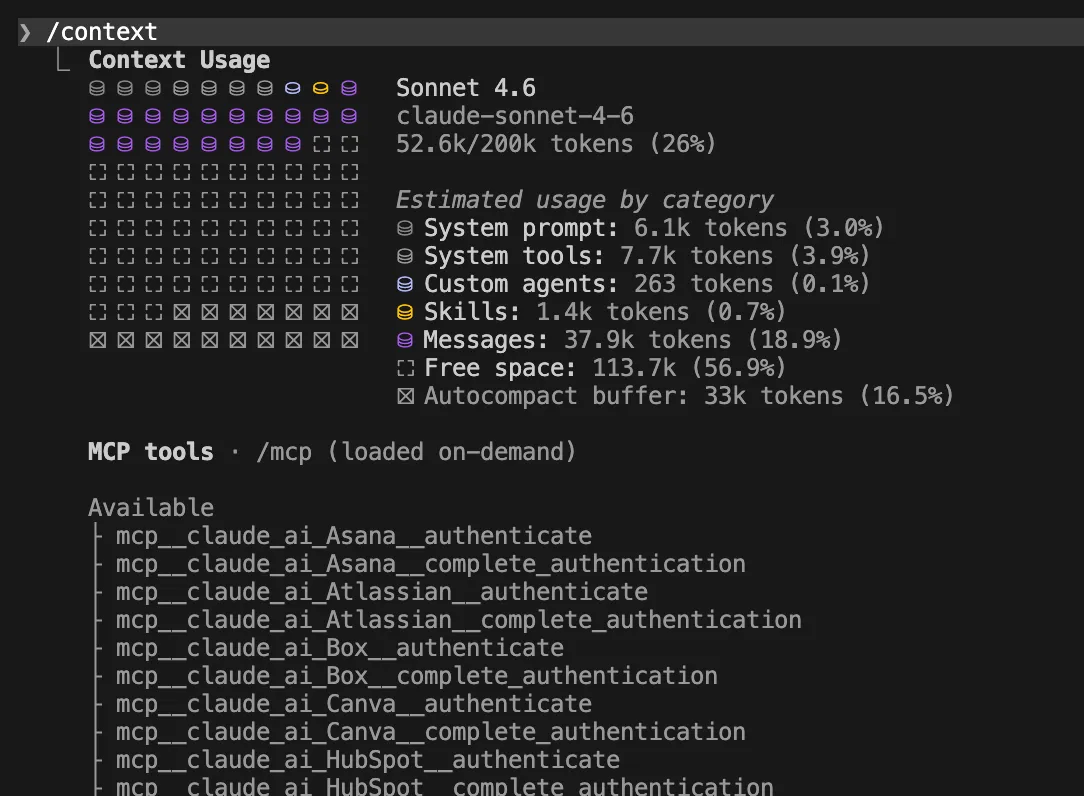
The rapid integration of agentic AI tools into software engineering workflows has introduced a new challenge for modern development teams: the exponential rise of API-related operational expenses. As Anthropic’s Claude Code and similar command-line interface (CLI) agents gain traction for their ability to perform complex refactoring and debugging, developers are encountering a phenomenon known as "token inflation." A 2025 Stanford University study has highlighted this growing concern, revealing that unchecked context expansion in large-scale projects can lead to thousands of wasted tokens daily. Without rigorous session management and configuration tuning, the financial overhead of using high-reasoning models can quickly outpace the productivity gains they provide.

The Economic Reality of Agentic Coding
Claude Code represents a shift from passive AI assistance to active agency. Unlike traditional chat interfaces, CLI agents have the authority to read directories, execute shell commands, and edit files autonomously. While this autonomy accelerates development, every action taken by the agent—every file read, every terminal output captured, and every line of code analyzed—is appended to the conversation context. Because Anthropic’s API pricing is determined by the volume of tokens processed in each request, a session that grows too large becomes increasingly expensive with every subsequent turn.
The Stanford research indicates that many developers fail to realize that the "history" of a session is re-processed with every new prompt. In a project with a deep directory structure, a single vague request like "fix the styling" can trigger a recursive file scan that consumes tens of thousands of tokens before a single line of code is changed. This has led to a call for "Context Engineering," a discipline focused on maintaining the smallest possible working set of data necessary for an AI to complete a task.

A Chronology of Context Management
The evolution of AI coding tools has moved through several distinct phases, each requiring more sophisticated cost-control measures. In 2023, the focus was on "Prompt Engineering," or the art of writing better instructions. By 2024, "RAG" (Retrieval-Augmented Generation) became the standard for providing models with relevant snippets of documentation. However, in 2025, the rise of "Agentic Loops" has necessitated a move toward "Context Governance."
This chronology reflects the transition from simple Q&A to long-running sessions where the AI acts as a virtual pair programmer. The longer a session lasts, the more "noise" accumulates. To address this, developers have adopted a series of high-impact tactics designed to prune irrelevant data and reset the token counter without losing the progress of the current sprint.

Tactical Session Management: The /clear and /compact Commands
The most immediate method for reducing token expenditure is the disciplined use of session-control commands. Industry best practices now suggest that developers should treat AI sessions as ephemeral rather than permanent logs.
1. The /clear and /resume Workflow
The /clear command is the most effective tool for immediate cost reduction. By ending a session and starting a fresh one, the developer wipes the accumulated context history. While this may seem counterintuitive when working on a complex bug, the /resume command allows a developer to pick up a previously named session if they realize they still need that history. This "stateless" approach ensures that debugging logs from two hours ago are not being billed for a task being performed now.
2. Context Compaction
When a task is too complex to be solved in a single fresh session, the /compact command serves as a middle ground. Compaction uses the model to summarize the current state of the work, retaining the goals, recent changes, and current errors while discarding the verbose step-by-step logs of how those states were reached. This effectively "zips" the context, allowing the developer to continue working within the same thread at a fraction of the token cost.
Technical Configuration and Environment Overrides
Beyond manual commands, the environment in which Claude Code operates can be tuned to prevent "token spikes." These spikes often occur when a terminal command produces an unexpectedly large output, such as a full stack trace or a verbose test suite result.

Capping Terminal and MCP Outputs
Standard configurations for Claude Code often allow for generous output lengths to ensure the model has enough information. However, for most debugging tasks, the first 100 lines of an error log are as useful as the first 10,000. By setting environment variables such as BASH_MAX_OUTPUT_LENGTH=20000 and MAX_MCP_OUTPUT_TOKENS=8000, developers can place a "hard ceiling" on how much data the agent can ingest from a single command.
Furthermore, filtering logs before they reach the agent is becoming a standard practice. Instead of running a raw test command, senior developers are now piping results through grep or head to ensure only the relevant failure messages are processed. This not only saves money but also prevents the model from becoming "confused" by irrelevant data—a phenomenon known as "lost in the middle."
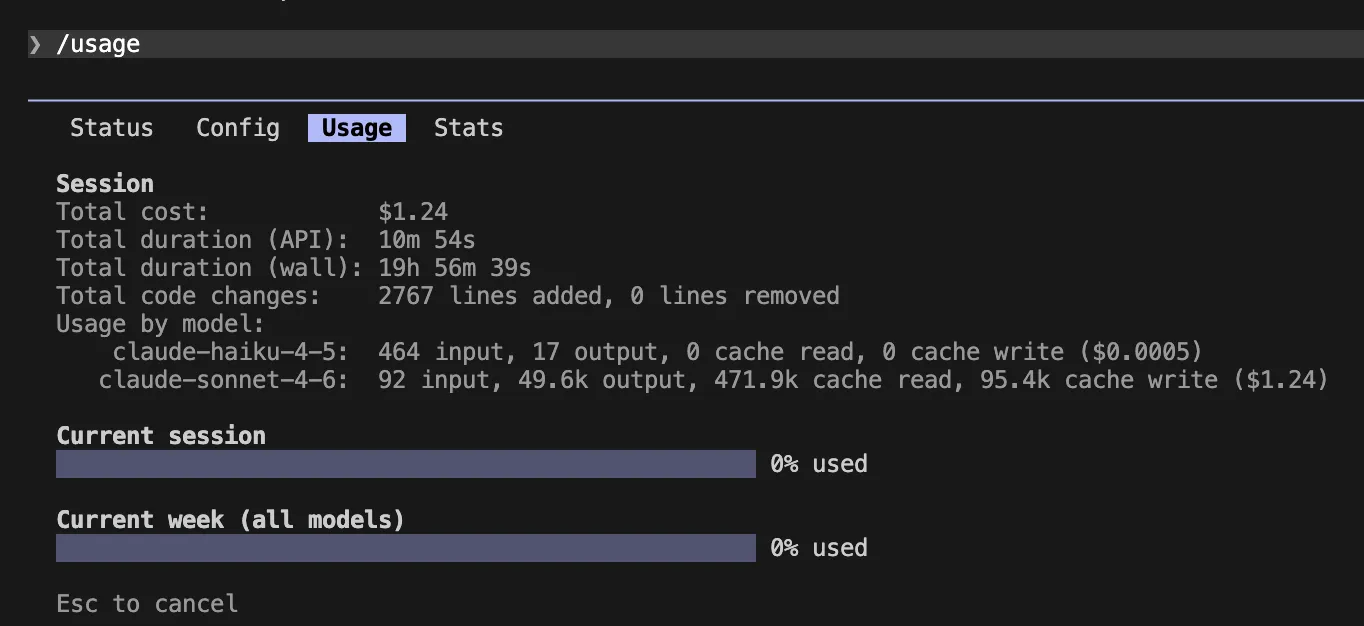
The Auto-Compact Threshold
Claude Code features an automatic compaction mechanism that triggers when the context window is near capacity (typically 95%). However, at 95% capacity, a single request can be prohibitively expensive. Experts recommend overriding this threshold to 70% or even 50% for noisy workflows using the CLAUDE_AUTOCOMPACT_PCT_OVERRIDE variable. This forces the model to summarize its history more frequently, keeping the "per-turn" cost low.
Instruction Architecture: From Global to Scoped Rules
One of the hidden contributors to token bloat is the system prompt and the global instruction file, usually named CLAUDE.md. If this file contains 500 lines of project history and coding standards, those 500 lines are charged for every single message sent to the AI.
Optimization of CLAUDE.md
The modern recommendation is to keep the global CLAUDE.md under 200 lines, focusing strictly on essential facts like the package manager, primary directories, and core test commands. For more specific needs, "Path-Scoped Rules" are used. By placing specific instructions in .claude/rules/ and defining paths (e.g., src/api/**/*.ts), the developer ensures that the AI only loads API-related instructions when it is actually editing API files. This modularity is a cornerstone of context-efficient development.
The Role of Specialized Subagents
For research-intensive tasks, such as reading through a new library’s documentation or analyzing a large log file, deploying a subagent is often more cost-effective than using the main session. Subagents operate in an isolated context window. They perform the "heavy lifting" of reading thousands of lines of data and return only a concise, four-line summary to the primary chat. This prevents the primary session from being "polluted" by the massive amounts of raw data the subagent had to process.
Model Selection and Thinking Mode Costs
The choice of the underlying LLM (Large Language Model) remains the most significant lever in cost management. While Claude 3.5 Sonnet is the balanced standard, Anthropic’s Claude 3 Haiku offers a significantly lower price point for routine tasks like file renaming, basic unit test generation, or documentation updates.
Managing Extended Thinking
The introduction of "Extended Thinking" (often associated with models like Claude 3.7) has provided a massive boost to reasoning capabilities. However, "thinking tokens" are billed as output tokens. For simple edits or repetitive tasks, this reasoning is unnecessary. Developers are now using the CLAUDE_CODE_DISABLE_THINKING=1 flag or setting the /effort level to "low" to bypass these expensive reasoning cycles when the solution is straightforward.
Community Response and Industry Implications
The developer community has responded to these cost challenges with a mix of ingenuity and caution. On platforms like GitHub and Reddit, "token-saving" configurations are frequently shared, and some open-source projects have even begun including a .claude/settings.json file in their repositories to help contributors stay within budget.
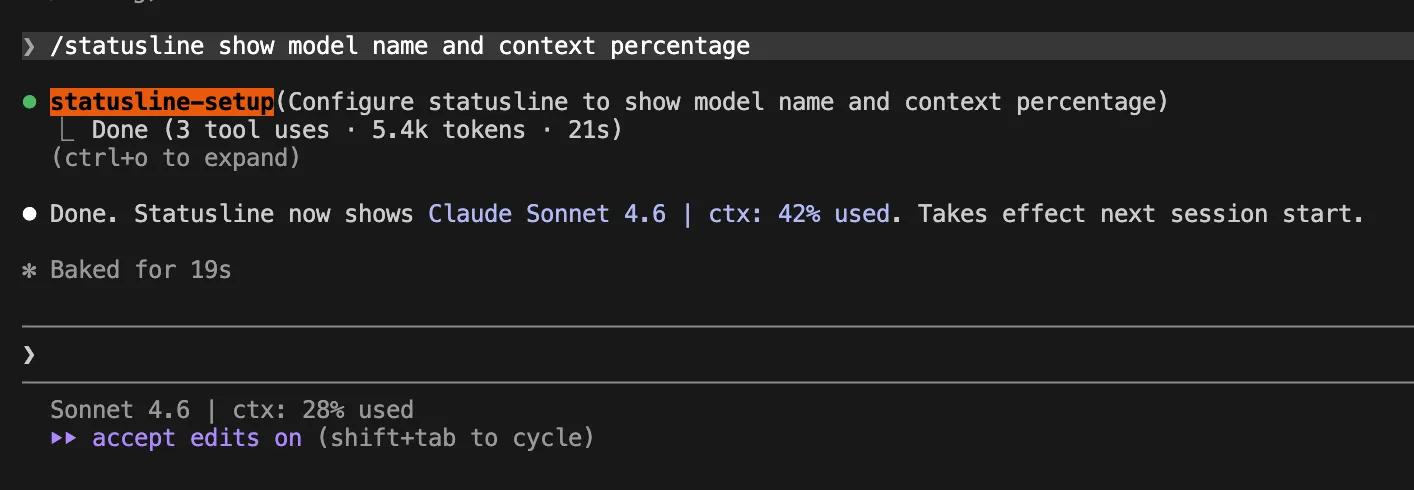
CTOs and engineering managers are also taking note. Many organizations have moved from providing unlimited API access to implementing "token budgets" per developer or per project. The consensus among technical leadership is that AI assistants are a force multiplier, but only if the cost of the "multiplier" doesn’t exceed the value of the time saved. There is a growing demand for better transparency in AI tools, leading to the adoption of "Live Status Lines" in the terminal that show the current context percentage and the estimated cost of the current session in real-time.
Conclusion: The Future of Efficient AI Coding
As we look toward the latter half of 2025, the focus of AI-assisted development is shifting from "what the AI can do" to "how efficiently the AI can do it." The strategies outlined—from rigorous session clearing and output capping to modular rule sets and subagent deployment—are no longer optional for professional teams. They are essential components of a modern development stack.
By mastering these context-management techniques, developers can enjoy the full benefits of agentic AI—faster ship times, fewer bugs, and reduced cognitive load—without falling victim to the "budget drain" of unoptimized token usage. The goal is a lean, focused, and highly capable AI assistant that understands the value of a project’s budget as well as it understands the logic of its code. In the era of agentic software engineering, efficiency is not just about the speed of the code, but the economy of the context.