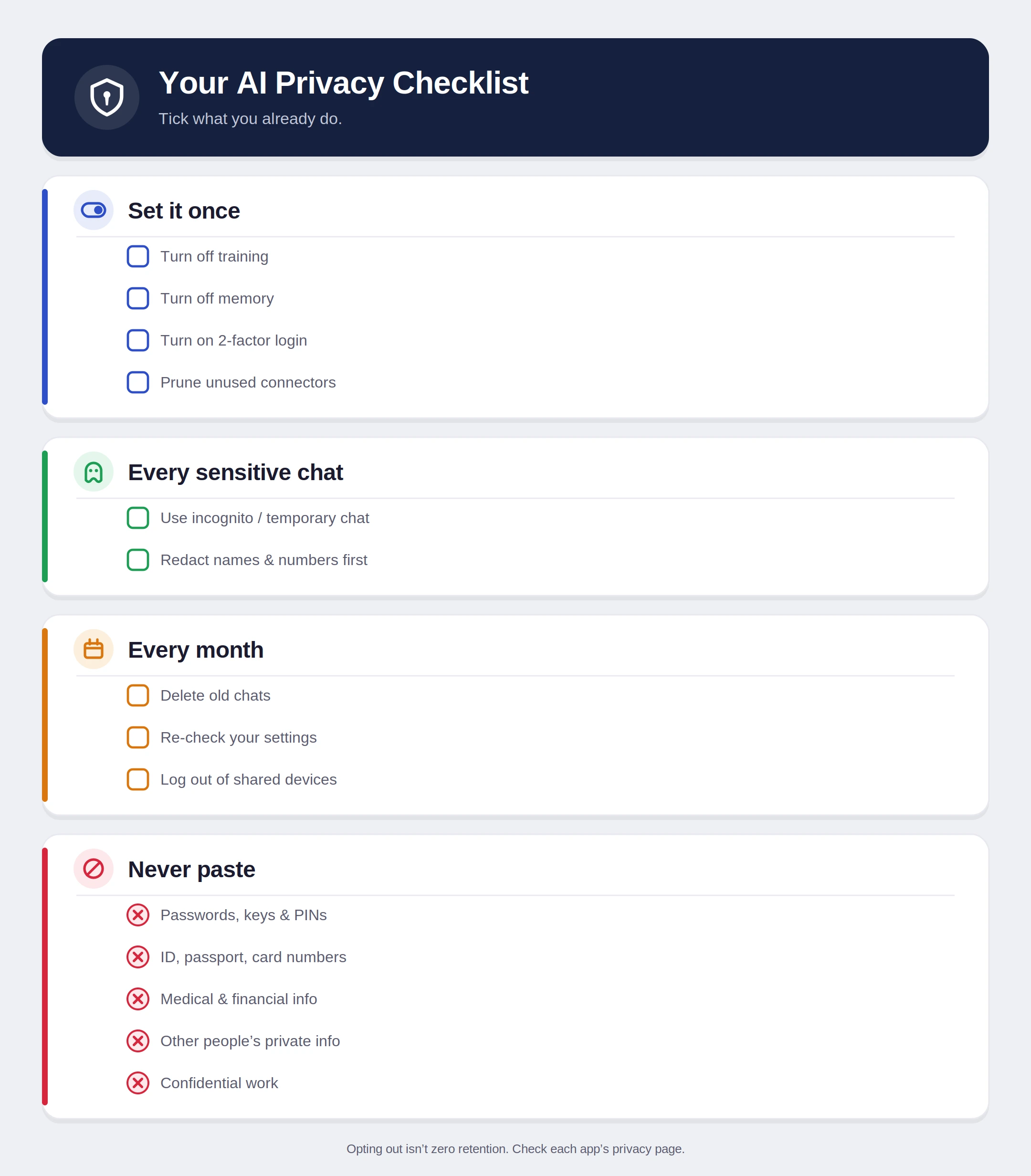
The most critical step for any user is to opt out of data training. This ensures that while the company may still store the data for safety monitoring, the information is not used to improve future iterations of the model.
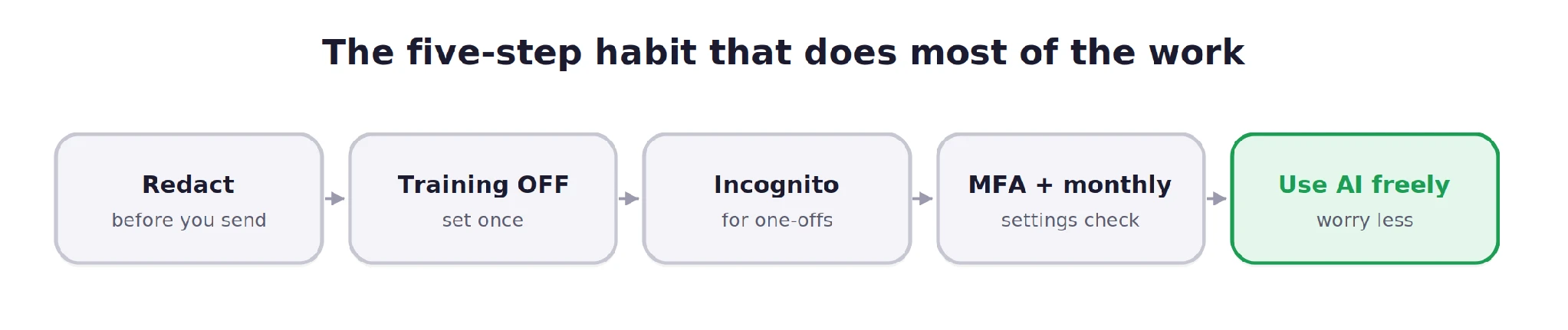
- ChatGPT: Users must navigate to Settings, then Data Controls, and toggle off "Improve the model for everyone." OpenAI notes that while this stops training, conversations are still stored for 30 days to monitor for abuse before being permanently deleted.
- Claude (Anthropic): In the Privacy settings, users can find the option "Help improve Claude." Disabling this prevents Anthropic from using personal data for model refinement.
- Gemini (Google): Privacy is managed through the "Gemini Apps Activity" hub. Turning this off stops Google from saving prompts to the user’s Google Account for training purposes.
- Grok (X/Twitter): Users must navigate to Privacy and Safety settings on the X platform to disable data-sharing specifically for the Grok model.
Layer 2: Utilizing Incognito and Temporary Modes
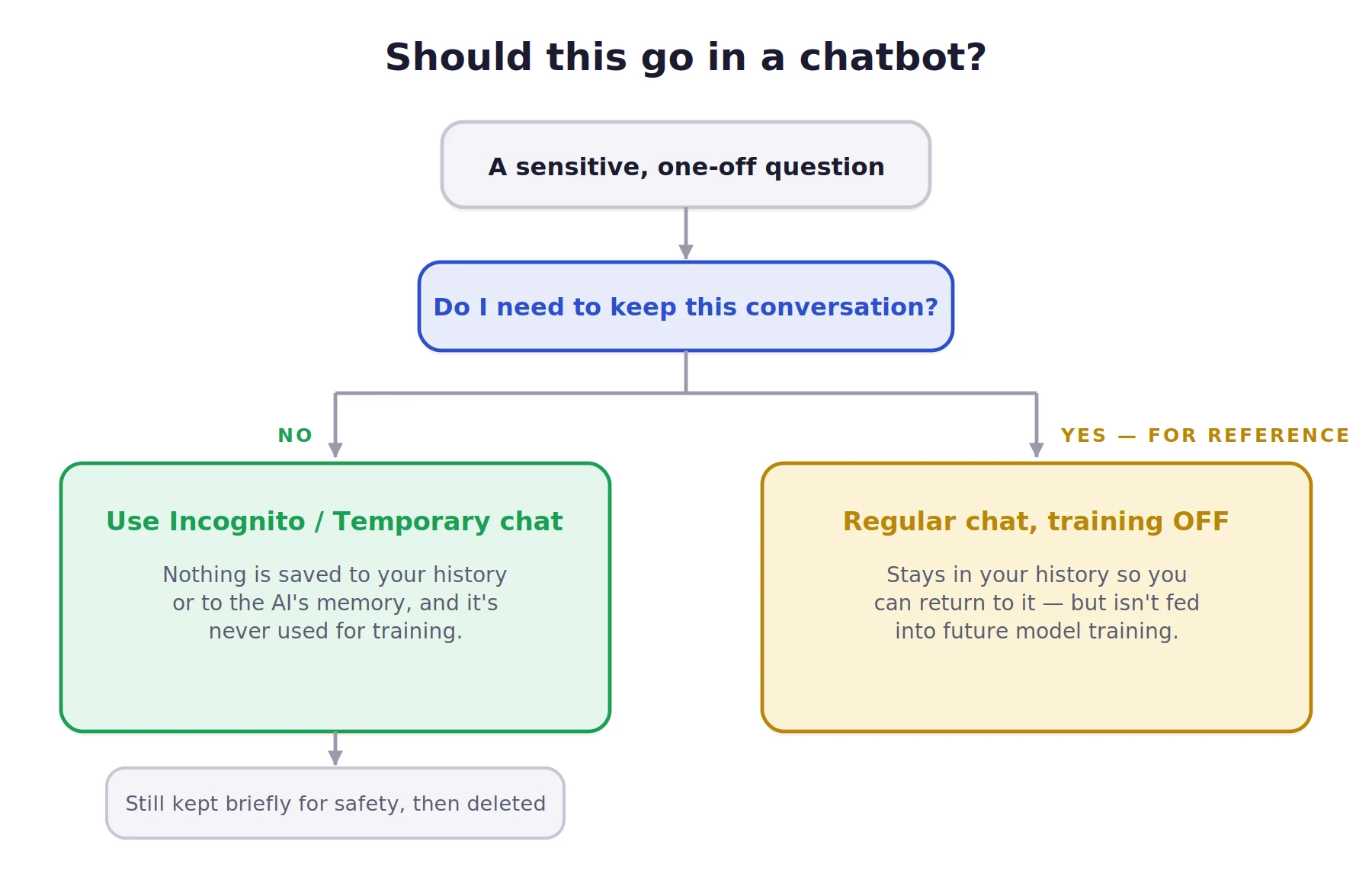
For tasks involving sensitive but non-confidential information, "Temporary" or "Incognito" modes offer a higher level of ephemeral interaction. In ChatGPT’s "Temporary Chat" mode, the system does not record history, does not use the conversation for training, and does not "remember" the interaction for future sessions.
Anthropic’s Claude offers a similar feature, which experts consider slightly more robust in its data handling. However, users must remain aware that even in these modes, the service provider maintains a short-term log (typically 30 days) to comply with legal requirements and safety protocols. These modes are a "ghost icon," not a "bulletproof vest"; they hide the data from the user’s history and the model’s memory, but not from the company’s infrastructure entirely.
Layer 3: Behavioral Hygiene and Redaction
The most effective form of privacy is the proactive redaction of sensitive data. Journalistic standards for AI usage suggest the "Postcard Rule": never type anything into a chatbot that you would not be comfortable writing on the back of a postcard sent through the mail.
Instead of providing specific details, users should practice "Generic Prompting." For example, rather than uploading a specific medical report, a user should ask for a general explanation of the medical terms found within such a report. By removing Personally Identifiable Information (PII) such as names, social security numbers, and specific addresses, the user maintains the utility of the AI without the associated identity risk.
Supporting Data: The Cost of Information Leaks
The necessity of these privacy measures is underscored by the rising cost of data breaches. According to a 2024 study by IBM and the Ponemon Institute, the global average cost of a data breach reached $4.88 million. For organizations, the "leakage" of intellectual property into AI training sets represents a hidden cost that could manifest years later in the form of lost competitive advantage or regulatory fines.
Furthermore, a survey conducted by Cyberhaven found that approximately 11% of data employees paste into LLMs is sensitive. This includes everything from client data and source code to strategic plans. As AI adoption reaches nearly 80% in the corporate sector, the surface area for potential data exposure has expanded exponentially.
Official Responses and the Move Toward Local AI
Tech giants have responded to these concerns by diversifying their product lines. OpenAI, Microsoft, and Google now offer "Enterprise" versions of their AI tools. These versions are governed by different contractual terms, often including Zero Data Retention (ZDR) clauses, which legally prohibit the provider from storing or training on any user data.
For the most sensitive applications, a growing segment of the market is moving toward "Local AI." Using open-source models like Meta’s Llama or Mistral, users can run AI entirely on their own hardware. This eliminates the need for an internet connection or a third-party server, ensuring that data never leaves the user’s device. While this requires significant computational power (often in the form of high-end GPUs), it is the only method that provides absolute privacy.
Implications for the Future of Human-AI Interaction
The evolution of AI privacy suggests a future where "Data Sovereignty" becomes a standard feature rather than an optional setting. As users become more sophisticated, the demand for transparent, verifiable privacy will likely force AI companies to move toward edge computing, where processing happens on the user’s phone or laptop rather than in the cloud.
Until that technological shift is complete, the responsibility remains with the individual. The digital equivalent of "locking the door" in the AI era is not total avoidance, but rather informed engagement. By utilizing the available toggles, embracing temporary modes, and practicing strict data redaction, users can harness the power of generative AI without compromising their digital identity or professional integrity. In the final analysis, the most powerful privacy tool is not a line of code, but the user’s own discretion before hitting the "send" button.