The landscape of professional recruitment for product management, consulting, and artificial intelligence engineering has undergone a seismic shift as we move through 2026. The standard case study, once focused on market sizing or basic feature prioritization, has been replaced by a more complex challenge: the Generative AI (GenAI) case study. Candidates often find themselves facing a whiteboard with a prompt such as, “A major retailer wants to deploy a GenAI chatbot for customer support. How would you approach this?” Success in these high-stakes interviews now requires more than just technical jargon; it demands a structured, systems-thinking approach that accounts for the unique risks and probabilistic nature of large language models (LLMs).

The Evolution of the Technical Interview: Why GenAI Changes the Stakes
As of early 2026, industry data suggests that over 80% of Fortune 500 companies have integrated some form of GenAI into their customer-facing or internal workflows. However, a 2025 study by Gartner indicated that nearly 70% of GenAI pilots fail to reach full-scale production due to poor architectural planning and a lack of robust evaluation frameworks. Consequently, hiring managers have pivoted their interview strategies. They are no longer looking for candidates who can simply explain what a transformer model is; they are looking for "AI Architects" who can bridge the gap between business value and technical feasibility.
Traditional product case studies follow a predictable, linear path: identify the user, define the pain point, design a feature, and measure success. GenAI products break this mold because they are inherently non-deterministic. The same input can yield different outputs, and the "failure modes"—such as hallucinations or prompt injections—are far more damaging than a simple UI bug. To navigate this complexity, the GATHER framework has emerged as the gold standard for candidates aiming to demonstrate seniority and technical maturity.

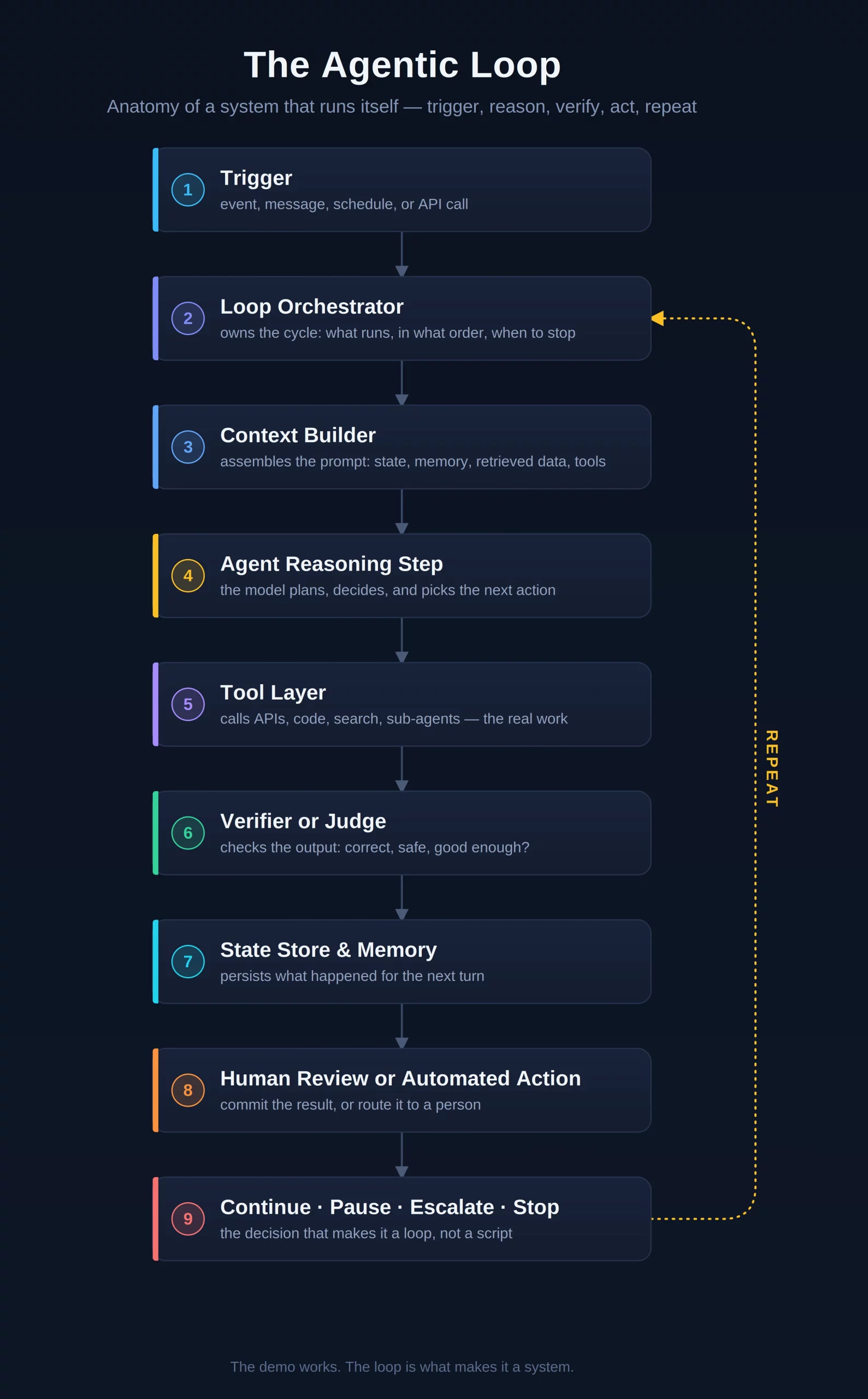
The GATHER Framework: A Six-Step Playbook for Success
The GATHER framework provides a comprehensive scaffolding for solving GenAI problems under pressure. It is designed to be adaptable for product managers, solutions architects, and machine learning engineers alike.
G: Ground the Problem
The most common mistake candidates make is jumping straight into technical solutions like Retrieval-Augmented Generation (RAG). Instead, the first three minutes must be dedicated to grounding the problem in business reality. This involves asking critical clarifying questions:

- Business Objectives: Is the goal to reduce operational costs, increase customer satisfaction (CSAT), or drive upsells?
- User Personas: Who is the primary user, and what is their "technical appetite"?
- Data Constraints: What internal data is available, and where is it stored?
- Success Definitions: What does "good" look like for the stakeholder?
A: Assess AI Appropriateness
Not every problem requires an LLM. In 2026, "AI fatigue" is a real concern for businesses looking to optimize margins. A sophisticated candidate will evaluate whether a simpler, deterministic solution—like a standard machine learning classifier or a rule-based system—might be more cost-effective. GenAI is best suited for tasks requiring unstructured natural language processing, multi-step reasoning, or creative generation. If the task is simple data extraction, standard ML is often the superior choice.
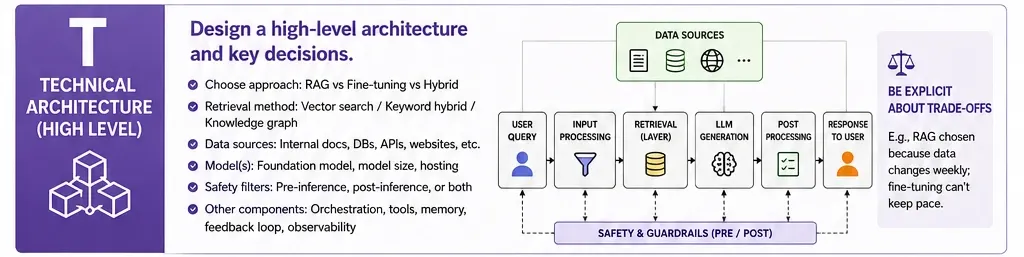
T: Technical Architecture (High Level)
Candidates are expected to sketch a high-level system design. This does not require code but does require an understanding of how components interact. Key decisions include:

- RAG vs. Fine-Tuning: Choosing RAG for dynamic data (like retail inventory) or fine-tuning for specific stylistic or domain-specific nuances.
- Retrieval Methods: Utilizing vector searches, knowledge graphs, or hybrid approaches.
- Safety Layers: Implementing pre-inference filters (to catch toxic prompts) and post-inference filters (to check for hallucinations).
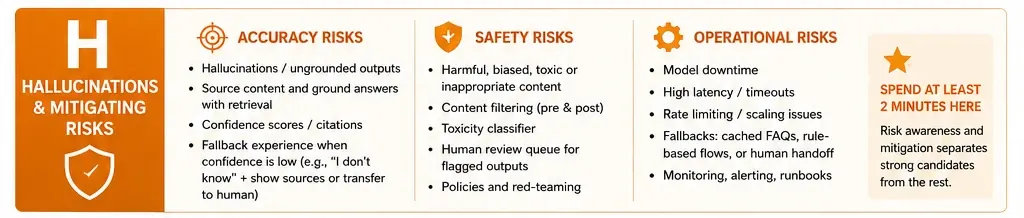
H: Hallucinations and Risk Mitigation
This section is often the "make or break" point of the interview. Risks must be categorized into three buckets:
- Accuracy Risks: Hallucinations or the "confidently wrong" phenomenon.
- Safety Risks: Bias, toxicity, and the leaking of PII (Personally Identifiable Information).
- Operational Risks: High latency or spiraling API costs.
E: Evaluation Metrics
Defining success in GenAI requires a tiered approach. Candidates should propose:

- Model Metrics: Faithfulness, relevancy, and context precision.
- Product Metrics: Task completion rate and escalation rate (how often the AI hands off to a human).
- Business Metrics: Cost per resolution and ROI.
R: Roadmap and Iteration
The final step is a phased rollout plan. This demonstrates an understanding of the "messiness" of real-world AI deployment.
- Phase 1 (Alpha): Internal "human-in-the-loop" testing.
- Phase 2 (Beta): A 10% "canary" rollout to external users with A/B testing.
- Phase 3 (GA): Full-scale deployment with automated monitoring and a weekly model review cadence.
Deep Dive: Applying GATHER to High-Stakes Healthcare
To understand the framework’s power, consider a scenario involving the summarization of patient records for a major hospital network, such as Apollo Hospitals. This use case involves 10,000 doctors across 73 locations, where physicians spend upwards of 2.5 hours daily reading patient charts.
Grounding the Problem: The context is life-or-death. A cardiologist needs different information than an ER doctor. The data is a messy mix of typed notes, scanned PDFs, and audio dictations.
Assessing AI Sufficiency: Traditional rule-based systems cannot handle the jargon and inconsistent structure of clinical notes. GenAI is necessary, but it must be used extractively (quoting the source) rather than abstractively (rephrasing), to ensure clinical accuracy.
Technical Architecture: An on-premises deployment is likely required to comply with health data regulations (like DISHA in India or HIPAA in the US). The system would query the Electronic Health Record (EHR) and use an LLM to populate a structured template rather than generating free-form text.
Risk Mitigation: The "quote and cite" method is essential here. If a model claims a patient is on a specific medication, it must provide a timestamped link to the original note.
Evaluation: Evaluation would involve "LLM-as-a-judge" for initial testing, followed by a rigorous clinical audit where doctors compare AI summaries against original charts.
Industry Implications and Market Sentiment
The shift toward these complex case studies reflects a broader trend in the tech industry. According to industry analysts, the "GenAI Gold Rush" of 2023-2024 has transitioned into the "GenAI Utility Era" of 2026. Companies are no longer impressed by prototypes; they are obsessed with reliability and safety.

"We’ve seen a 40% increase in candidates who can write code but a 60% decrease in candidates who can actually explain why their model made a specific mistake," says Marcus Thorne, a senior technical recruiter at a leading Silicon Valley firm. "The GATHER framework is essentially a maturity test. It tells us if a candidate can be trusted with a million-dollar compute budget and our brand reputation."
Chronology of AI Interview Trends
- 2022-2023: Focus on "Prompt Engineering" and basic awareness of LLM capabilities.
- 2024: Emphasis on RAG patterns and basic vector database knowledge.
- 2025: Introduction of "Agentic Workflows" and multi-modal challenges in interviews.
- 2026 (Present): Holistic systems design, rigorous safety protocols, and ROI-focused roadmapping (The GATHER Era).
Common Pitfalls to Avoid
Even with a framework, candidates often stumble. Data from mock interview platforms indicates five recurring errors:
- The "RAG Reflex": Suggesting RAG before understanding if the data is static or dynamic.
- Ignoring the "Human-in-the-Loop": Failing to explain how humans will monitor and correct the AI.
- Vague Metrics: Saying "it should be accurate" instead of defining "Context Relevancy" or "Groundedness."
- Underestimating Costs: Forgetting that high-token-count summaries can become prohibitively expensive at scale.
- Neglecting Latency: Proposing a complex multi-agent system for a customer service bot where a 30-second delay would ruin the user experience.
Conclusion: The Future of AI Product Leadership
As GenAI continues to permeate every sector from retail to healthcare, the ability to architect these systems responsibly will be the defining skill of the decade. The GATHER framework is more than an interview tool; it is a reflection of the professional standards required in the 2026 workforce. Candidates who master this approach demonstrate that they are not just consumers of AI technology, but architects of the intelligent future. By grounding problems in business value, rigorously assessing risks, and planning for iterative growth, professionals can transform a high-pressure interview into a masterclass in modern product leadership.