The landscape of generative artificial intelligence has long been dominated by the autoregressive paradigm, a method where models predict the next token in a sequence based on all preceding tokens. While this "typewriter" style of generation has yielded high-quality results in models like GPT-4 and Gemini, it presents a significant efficiency bottleneck, particularly for local hardware users. In a move to address these latency constraints, Google DeepMind has released DiffusionGemma, an experimental open-weight model that leverages diffusion-based generation to produce text in parallel blocks. By departing from the sequential constraints of traditional Large Language Models (LLMs), DiffusionGemma represents a fundamental shift in how compute resources are utilized during inference, prioritizing parallel throughput over sequential memory bandwidth.
The Evolution of the Gemma Ecosystem and the Rise of Diffusion
The release of DiffusionGemma marks a significant milestone in the evolution of Google’s Gemma family of models. Since the debut of the original Gemma models—built from the same technology used to create Gemini—Google has consistently expanded its open-weight offerings to cater to the research and developer communities. The trajectory began with standard dense models, followed by the introduction of Mixture-of-Experts (MoE) architectures designed to balance parameter count with computational efficiency.

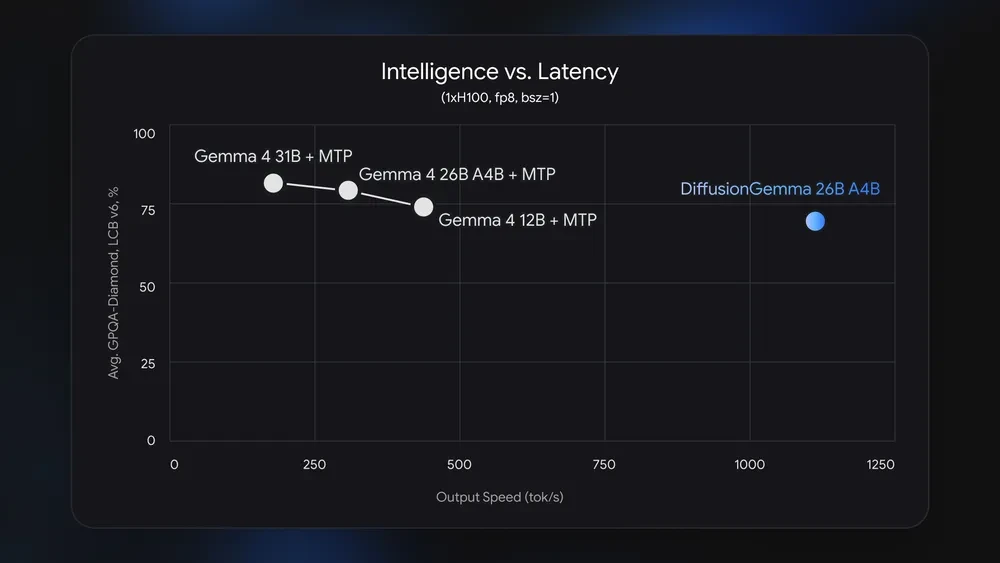
DiffusionGemma is built upon the Gemma 4 26B A4B MoE foundation, a model featuring 25.2 billion total parameters, of which approximately 3.8 billion are active during any given inference step. The development of this model stems from a critical observation regarding modern hardware: while cloud providers can hide the latency of autoregressive models by batching thousands of user requests, a single user running a model on a local GPU often finds their hardware idling. In standard LLMs, the GPU spends the majority of its time moving weights from memory rather than performing calculations. DiffusionGemma attempts to solve this "memory-bound" problem by transforming it into a "compute-bound" task, utilizing the GPU’s parallel processing power to refine 256 tokens simultaneously.
Technical Architecture: Bridging Discrete Text and Continuous Diffusion
The primary challenge in applying diffusion to text lies in the nature of the data itself. Traditional diffusion models, such as those used in image generation (e.g., Stable Diffusion), operate on continuous pixel values. Text, however, is discrete; there is no mathematical "middle ground" between two different vocabulary tokens. DiffusionGemma overcomes this by implementing a non-autoregressive, iterative refinement process.
The architecture is divided into three distinct phases:

-
Encoder Prefill and KV Caching: When a user provides a prompt, the model first processes the context through an encoder. This stage creates a Key-Value (KV) cache that stores the prompt’s representation. Unlike autoregressive models that must update this cache for every new token, DiffusionGemma uses the cached context as a static reference point for the entire duration of the diffusion process within a specific block.
-
The Bidirectional Denoising Decoder: This is the core innovation of DiffusionGemma. The model operates on a "canvas" of 256 tokens. During the generation phase, the decoder uses bidirectional attention, allowing every token position within the canvas to "see" every other token. This is a departure from the causal masking used in standard LLMs, where tokens can only attend to their predecessors. By looking both forward and backward, the model can ensure global coherence across the block as it iteratively replaces "noisy" or placeholder tokens with more probable ones.
-
Block-Autoregressive Multi-Canvas Sampling: To handle responses longer than the 256-token canvas limit, DiffusionGemma employs a hybrid approach. While it generates tokens within a block in parallel, it generates the blocks themselves sequentially. Once the first 256 tokens are refined and finalized, they serve as the context for the next 256-token canvas. This "block-by-block" progression allows the model to maintain the speed benefits of diffusion while supporting long-form content generation.
Performance Metrics and Benchmark Analysis
In evaluating DiffusionGemma, Google DeepMind has positioned the model as a "speed-first" alternative rather than a direct replacement for the standard Gemma 4 26B A4B. Internal benchmarks and early community testing indicate a nuanced trade-off between raw generation quality and responsiveness.
On standard reasoning and knowledge benchmarks—such as MMLU (Massive Multitask Language Understanding) and HumanEval (coding)—the traditional autoregressive Gemma 4 models continue to hold the lead. The sequential nature of autoregressive generation allows for more precise "chain-of-thought" reasoning, as each token is grounded in a finalized history. DiffusionGemma, by contrast, may occasionally sacrifice granular logic for the sake of parallel speed.
However, the latency data tells a different story. For local users with high-end consumer GPUs (such as the NVIDIA RTX 4090), DiffusionGemma can deliver text blocks significantly faster than its autoregressive counterparts can stream individual tokens. This makes it particularly effective for specific workflows:
- Fast Drafting: Generating large sections of text for emails, reports, or creative writing.
- Code Infilling: Predicting missing segments of code where the surrounding context provides strong hints.
- Structured Data Generation: Producing JSON or Markdown blocks where the layout is predictable.
- Interactive Editing: Allowing a model to "rewrite" a paragraph by refining the entire block at once.
Implementation and Community Adoption: The llama.cpp Integration
The rapid adoption of DiffusionGemma has been facilitated by the open-source community, specifically through tools like llama.cpp and Unsloth. Because DiffusionGemma requires a different decoding logic than standard transformers, traditional inference engines had to be adapted to support the block-diffusion approach.
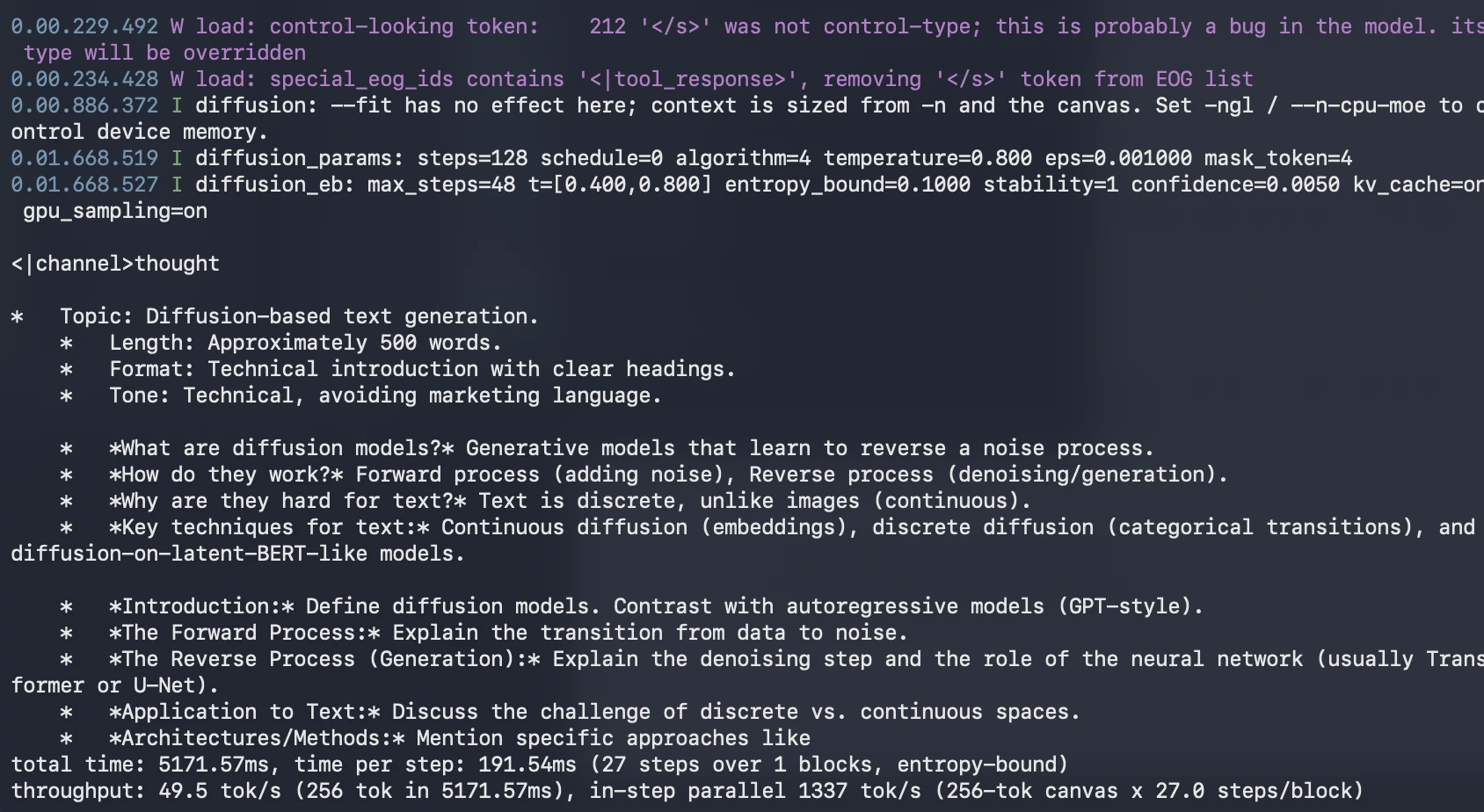
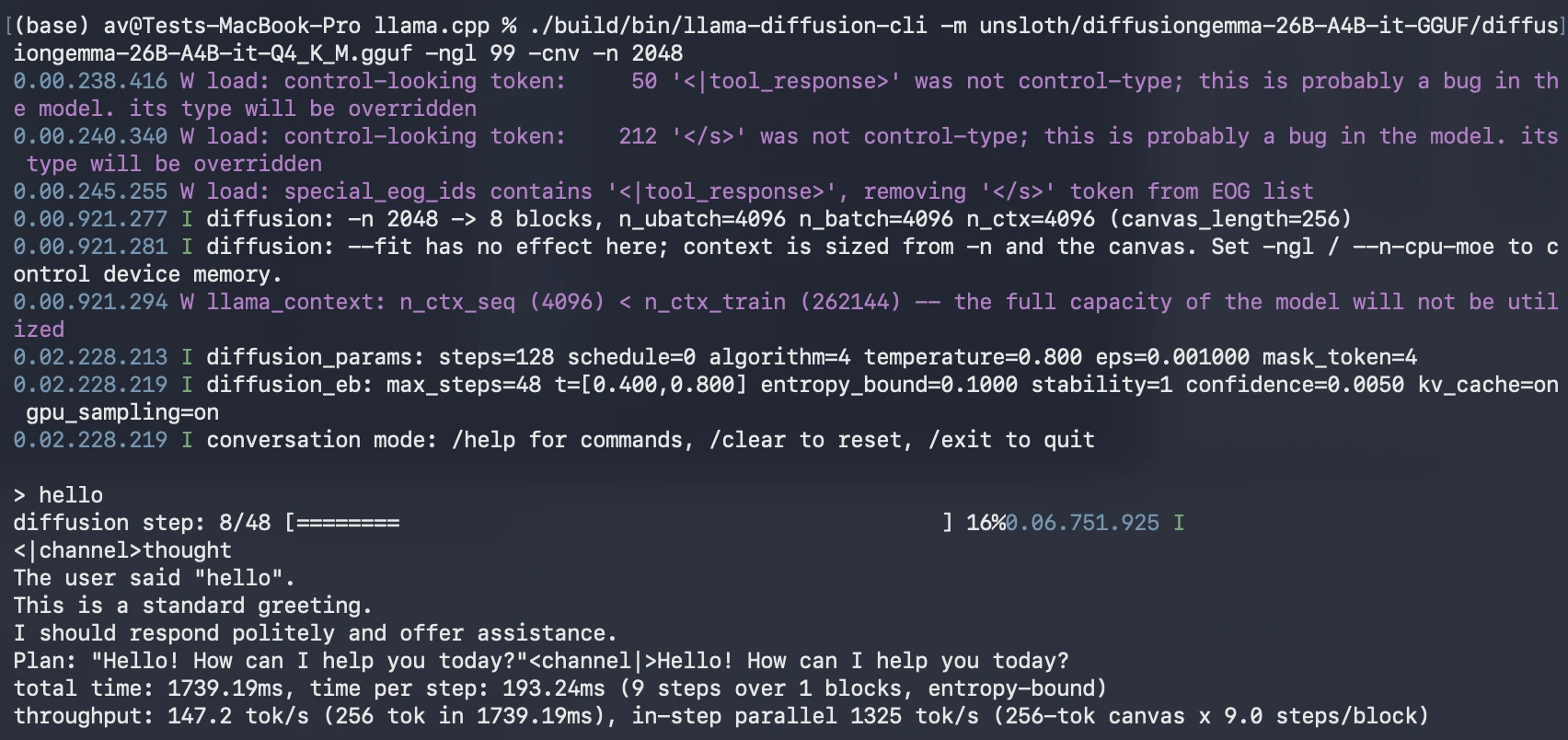
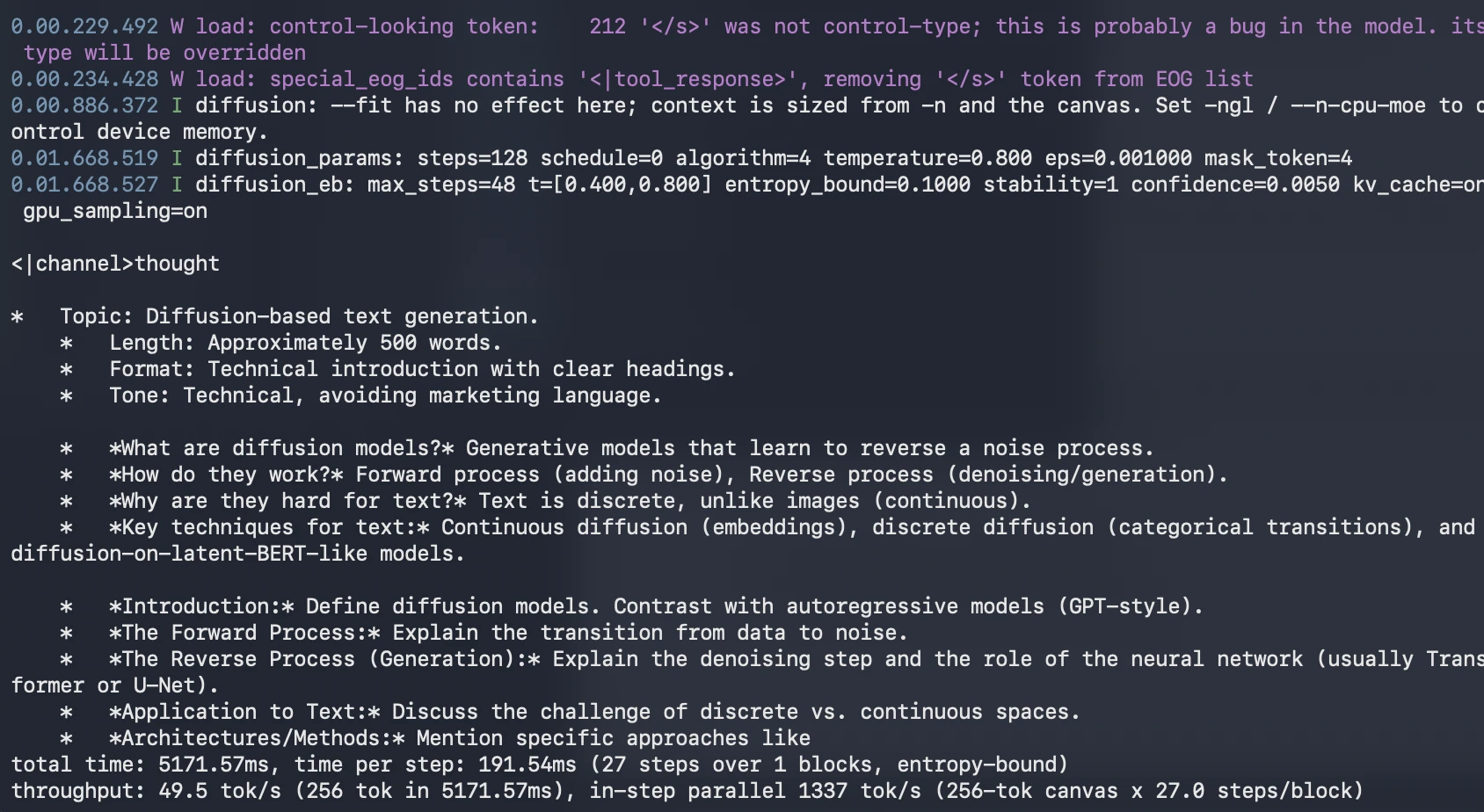
Technical contributors have introduced dedicated pull requests to the llama.cpp repository to enable a llama-diffusion-cli. This specialized interface allows users to visualize the diffusion process in real-time. Instead of seeing text appear from left to right, users witness a "shimmering" effect where the entire 256-token block starts as a jumble of characters and gradually snaps into coherent sentences over several refinement steps.
To make the 26B-parameter model accessible to users without enterprise-grade hardware, quantization has played a vital role. The Q4_K_M GGUF (GPT-Generated Unified Format) version of DiffusionGemma has become the standard for local testing. This 4-bit quantization reduces the memory footprint significantly, allowing the model to fit within the VRAM of 16GB or 24GB consumer graphics cards while maintaining acceptable output quality.
Industry Reactions and Market Implications
The release of DiffusionGemma has sparked significant discussion among AI researchers and hardware manufacturers. For years, the industry has focused on "token-per-second" (TPS) as the primary metric for LLM performance. DiffusionGemma suggests that "blocks-per-second" or "time-to-complete-thought" might be a more relevant metric for future local AI applications.
Industry analysts suggest that this approach could influence the design of future NPU (Neural Processing Unit) architectures in laptops and smartphones. If diffusion becomes a standard for text generation, hardware designers may prioritize massive parallel execution units over the high-speed memory buses currently required to keep up with autoregressive models.
Furthermore, the "self-correction" capability inherent in diffusion models is seen as a major advantage. In an autoregressive model, if the model makes a mistake early in a sentence, that mistake is "locked in" and often leads to a hallucination or a logical collapse. In DiffusionGemma, because the model can revise the entire canvas during the denoising steps, it has the theoretical potential to catch and fix inconsistencies before the final output is presented to the user.
Broader Implications and the Future of Text Diffusion
DiffusionGemma serves as a "proof of concept" for a future where local AI is not just a smaller version of cloud AI, but a fundamentally different implementation optimized for local hardware. While it is currently labeled as an experimental model, its release provides the foundation for several potential advancements:
- Dynamic Canvas Sizes: Future iterations may allow for variable-length canvases, adjusting the block size based on the complexity of the prompt or the available GPU compute.
- Multi-Modal Diffusion: The same parallel refinement techniques could be applied to models that generate text and images simultaneously, ensuring tighter integration between descriptions and visuals.
- Hybrid Models: We may see models that use autoregressive generation for complex reasoning tasks and switch to diffusion for long-form descriptive tasks, optimizing for both quality and speed.
As Google DeepMind continues to refine the Gemma series, DiffusionGemma stands as a testament to the fact that the path to Artificial General Intelligence (AGI) is not a single track. By exploring alternative generation paradigms, researchers are uncovering new ways to make powerful AI more accessible, responsive, and efficient for the end user. For the developer community, the challenge now lies in finding the optimal use cases where the speed of parallel refinement outweighs the established reliability of sequential generation. The "typewriter" era of AI is facing its first major challenge from the "canvas" era, and the results could redefine the user experience of interactive AI.