Google DeepMind has officially unveiled DiffusionGemma, an experimental open-weight model that fundamentally alters the standard approach to text generation in Large Language Models (LLMs). Built upon the Gemma 4 26B A4B Mixture-of-Experts (MoE) foundation, DiffusionGemma departs from the traditional autoregressive method of writing text one token at a time. Instead, it utilizes a diffusion-based architecture to generate and refine entire blocks of tokens in parallel. This shift is designed to address the inherent inefficiencies of running large models on local hardware, where memory bandwidth often becomes a bottleneck for sequential processing. By treating text generation as a multi-step refinement process on a fixed canvas, DiffusionGemma provides a glimpse into a future where local AI inference is optimized for high-speed drafting, editing, and structured data tasks.
The Architectural Evolution: From Sequential to Parallel
For several years, the AI industry has been dominated by autoregressive transformers. These models, including the GPT and Gemini series, predict the next token based on all preceding tokens. While this method ensures high-quality coherence and strong instruction following, it is inherently sequential. In cloud environments, providers mitigate the resulting latency by batching thousands of user requests simultaneously to keep Graphics Processing Units (GPUs) fully utilized. However, for a single local user running a model on a consumer-grade GPU, the hardware often sits idle while waiting for weights to move from memory for each individual token.

DiffusionGemma addresses this "memory-bound" problem by shifting the workload toward "compute-bound" tasks. Rather than generating a single token, the model works on a 256-token canvas. It applies parallel compute to refine this entire block of text through multiple iterations. This approach is more akin to a digital artist refining a sketch into a high-resolution image than a typewriter producing text character by character. For local users, this means that the GPU can process larger chunks of information at once, significantly reducing the perceived latency during long-form text generation.
Technical Framework and the Mixture-of-Experts Foundation
DiffusionGemma is a 25.2 billion parameter model, yet it maintains efficiency through its A4B Mixture-of-Experts architecture. During any given inference step, the model only activates approximately 3.8 billion parameters. This allows it to offer the reasoning capabilities of a larger model while maintaining the speed and memory footprint of a much smaller one.
The architecture is divided into three distinct operational stages:

-
Encoder Prefill: The model first processes the user’s prompt to create a Key-Value (KV) cache. Unlike some experimental models that re-process the prompt constantly, DiffusionGemma stores this context, allowing the subsequent diffusion steps to focus entirely on generating the response without redundant computation.
-
Denoising Decoder: This is the core of the diffusion process. The decoder operates on a 256-token canvas using bidirectional attention. In a standard transformer, a token can only "see" the tokens that came before it. In DiffusionGemma, every token in the block can attend to every other token. This allows the model to maintain better internal consistency within a block, as it can adjust the beginning of a sentence based on how the end of the sentence is forming.
-
Block-Autoregressive Multi-Canvas Sampling: To handle responses longer than the 256-token limit, DiffusionGemma employs a hybrid approach. It generates a block, finalizes it, and then uses that block as context to start a new 256-token canvas. This "block-by-block" progression combines the speed of parallel generation with the long-context coherence of sequential generation.
The Mechanics of Discrete Text Diffusion
The concept of diffusion is well-established in image generation, where models like Stable Diffusion start with Gaussian noise and gradually refine it into a clear image. Applying this to text, however, presents a unique challenge: text is discrete, not continuous. You cannot have "half a token" in the same way you can have a semi-transparent pixel.
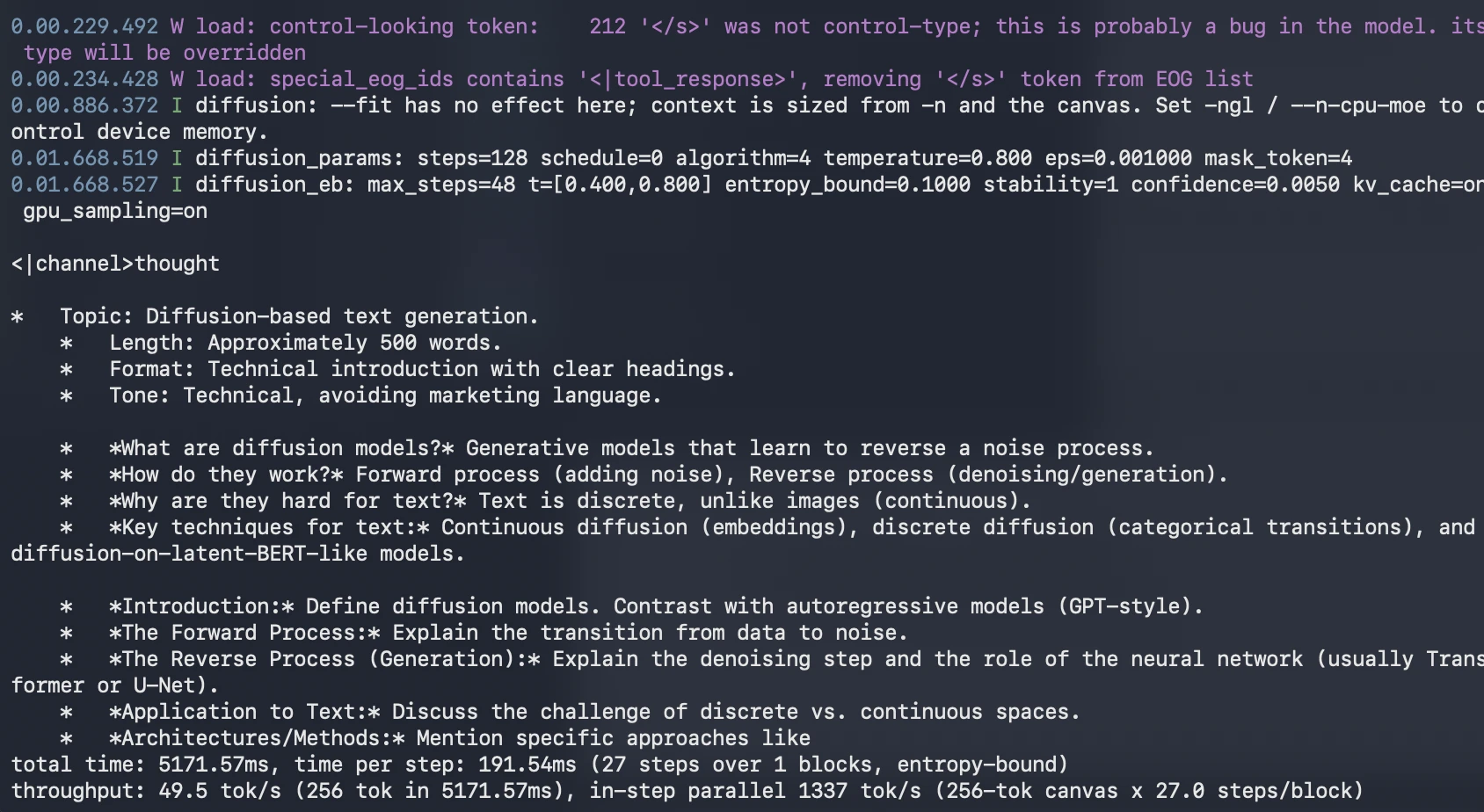
DiffusionGemma solves this by using a process of iterative refinement. It begins by filling the 256-token canvas with random placeholder tokens or "noise." Over a series of steps, the model predicts the most likely tokens for the entire canvas simultaneously. In the early steps, the model may be highly uncertain, but as the iterations progress, it replaces low-confidence tokens with higher-confidence ones. This allows the model to "self-correct" during the generation process—an ability that standard autoregressive models lack, as they are typically stuck with whatever token they previously committed to the sequence.
Comparative Performance and Benchmarking
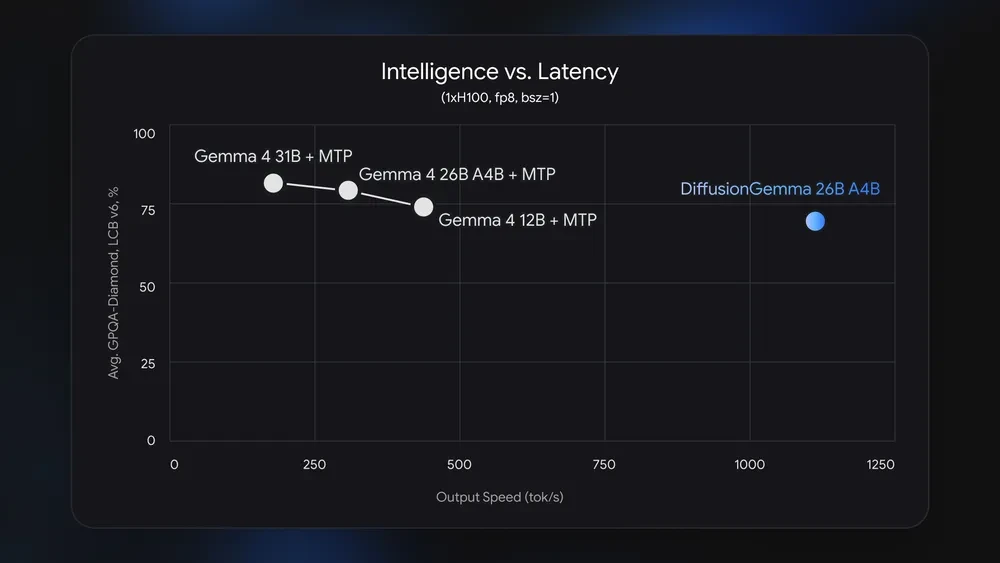
In terms of raw quality, Google DeepMind notes that DiffusionGemma is an experimental model and does not currently outperform the standard Gemma 4 26B A4B in most academic benchmarks. Standard autoregressive models remain the gold standard for complex reasoning, mathematical problem solving, and nuanced coding tasks.
However, DiffusionGemma is not intended to be a direct competitor in quality, but rather a leader in latency-sensitive applications. Benchmark data indicates that while Gemma 4 leads in categories like science reasoning and long-context retrieval, DiffusionGemma excels in "Time to First Block" and "Total Generation Time" for local inference. It is specifically optimized for workflows where speed is the primary requirement, such as real-time writing assistance, code infilling, and fast drafting.
The model’s bidirectional nature also makes it superior for "infilling" tasks—where a user provides the beginning and end of a paragraph and asks the AI to fill in the middle. Traditional models struggle with this because they generate from left to right, whereas DiffusionGemma views the entire block as a single optimization problem.
Implementation Chronology and Local Deployment
The development of DiffusionGemma follows a clear trajectory in Google’s open-weight model strategy. Following the release of the original Gemma series in early 2024 and the subsequent Gemma 2 and Gemma 4 iterations, Google has increasingly focused on providing developers with specialized tools for local deployment.
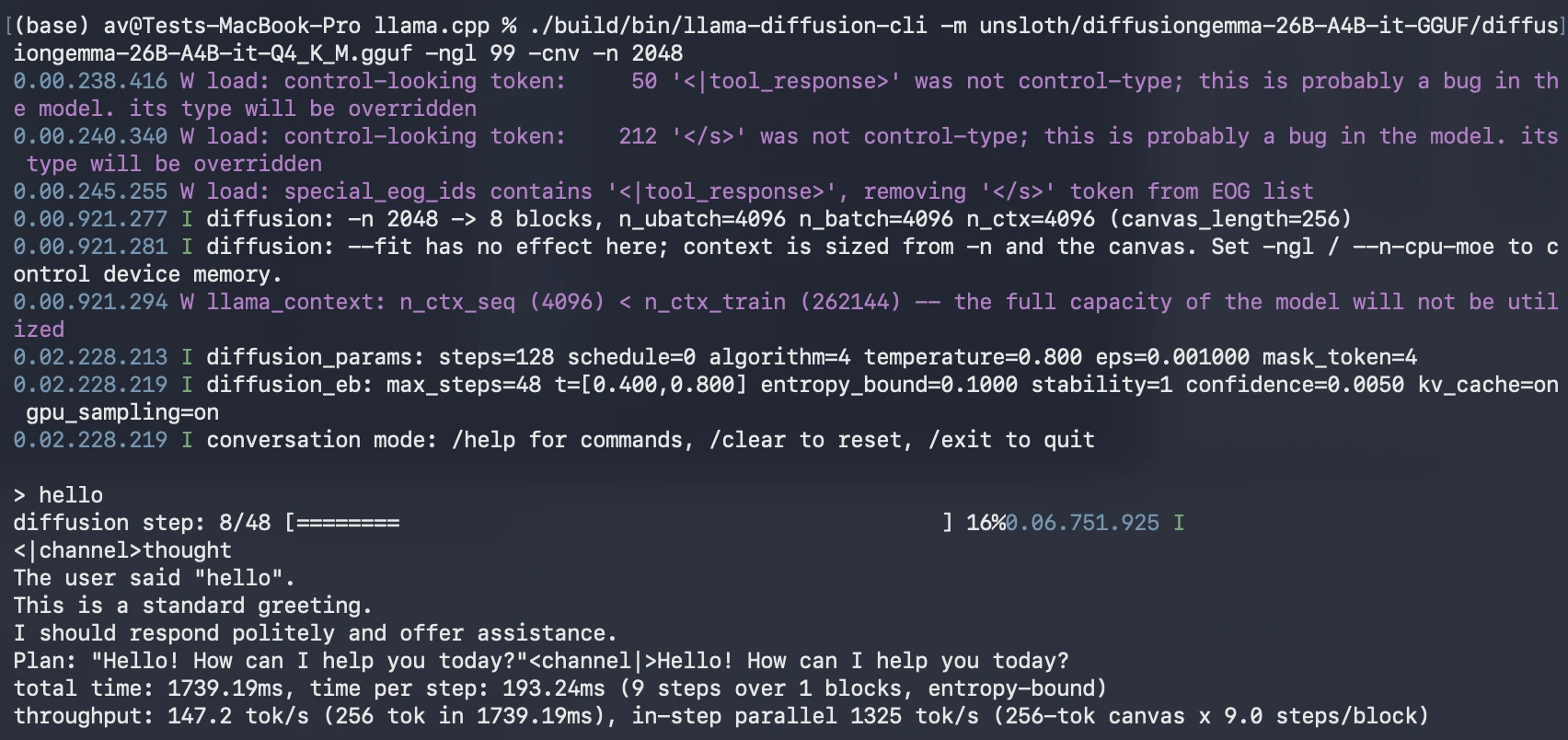
For developers looking to evaluate DiffusionGemma, the model is currently accessible via the Unsloth GGUF version, which is optimized for memory-efficient local execution. The primary method for running the model is through a dedicated branch of the llama.cpp repository, specifically pull request 24423, which introduces the llama-diffusion-cli.
The deployment process involves:
- Installing dependencies such as
cmakeand CUDA drivers for NVIDIA hardware. - Cloning the
llama.cpprepository and checking out the experimental diffusion branch. - Building the
llama-diffusion-clitarget. - Downloading the quantized
Q4_K_MGGUF model files.
This local setup allows developers to observe the unique "visual" nature of diffusion generation, where the text appears to fluctuate and settle into a final form, rather than streaming in a linear fashion.
Broader Implications for the AI Ecosystem
The release of DiffusionGemma signals a broader shift in how the industry views the "bottleneck" of AI. For years, the focus was on parameter count and data scale. As hardware limits are reached, particularly on the "edge" (laptops, workstations, and mobile devices), the focus is shifting toward algorithmic efficiency.
Industry analysts suggest that diffusion-based text models could lead to a new generation of "interactive" AI. In current systems, if an LLM makes a mistake at the beginning of a long paragraph, it often continues to hallucinate based on that error. A diffusion model’s ability to revise its own "draft" before presenting it to the user could lead to more reliable outputs in structured formats like JSON or code.
Furthermore, DiffusionGemma’s architecture is highly conducive to speculative decoding. In this scenario, a smaller, faster diffusion model could quickly draft a block of text, which a larger, more capable autoregressive model then verifies or adjusts. This hybrid approach could combine the best of both worlds: the lightning speed of diffusion with the rigorous quality of traditional transformers.
Conclusion
DiffusionGemma represents a significant experimental milestone for Google DeepMind. While it may not yet replace the standard autoregressive models used in general-purpose chatbots, it establishes a new framework for high-speed local AI. By leveraging parallel compute and bidirectional attention, it addresses the specific hardware constraints of local GPUs and opens the door for specialized applications in coding, editing, and real-time content generation. As the open-source community continues to refine the implementation of diffusion-based text generation, the lessons learned from DiffusionGemma are likely to influence the design of future lightweight, high-performance models intended for the next generation of personal computing.