The landscape of digital marketing and conversion rate optimization (CRO) currently stands at a crossroads between intuition-led experimentation and rigorous scientific inquiry. While A/B testing is fundamentally a randomized controlled trial (RCT)—a methodology that serves as the gold standard in fields such as physics, biology, and genetics—the common application of these tests in the digital space remains significantly outdated. Industry experts and statisticians have observed that the prevailing advice found in popular A/B testing literature often lags nearly 50 years behind the modern statistical approaches used in medical science and biostatistics. This discrepancy has led to a widespread "replication crisis" in marketing, where many reported "wins" fail to translate into long-term revenue because the underlying statistical foundations are flawed.
The primary challenges facing the industry today are categorized into three major systemic failures: the widespread misuse of statistical significance tests, a general disregard for statistical power, and the inherent inefficiency of classical "fixed-sample" testing models. To address these issues, a new paradigm known as the AGILE statistical approach is being introduced, drawing inspiration from the rigorous protocols used in clinical trials to ensure that data-driven decisions are both efficient and accurate.
The Pitfalls of "Data Peeking" and Significance Misuse
At the heart of most A/B testing platforms is the concept of statistical significance, yet the constraints of these tests are frequently ignored. Classical statistical tests, such as the Student’s T-test, were designed with a critical requirement: the sample size must be fixed in advance. In a standard scientific environment, a researcher determines they need a specific number of observations—for example, 20,000 users per variant—and only analyzes the data once that threshold is reached.
However, the reality of the digital boardroom often clashes with this mathematical necessity. Marketing teams, under pressure to deliver results or mitigate losses, frequently engage in "data peeking"—the practice of checking results daily and stopping a test early if a variant appears to be winning or losing. Without proper statistical adjustments, this behavior invalidates the test results.
Statistically, peeking at data multiple times increases the probability of a "false positive" or Type I error. While a standard 95% confidence level implies a 5% risk of a false positive, peeking just five times throughout the duration of a test can increase that actual error rate to over 16%. By the time a practitioner peeks ten times, the actual error probability is five times higher than what is reported by their software. This phenomenon creates a "Garbage In, Garbage Out" (GIGO) scenario, where companies implement changes based on illusory gains that are merely the result of natural variance in the data.
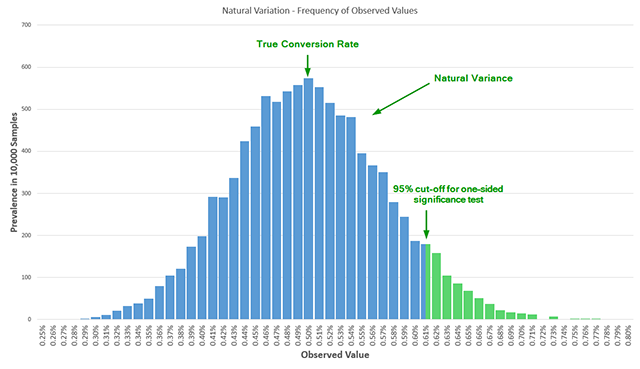
The Missing Metric: Statistical Power and Test Sensitivity
While much of the industry focuses on significance (the risk of being wrong about a win), very little attention is paid to statistical power, also known as test sensitivity. Statistical power represents the probability that a test will actually detect a lift if one truly exists. In a review of influential A/B testing literature published over the last decade, only a small fraction of resources even mentioned the concept, and fewer still explained its practical application.
Running an underpowered test is a common mistake that leads to "false negatives" or Type II errors. If a test lacks sufficient power, a variant that is actually superior may be discarded because the sample size was too small to distinguish the improvement from noise. This results in a massive waste of organizational resources, as weeks of design and development time are rendered moot by an insensitive measurement tool.
To achieve adequate power, practitioners must balance four variables: the historical baseline conversion rate, the desired significance threshold (usually 95%), the desired power (usually 80% or 90%), and the minimum effect size of interest (MDE). Many free online calculators default to a 50% power level—essentially a coin toss—which fails to provide the certainty required for high-stakes business decisions. When teams begin to use proper power calculations, they often find that the required sample sizes are much larger than they initially anticipated, forcing a difficult choice between the duration of the test and the level of certainty required.
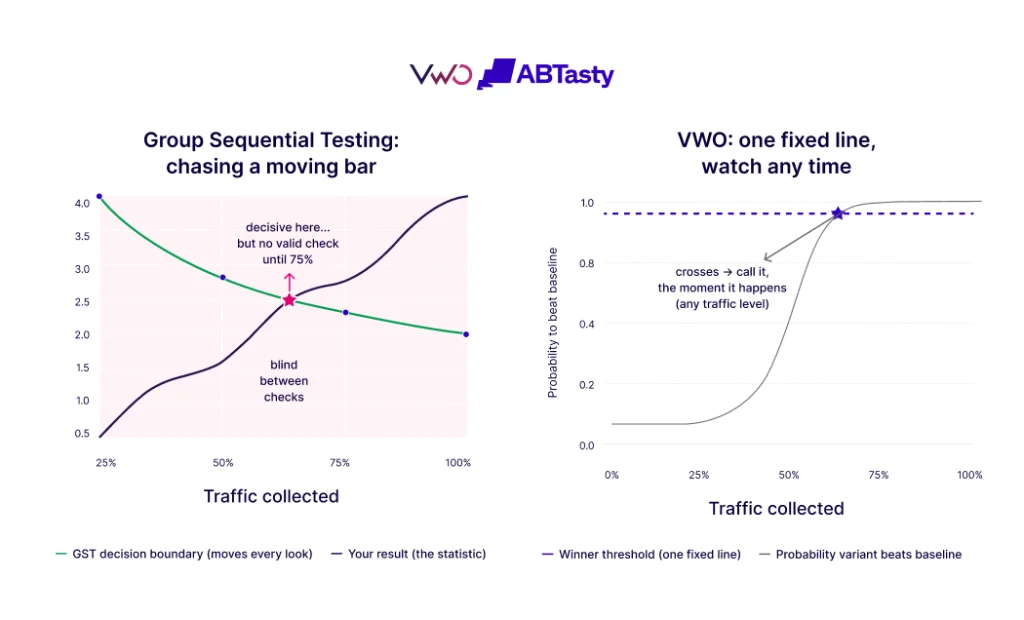
The Efficiency Gap in Classical Testing
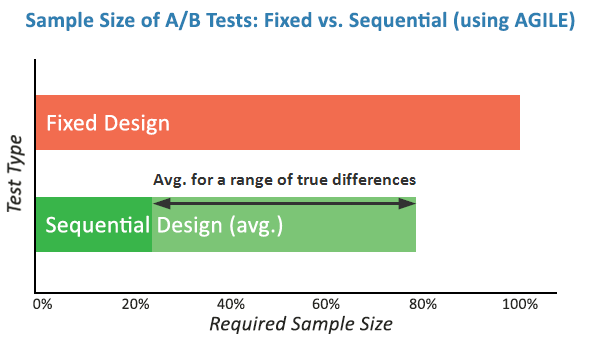
Classical "fixed-sample" tests are inherently inefficient for the fast-paced digital economy. These methods require a test to run to completion regardless of how extreme the early results might be. In a scenario where a new website variant is performing catastrophically, a classical test would technically require the practitioner to continue exposing users to the inferior version until the pre-set sample size is reached to maintain statistical integrity. Conversely, if a variant is performing exceptionally well, the company loses potential revenue by waiting weeks for a test to finish when the result is already apparent.
This inefficiency has been largely solved in the medical field through sequential analysis. In clinical trials, where human lives are at stake, researchers use interim monitoring to stop a trial early if a drug is found to be either remarkably effective or dangerously ineffective. The digital marketing space is now looking toward these bio-statistical methods to bring the same level of agility to CRO.
The AGILE Statistical Approach: A New Standard
The proposed AGILE statistical method seeks to bridge the gap between scientific rigor and business necessity. This framework introduces several key innovations to the A/B testing workflow:
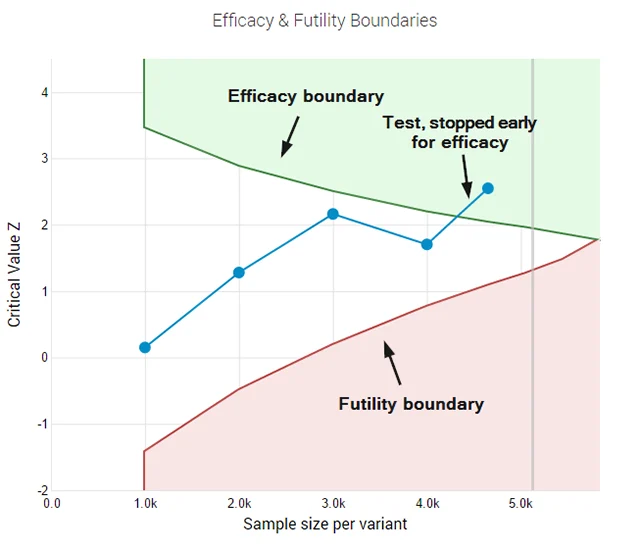
- Error-Spending Functions: This mathematical technique allows for interim analyses of data while keeping the overall false positive rate under control. It provides the flexibility to "peek" at data and make decisions without inflating the risk of error.
- Futility Stopping Rules: Unlike classical tests, the AGILE method allows practitioners to "fail fast." If a variant shows little to no promise of reaching the minimum effect size, the test can be stopped early for futility. This prevents the "sunk cost fallacy" where teams continue testing a losing variant simply because the trial hasn’t reached its arbitrary end date.
- Enhanced Efficiency: Simulations of the AGILE method show that it can lead to efficiency gains of 20% to 80% compared to fixed-sample testing. By allowing for early stopping in cases of high efficacy or high futility, the average time to reach a conclusion is significantly reduced.
Chronology of Statistical Evolution in Experimentation
The transition toward the AGILE method is the latest step in a century-long evolution of experimental design:
- 1908: William Sealy Gosset, writing under the pseudonym "Student," publishes the T-test, providing a foundation for small-sample statistics.
- 1930s-1950s: Sir Ronald A. Fisher and others formalize the frequentist approach to hypothesis testing, which becomes the standard for agricultural and physical sciences.
- 1969: Initial warnings are published in statistical journals regarding the dangers of "repeated significance testing" (peeking), though these warnings are largely ignored by the early digital marketing community.
- 1990s-2000s: Clinical trials adopt group sequential designs and error-spending functions to improve the ethics and efficiency of medical research.
- 2010-2015: The "CRO Boom" leads to a proliferation of easy-to-use A/B testing tools, which unfortunately democratize the misuse of classical statistics.
- Present Day: The introduction of AGILE and Bayesian frameworks marks a move toward "Sequential Analysis," aligning digital experimentation with modern scientific standards.
Broader Impact and Industry Implications
The shift toward more robust statistical methods like AGILE has profound implications for the digital economy. For large-scale enterprises like Amazon, Google, or Netflix, a 1% increase in conversion rate can translate into hundreds of millions of dollars in annual revenue. In such environments, the cost of a false positive—implementing a change that doesn’t actually work—is high, but the "opportunity cost" of a slow, inefficient testing cycle is even higher.
By adopting the AGILE method, organizations can increase the "velocity" of their experimentation programs. Faster tests mean more hypotheses can be tested per year. Furthermore, the inclusion of futility rules ensures that resources are quickly reallocated from losing ideas to high-potential ones.
From a structural perspective, this evolution requires a change in the relationship between marketing departments and data science teams. It necessitates a move away from "black box" testing tools toward platforms that offer transparency in their statistical methodology. As the industry matures, the ability to conduct rigorous, efficient, and scientifically sound experiments will become a primary competitive advantage, separating market leaders from those who are merely guessing in the dark. Adopting these advanced methods ensures that the "science" in data science is finally applied with the precision it deserves.