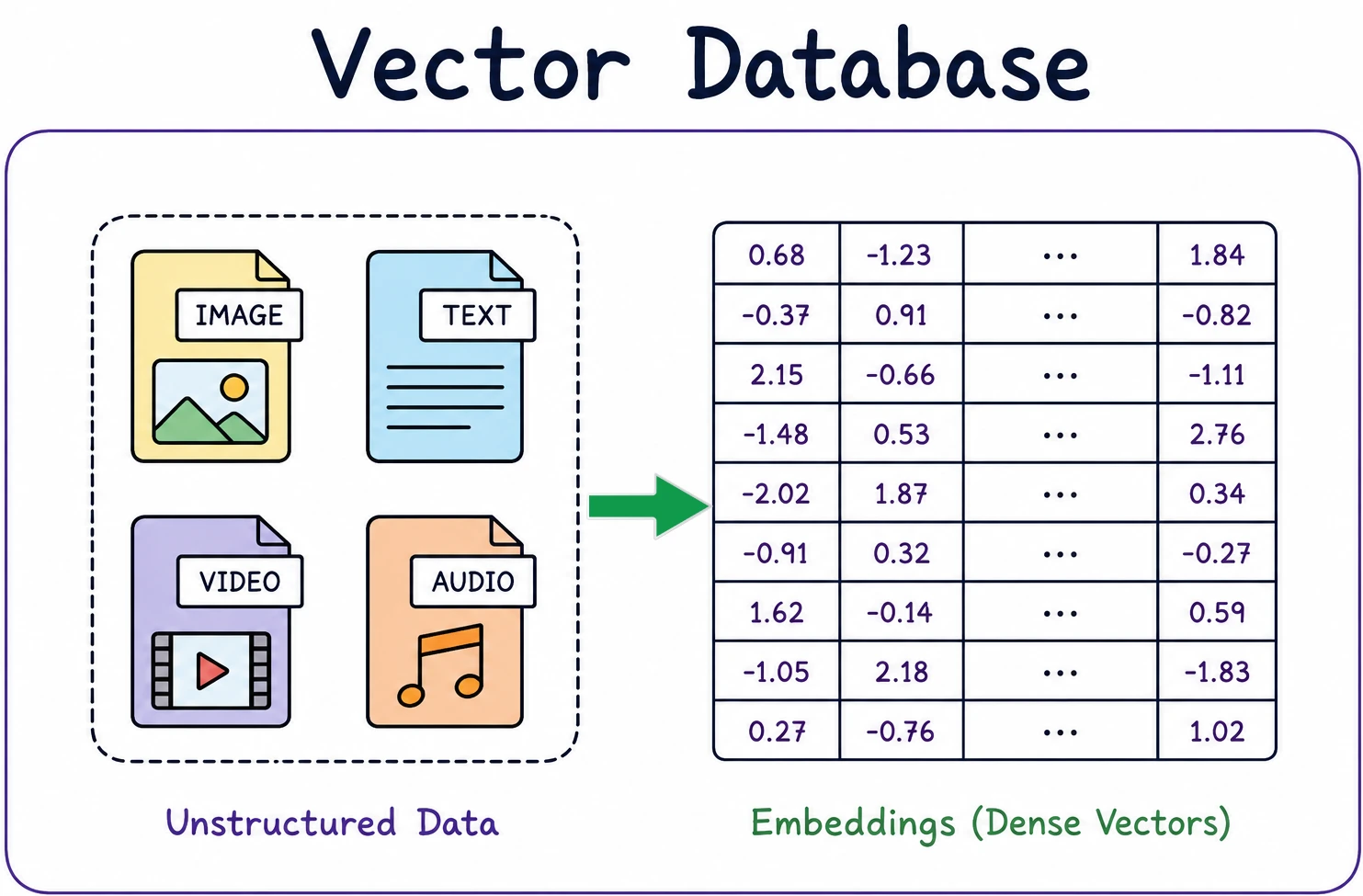
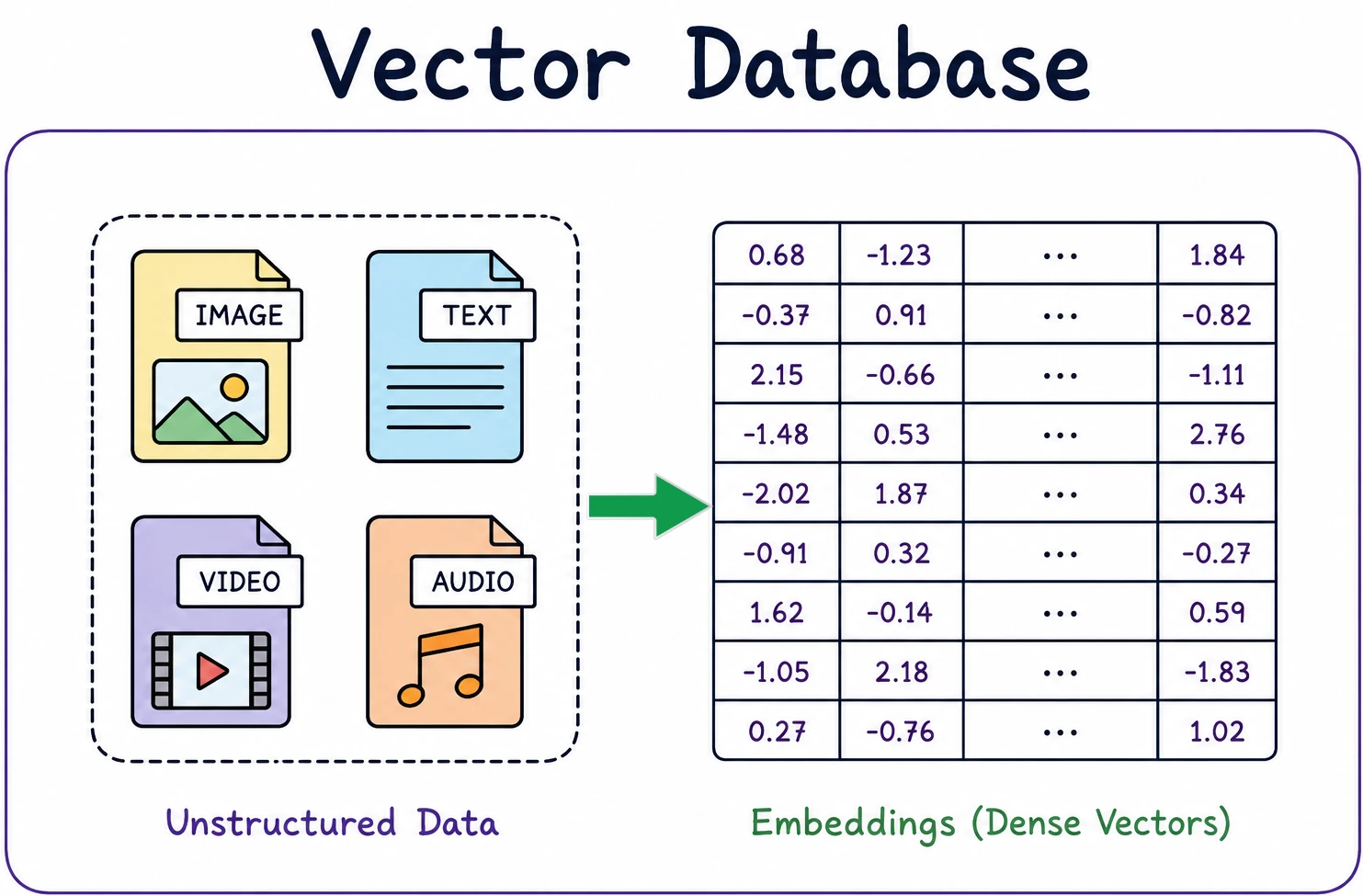
The rapid ascent of generative artificial intelligence and large language models (LLMs) has fundamentally altered the requirements for data architecture, moving the industry away from simple keyword matching toward the complex world of semantic understanding. As organizations increasingly adopt Retrieval-Augmented Generation (RAG) and semantic search to enhance their AI applications, vector databases have emerged as the critical infrastructure required to store, index, and retrieve high-dimensional embeddings at a scale previously unimaginable. Unlike traditional relational databases that organize data in rigid rows and columns, vector databases are engineered to handle mathematical representations of data—known as embeddings—that capture the nuanced meaning of text, images, audio, and video. Choosing the appropriate vector database has become a pivotal decision for Chief Technology Officers and software architects, as the selection directly influences system performance, operational costs, and the long-term scalability of AI-driven products.
The Mathematical Foundation: Understanding Embeddings and Vector Search
To understand the necessity of vector databases, one must first grasp the concept of embeddings. In the context of machine learning, an embedding is a numerical representation of data where similar items are placed closer together in a high-dimensional space. For instance, a sentence about "automotive engineering" and a sentence about "electric vehicles" would produce vectors that are mathematically adjacent, even if they share no specific keywords. These vectors typically consist of hundreds or thousands of floating-point numbers, such as [0.12, -0.45, 0.78…], which encode the semantic "vibe" or essence of the content.
Traditional databases, such as PostgreSQL or MySQL, are optimized for exact matches and range queries, such as identifying a user by an ID or finding transactions within a specific date range. However, they struggle with the "nearest neighbor" problem inherent in AI. Searching through millions of high-dimensional vectors to find the most similar match using brute-force methods would result in prohibitive latency. Vector databases solve this by utilizing Approximate Nearest Neighbor (ANN) algorithms. These algorithms, including Hierarchical Navigable Small World (HNSW) and Inverted File Index (IVF), create graph-like structures and data partitions that allow systems to locate relevant information in milliseconds across datasets containing billions of entries.
The effectiveness of these searches is measured by similarity metrics. The three most common are Cosine Similarity, which measures the angle between vectors to determine conceptual similarity; Euclidean Distance (L2), which calculates the straight-line distance between points; and Dot Product, which factors in both the angle and the magnitude of the vectors.
A Chronology of the Vector Database Revolution
The transition from keyword-based search to vector-based semantic search did not happen overnight, but rather through a series of technological milestones over the last decade.
In the mid-2010s, the development of Word2Vec and later BERT (Bidirectional Encoder Representations from Transformers) by Google researchers laid the groundwork for modern embeddings. By 2019, the demand for specialized storage led to the birth of Milvus, an open-source project designed for massive-scale vector data. However, the true explosion in the sector occurred in late 2022 following the public release of ChatGPT. This event served as a catalyst, forcing enterprises to find ways to "ground" LLMs in their proprietary data to prevent hallucinations—a process that requires the high-speed retrieval capabilities of a vector database.
By 2023, the market saw a surge in funding and adoption for specialized players like Pinecone, which pioneered the "Serverless" vector database model, and Weaviate, which integrated vector search with traditional object storage. Simultaneously, established database providers began racing to add vector capabilities to their existing stacks, most notably through the pgvector extension for PostgreSQL.
Comparative Analysis of the Leading Vector Databases
As of 2024, six primary contenders have dominated the landscape, each catering to different organizational needs and technical requirements.
Pinecone: The Managed SaaS Standard
Pinecone is widely regarded as the industry leader for organizations seeking a fully managed, "zero-ops" experience. It was built specifically for machine learning workflows and offers a cloud-native architecture that abstracts away the complexities of sharding and indexing. Its primary value proposition is ease of use; developers can initialize an index via a simple API call and scale to billions of vectors without managing underlying servers. Pinecone’s recent introduction of serverless architecture has further lowered the barrier to entry, allowing companies to pay only for the data they store and the queries they execute.
Weaviate: The Modular Open-Source Choice
Written in Go, Weaviate is an open-source vector database that emphasizes flexibility and modularity. Unlike databases that only store vectors, Weaviate allows users to store both the data objects and their corresponding embeddings. It supports "hybrid search," which combines vector similarity with traditional keyword search (BM25), a feature that many engineers argue is essential for maintaining accuracy in specialized domains like legal or medical research. Weaviate can be self-hosted via Docker or Kubernetes, providing a level of data sovereignty that is often required by highly regulated industries.
Qdrant: The Efficiency Specialist
Qdrant, developed in Rust, has gained a reputation for being exceptionally memory-efficient and fast. Its architecture is designed to handle complex filtering alongside vector searches, allowing users to query not just for "similar items" but for "similar items that cost less than $50 and are in stock." The use of Rust ensures high performance and safety, making it a favorite for high-throughput applications where query latency (p99) must remain low under heavy load.
Milvus: The Enterprise Heavyweight
For organizations operating at the extreme edge of scale—handling trillions of vectors—Milvus remains the standard. It is a cloud-native, distributed database that decouples storage from compute, allowing each to scale independently. While it has a steeper learning curve than ChromaDB or Pinecone, its ability to handle massive, distributed workloads makes it the choice for large-scale tech companies and research institutions. The "Milvus Lite" version now offers a bridge for developers who want to start small and eventually migrate to a full-scale deployment.
pgvector: The Pragmatic SQL Extension
For many enterprises, the best vector database is the one they already have. pgvector is an extension for PostgreSQL that adds a vector data type and specialized indexing methods like HNSW. The primary advantage of pgvector is that it allows developers to keep their relational data and their vector data in the same system, enabling complex SQL joins and ensuring ACID compliance. While it may not scale as effortlessly to billions of vectors as a specialized engine like Milvus, it is more than sufficient for tens of millions of entries and is supported by major cloud providers like AWS and Google Cloud.
ChromaDB: The Developer-First Prototyping Tool
ChromaDB has become the default choice for the "AI hacker" community and is frequently featured in LangChain and LlamaIndex tutorials. Its design philosophy prioritizes developer experience above all else. It can run entirely within a Python notebook or a local process, making it ideal for prototyping and local development. While it lacks some of the advanced enterprise features of its competitors, its simplicity has made it a cornerstone of the AI development ecosystem.
Performance Metrics and Operational Data
When evaluating these systems, performance is typically measured across several key metrics: indexing speed, query latency, recall (accuracy), and throughput.
Recent industry benchmarks for datasets of approximately one million 384-dimensional vectors show that Qdrant and Milvus often lead in query throughput, capable of handling over 1,000 queries per second (QPS) on a single node. Pinecone typically maintains a p50 latency of 5–10 milliseconds, making it highly competitive for real-time applications. In terms of memory consumption, pgvector and Qdrant are noted for their efficiency, often requiring less than 2 GB of RAM per million vectors, whereas feature-rich systems like Weaviate may require slightly more to support their advanced metadata schemas.
| Feature | Pinecone | Weaviate | Qdrant | Milvus | pgvector | ChromaDB |
|---|---|---|---|---|---|---|
| Primary Model | Managed SaaS | Open Source | Open Source | Open Source | Extension | Open Source |
| Language | Go/Rust | Go | Rust | Go/C++ | C (Postgres) | Python/JS |
| Hybrid Search | Native | Native | Native | Native | Partial | No |
| Best For | Fast Production | Feature-Rich AI | Cost Efficiency | Global Scale | SQL Integration | Prototyping |
Industry Implications and Expert Analysis
The shift toward vector databases represents a fundamental change in how software "remembers" and "retrieves" information. Industry analysts suggest that we are moving toward a "Vector-First" world, where the ability to query by meaning will be as common as querying by ID.
"The challenge for modern enterprises isn’t just storing the data; it’s making the data useful for the model," says one senior AI architect at a leading Silicon Valley firm. "The vector database is the bridge between the static knowledge of the enterprise and the reasoning capabilities of the LLM."
The emergence of "Hybrid Search" is perhaps the most significant trend in the sector. Experts have found that while vector search is excellent at finding concepts, it can sometimes fail at finding specific proper nouns or serial numbers. By combining vector search with traditional keyword search—a capability pioneered by Weaviate and Qdrant—developers can achieve the "best of both worlds," ensuring that search results are both semantically relevant and factually precise.
Future Outlook: Multimodal and Real-Time Search
Looking ahead, the next frontier for vector databases lies in multimodal search and real-time indexing. As models like GPT-4o and Gemini 1.5 Pro become more adept at processing images and video, the demand for databases that can store and query multimodal embeddings will skyrocket. Furthermore, as AI agents become more autonomous, the need for "dynamic memory"—where a database can index and retrieve new information in real-time without long "cold start" periods—will become a critical differentiator.
Ultimately, the choice of a vector database depends on the specific lifecycle of the project. For a startup looking to launch a MVP in a week, ChromaDB or Pinecone may be the logical choice. For a legacy enterprise with a massive PostgreSQL footprint, pgvector offers the path of least resistance. For a global corporation building a next-generation recommendation engine, Milvus or Qdrant provide the necessary performance ceiling. Regardless of the choice, the vector database has solidified its place as a cornerstone of the modern AI stack, transforming the abstract mathematics of embeddings into a practical tool for global innovation.