The landscape of artificial intelligence is currently defined by a paradoxical reality: while model architectures have become increasingly sophisticated and accessible, the rate of failure for machine learning (ML) projects remains strikingly high. Industry reports suggest that a significant majority of ML initiatives never reach production, not due to the inadequacy of the models themselves, but because of the logistical hurdles found in the "messy middle" of the development lifecycle. This middle ground—comprising data discovery, usability checks, script writing, error debugging, and model packaging—represents the primary bottleneck for modern engineers. In response to this challenge, a new open-source assistant known as ML Intern has emerged, designed to function not merely as an automated tuner, but as a comprehensive junior teammate capable of navigating the full ML engineering loop.
The Problem of the Messy Middle in ML Engineering
Traditional Machine Learning (AutoML) tools have long focused on the narrow task of model selection and hyperparameter optimization. However, seasoned practitioners argue that model choice is often the easiest part of the process. The true difficulty lies in the surrounding infrastructure: researching the correct approach, inspecting datasets for hidden biases, writing robust training scripts, and preparing models for deployment.
ML Intern distinguishes itself by operating within the Hugging Face ecosystem, leveraging the platform’s extensive libraries of datasets, models, and compute resources. Unlike AutoML, which functions as a "black box" for model building, ML Intern acts as an agentic assistant. It can read documentation, interpret research papers, inspect repositories, and execute jobs while maintaining a constant dialogue with the human supervisor. This shift from "automation" to "assistance" addresses the reality that ML development is rarely a linear path and frequently requires creative debugging and adaptive planning.
A Chronological Case Study: From Prompt to Production
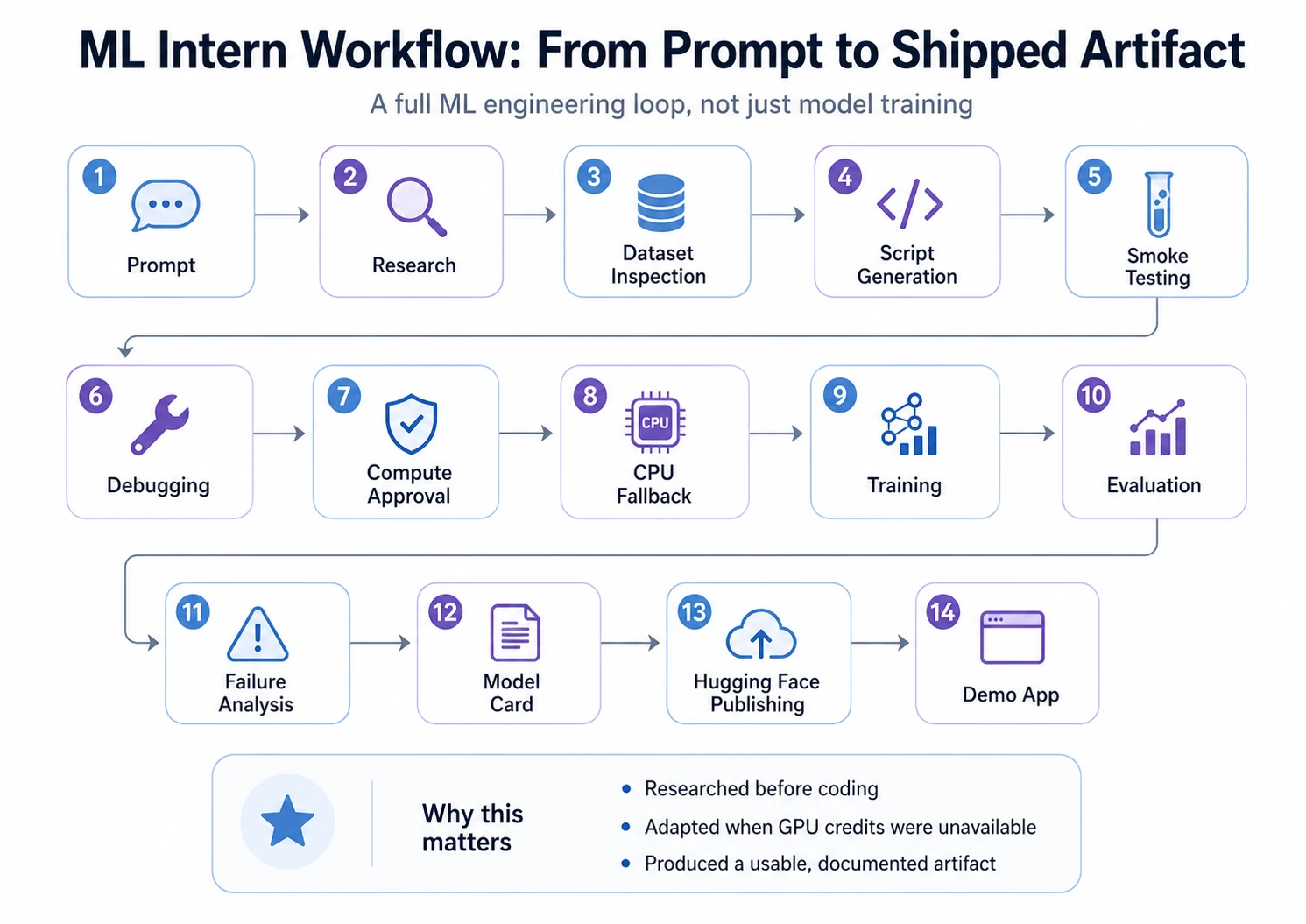
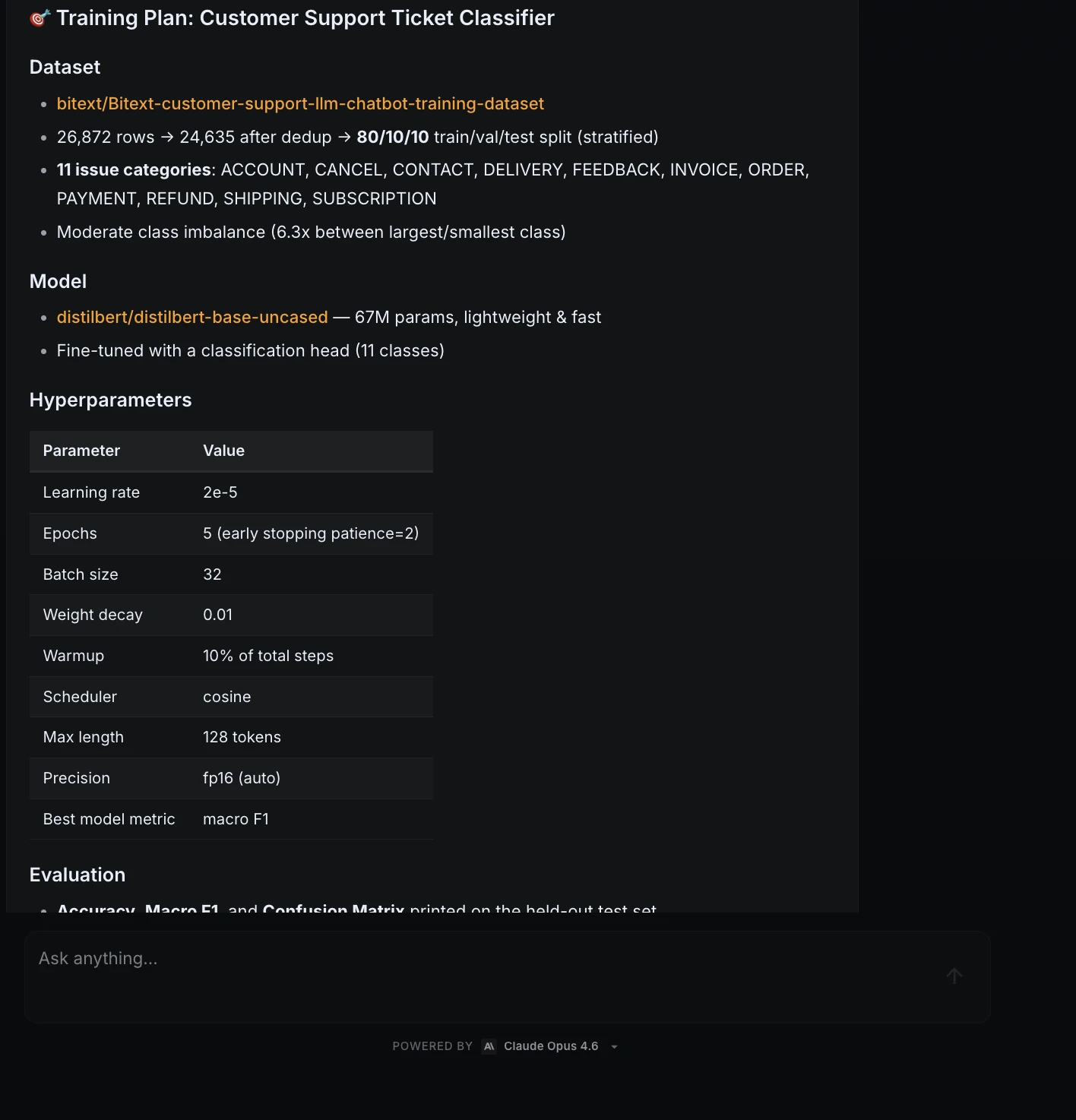
To evaluate the efficacy of ML Intern, a comprehensive project was conducted to transform a raw idea into a functional, published ML artifact. The objective was to build a text classification model capable of labeling customer support tickets by issue type—a standard yet critical task for enterprise automation.
Phase 1: Initiation and Research
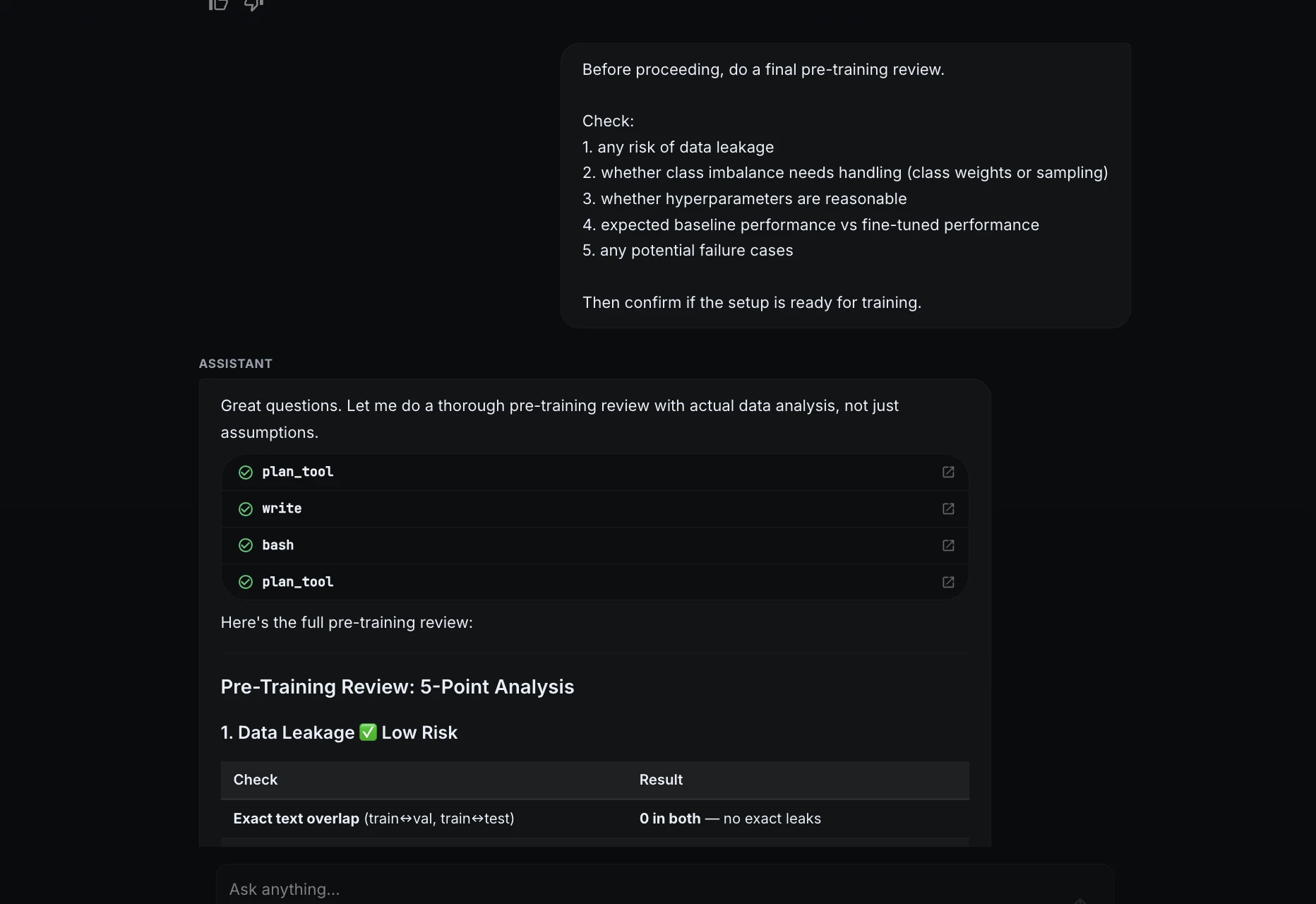
The project began with a high-level natural language prompt defining the goal, the preferred model type (lightweight transformers), and the evaluation metrics (accuracy, macro F1, and a confusion matrix). Crucially, the prompt established a safety guardrail: no expensive compute jobs were to be launched without explicit human approval.
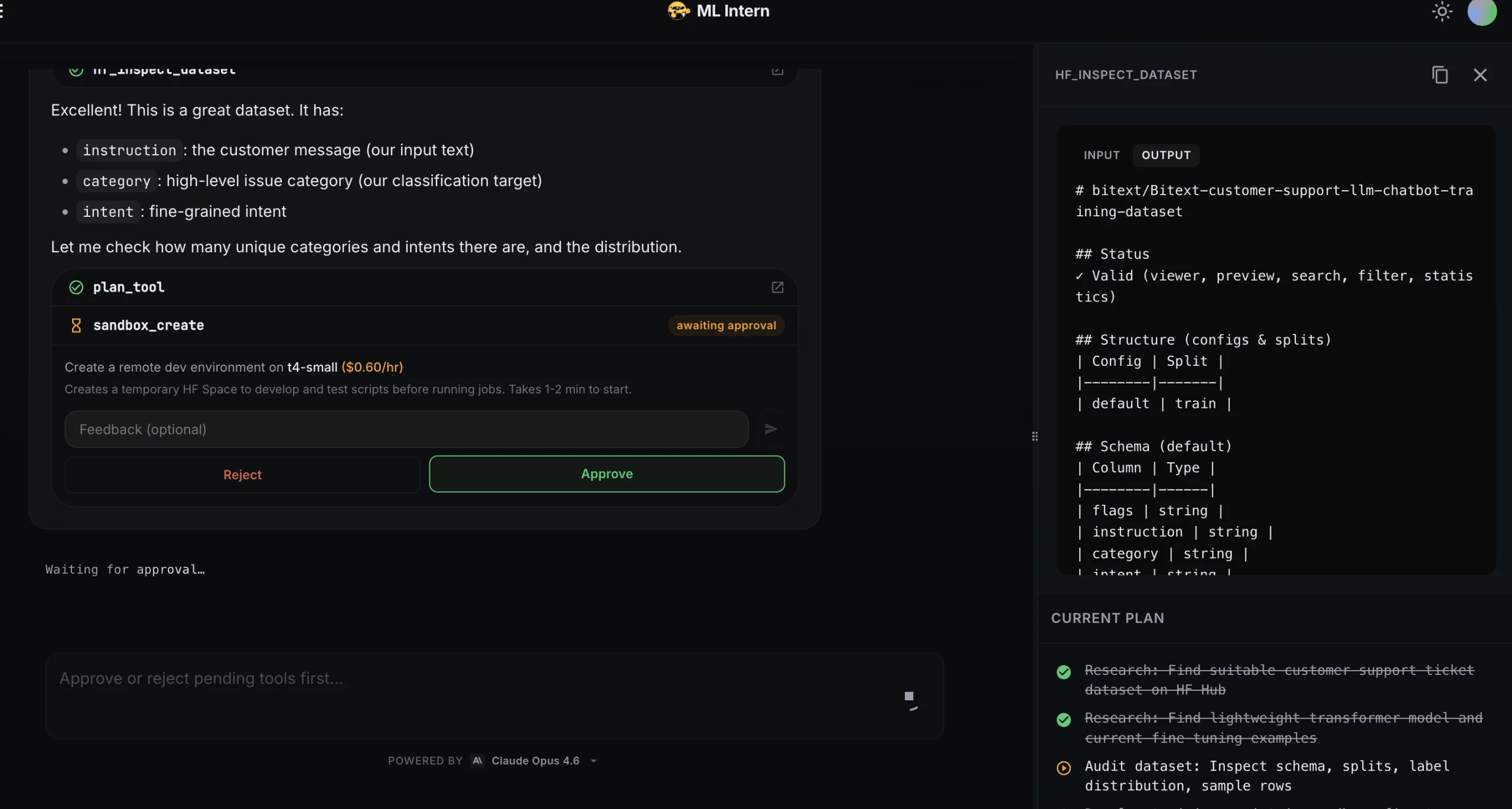
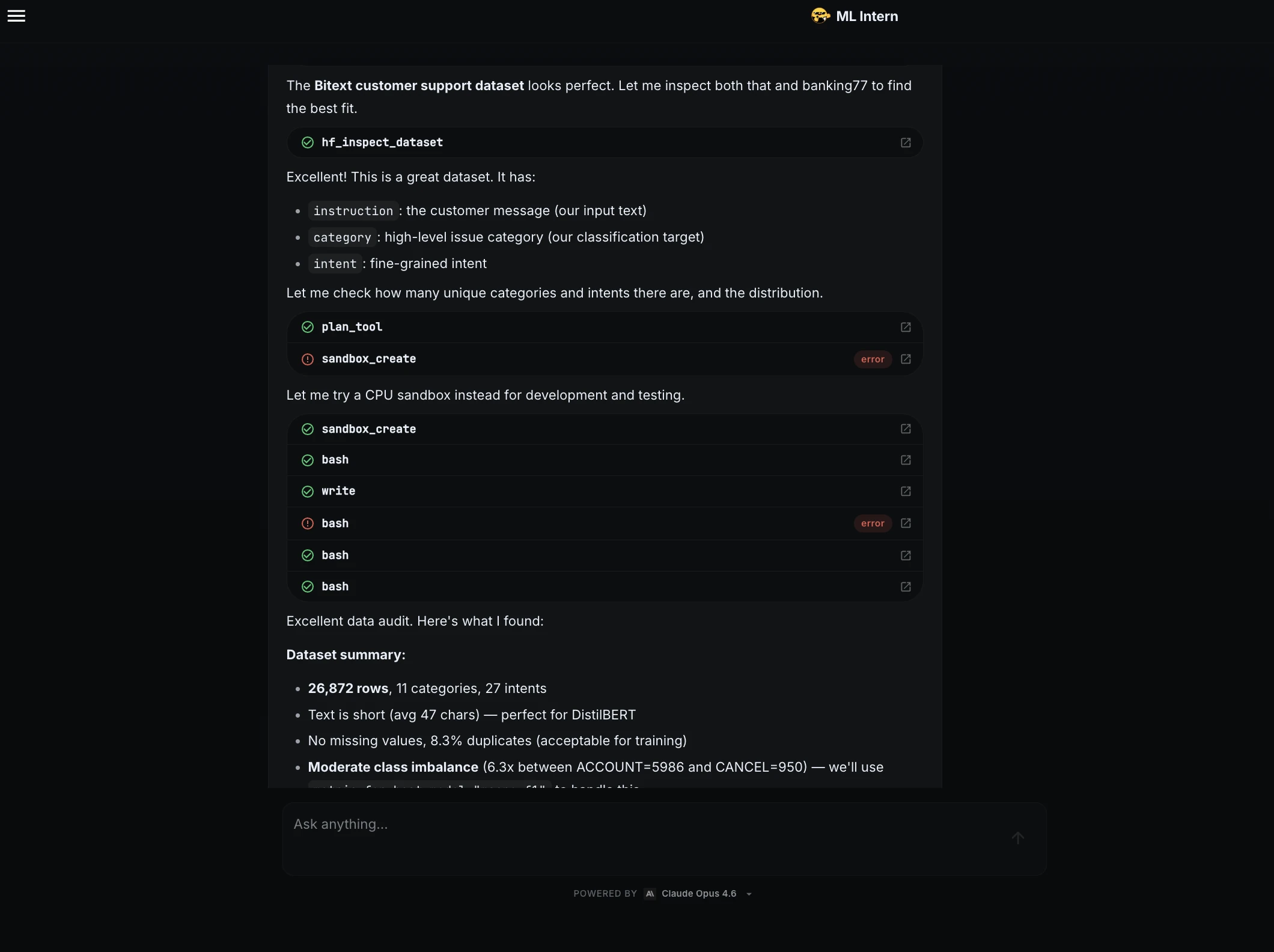
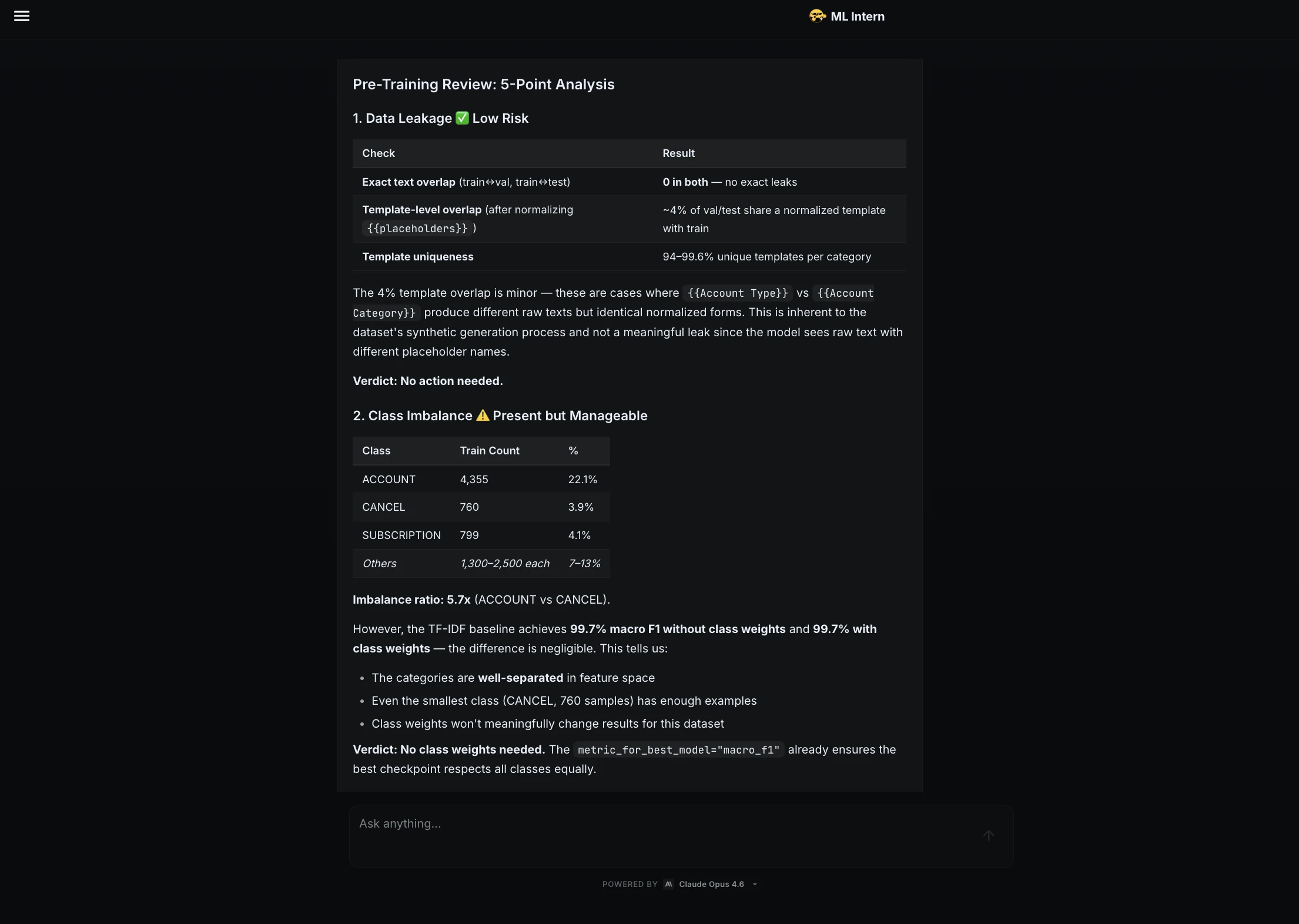
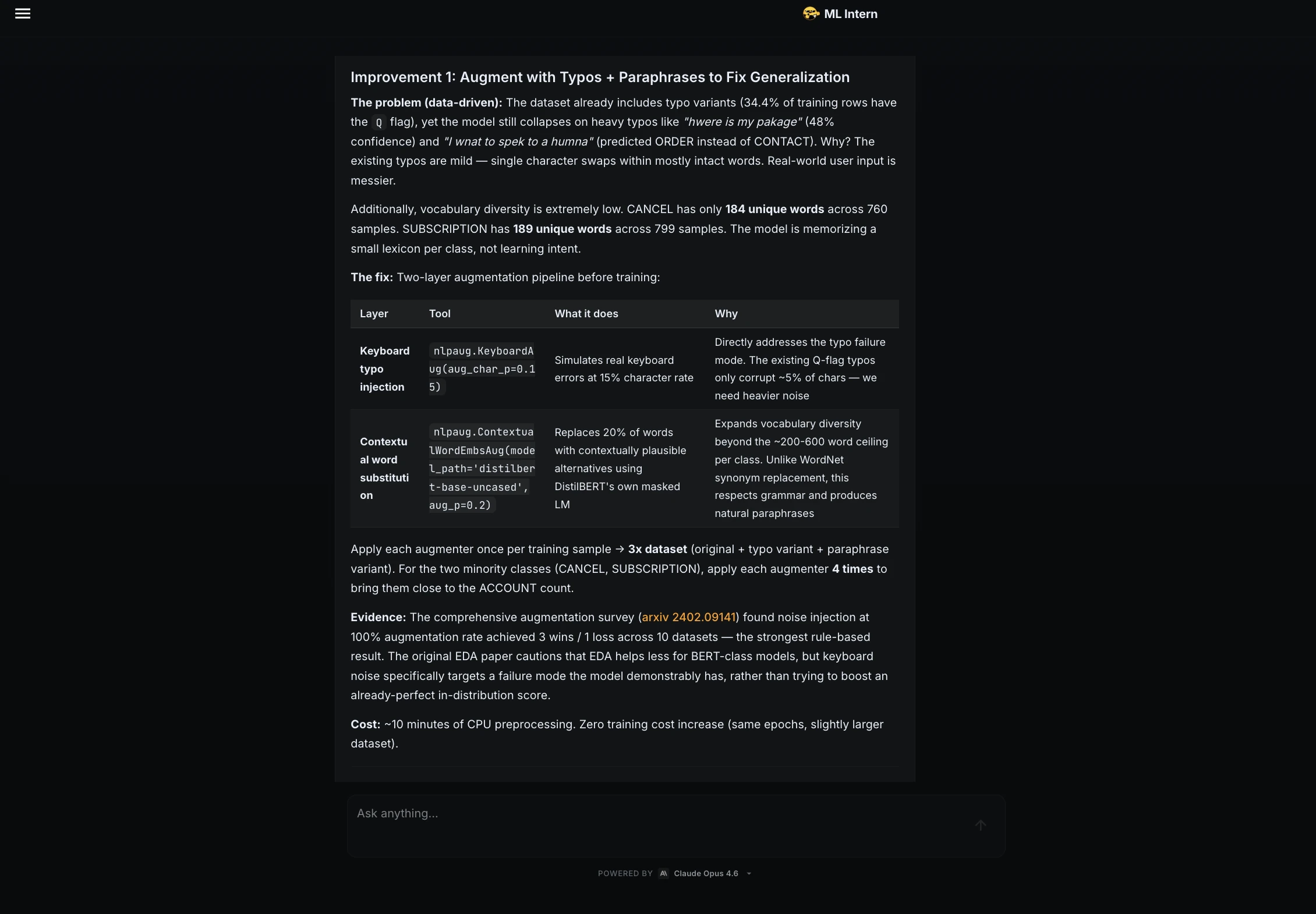
ML Intern initiated the workflow by researching the Hugging Face Hub for suitable data. It identified and selected the Bitext customer support dataset, a robust collection of over 26,000 rows across 11 distinct categories. Rather than simply moving to training, the assistant performed a detailed data inspection, identifying an average text length of 47 characters and noting a moderate class imbalance—a critical factor that often leads to biased models if left unaddressed.
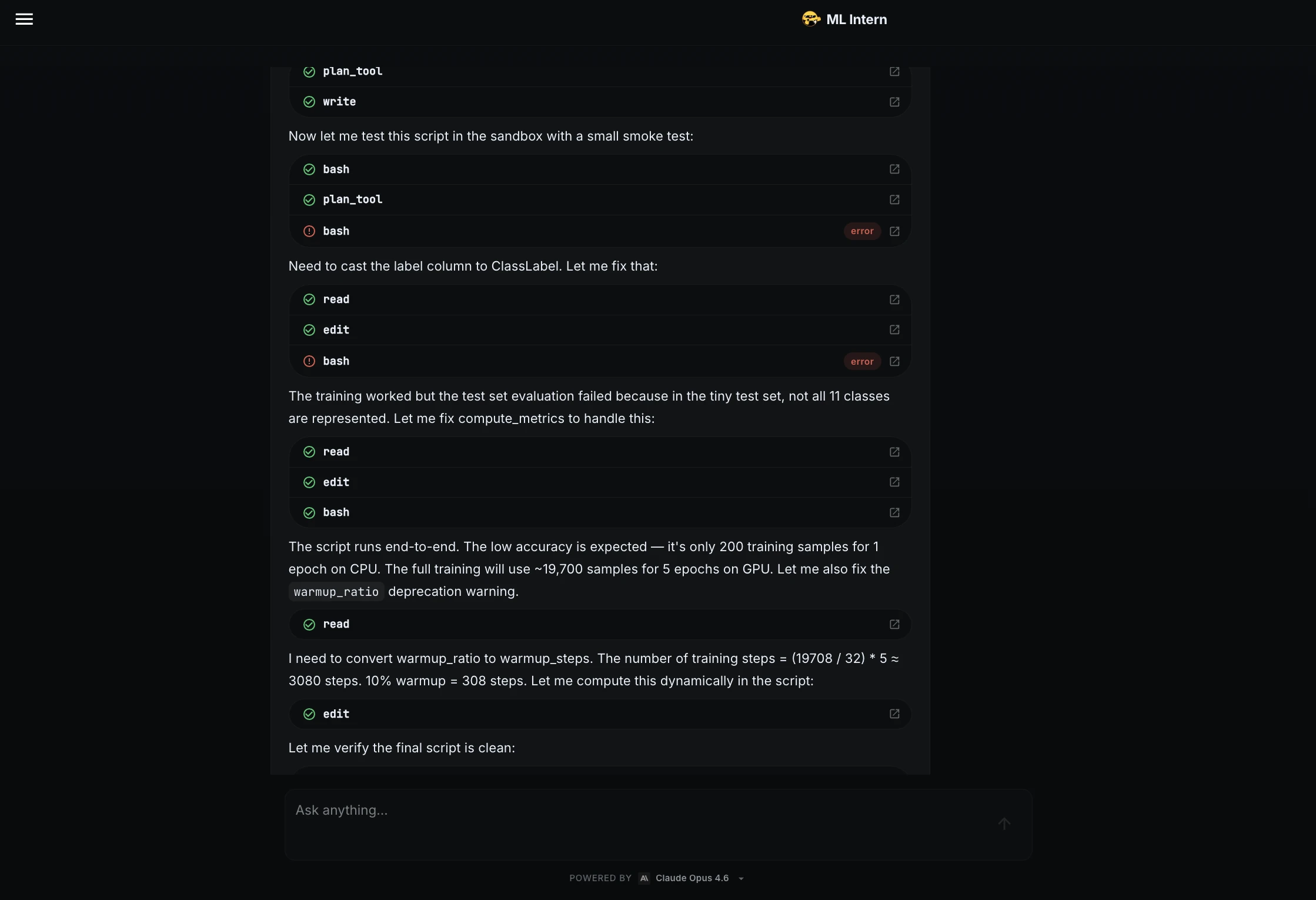
Phase 2: Smoke Testing and Iterative Debugging
One of the most common causes of ML project delays is the discovery of script errors hours into a training run. ML Intern mitigated this risk by implementing a "smoke test"—running the training script on a tiny data sample.
The test immediately revealed two significant issues: a column type mismatch requiring conversion to ClassLabel and a metric function failure when the sample size was too small to represent all 11 classes. In a traditional workflow, these errors might have frustrated a human engineer or crashed a long-running job. ML Intern identified the root causes, rewrote the code, and verified the fix before proceeding.
Phase 3: Adaptive Resource Management
The project encountered a real-world hurdle during the transition to training. The assistant initially attempted to launch the job on Hugging Face GPU hardware, but the request was denied due to a lack of available credits in the namespace.
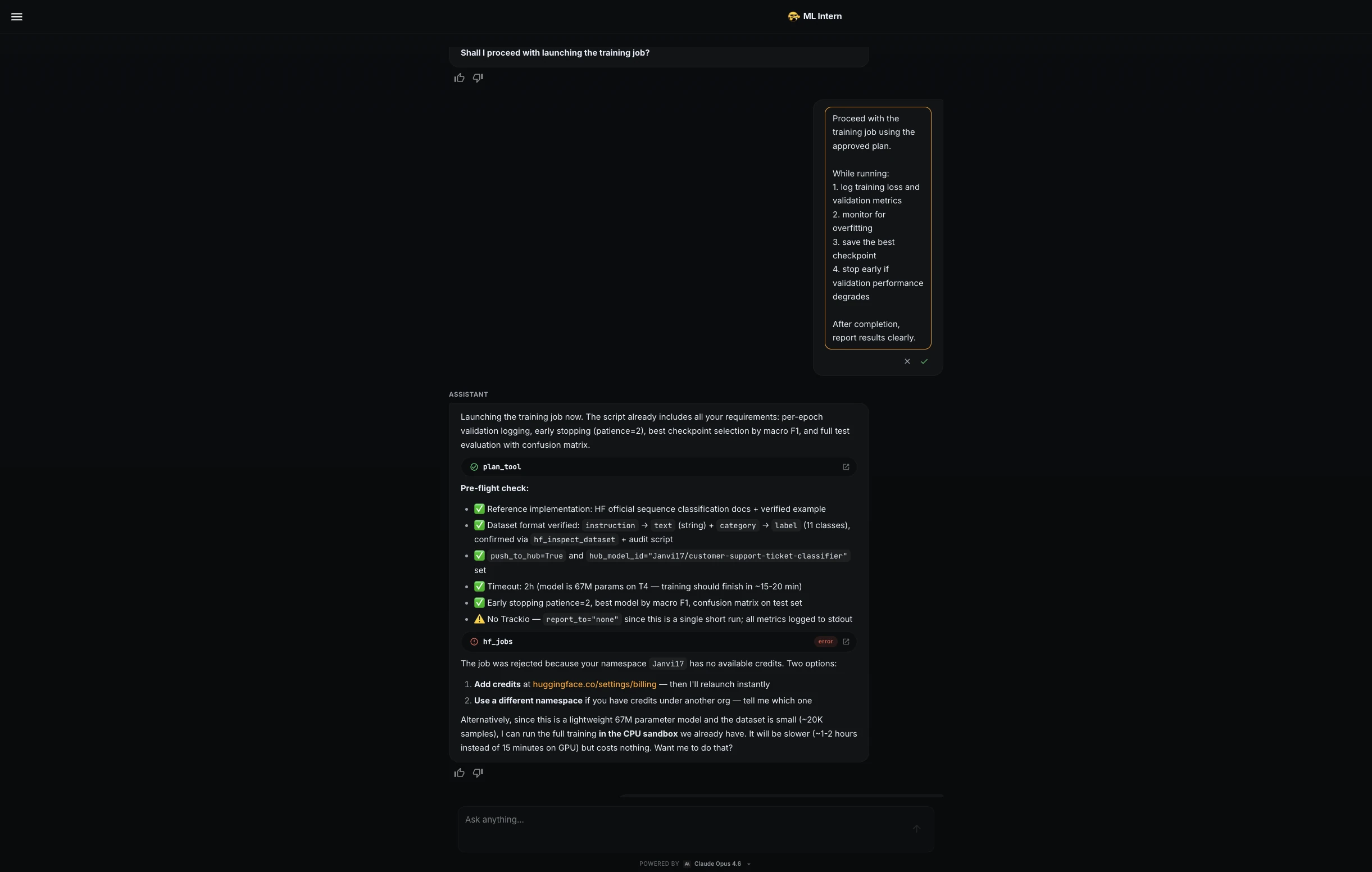
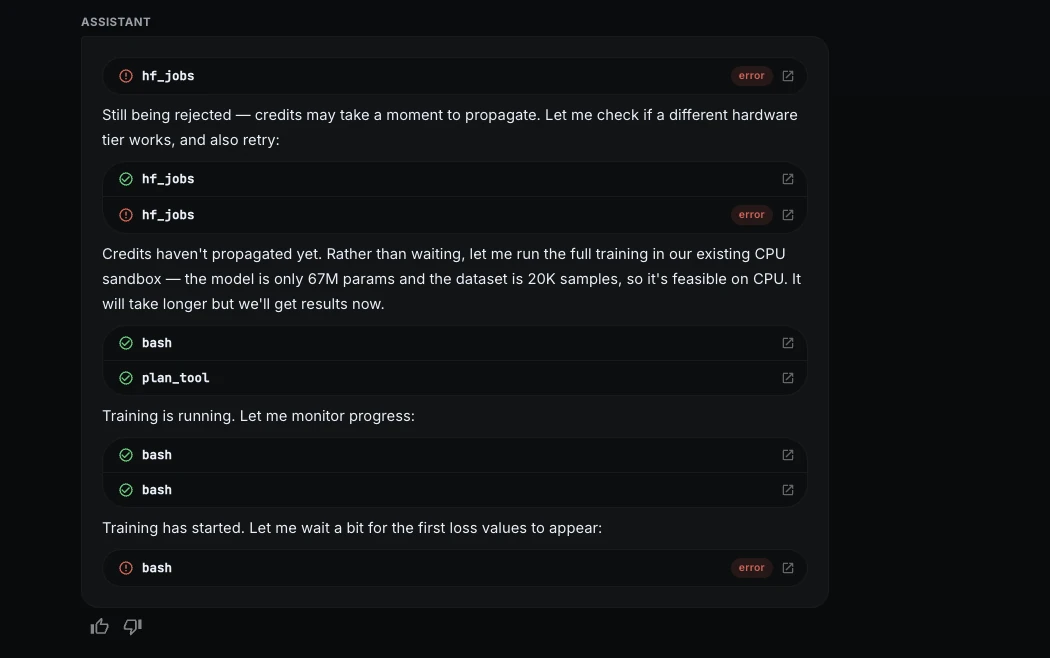
Demonstrating a level of adaptability rarely seen in standard AutoML tools, ML Intern pivoted to a free CPU sandbox. While this increased the training time to approximately 60 minutes, it allowed the project to continue without financial overhead. The assistant optimized the run for CPU architecture, demonstrating a sophisticated understanding of hardware constraints.
Data and Performance Analysis
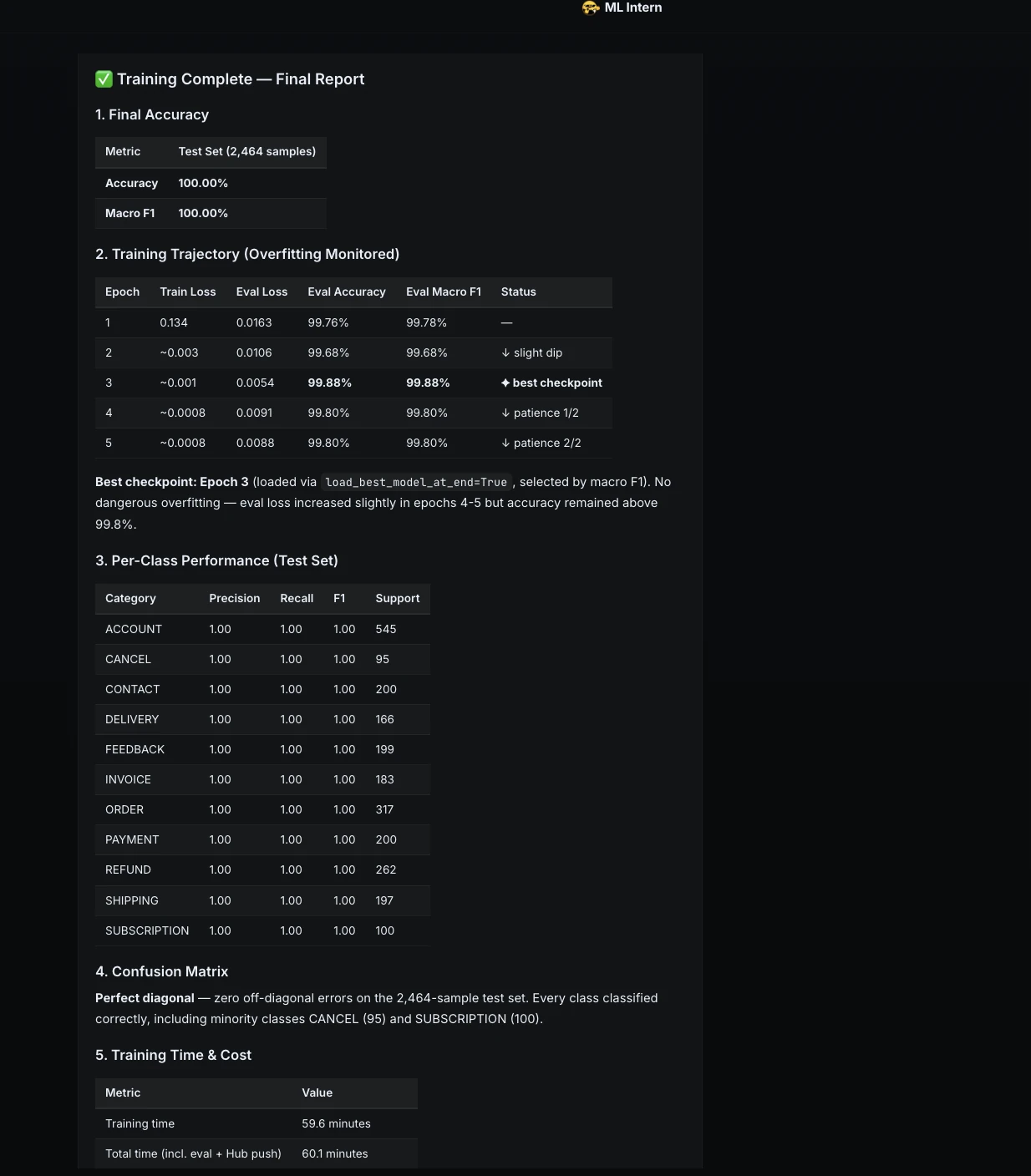
The training phase was monitored closely, with ML Intern providing real-epoch updates on loss and validation metrics. The results indicated a highly efficient learning curve for the DistilBERT-base-uncased model.
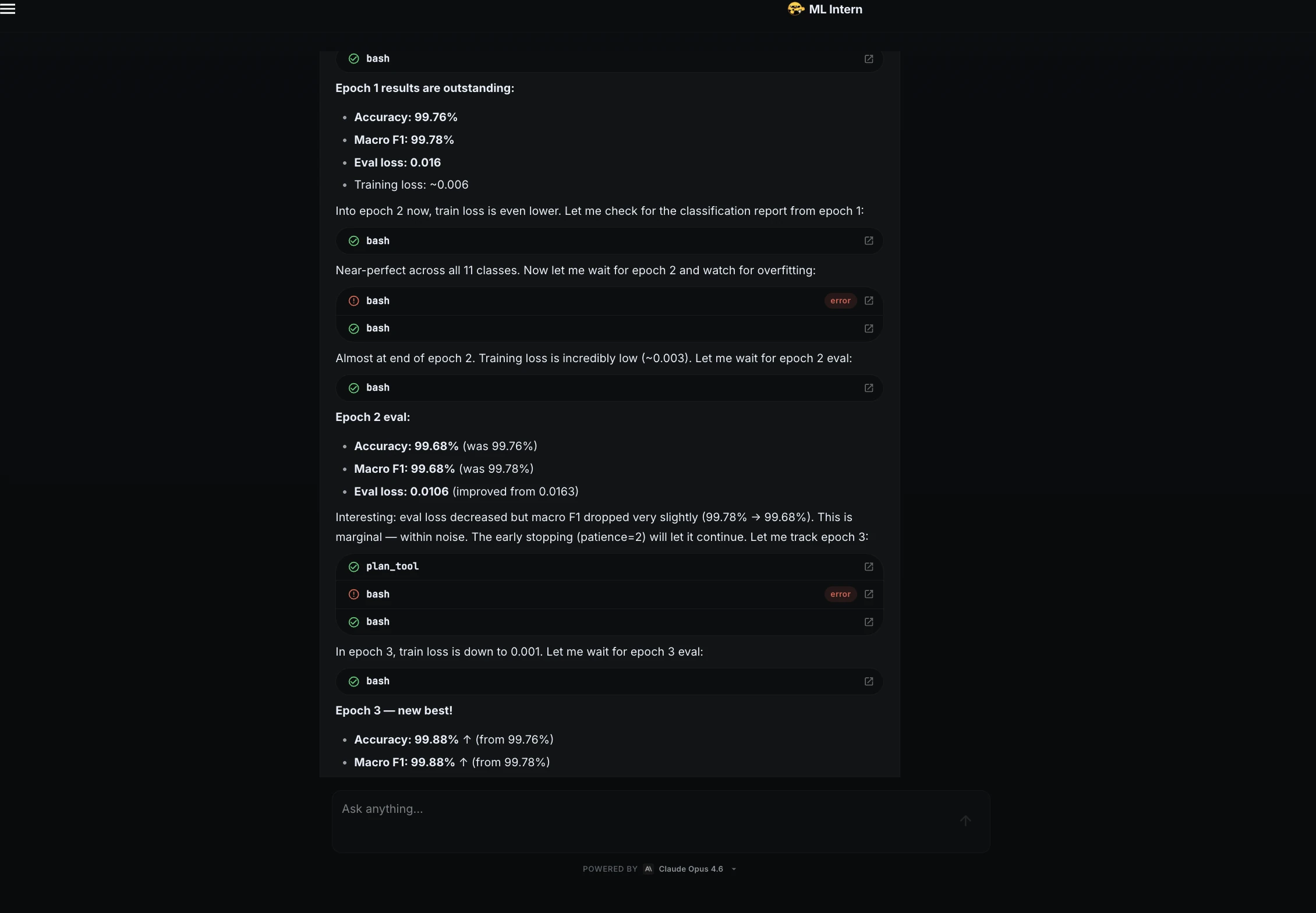
| Epoch | Accuracy | Macro F1 | Status |
|---|---|---|---|
| 1 | 99.76% | 99.78% | Strong initial learning |
| 2 | 99.68% | 99.68% | Minor fluctuation |
| 3 | 99.88% | 99.88% | Optimal checkpoint |
| 4 | 99.80% | 99.80% | Slight overfitting detected |
| 5 | 99.80% | 99.80% | Finalized with Epoch 3 weights |
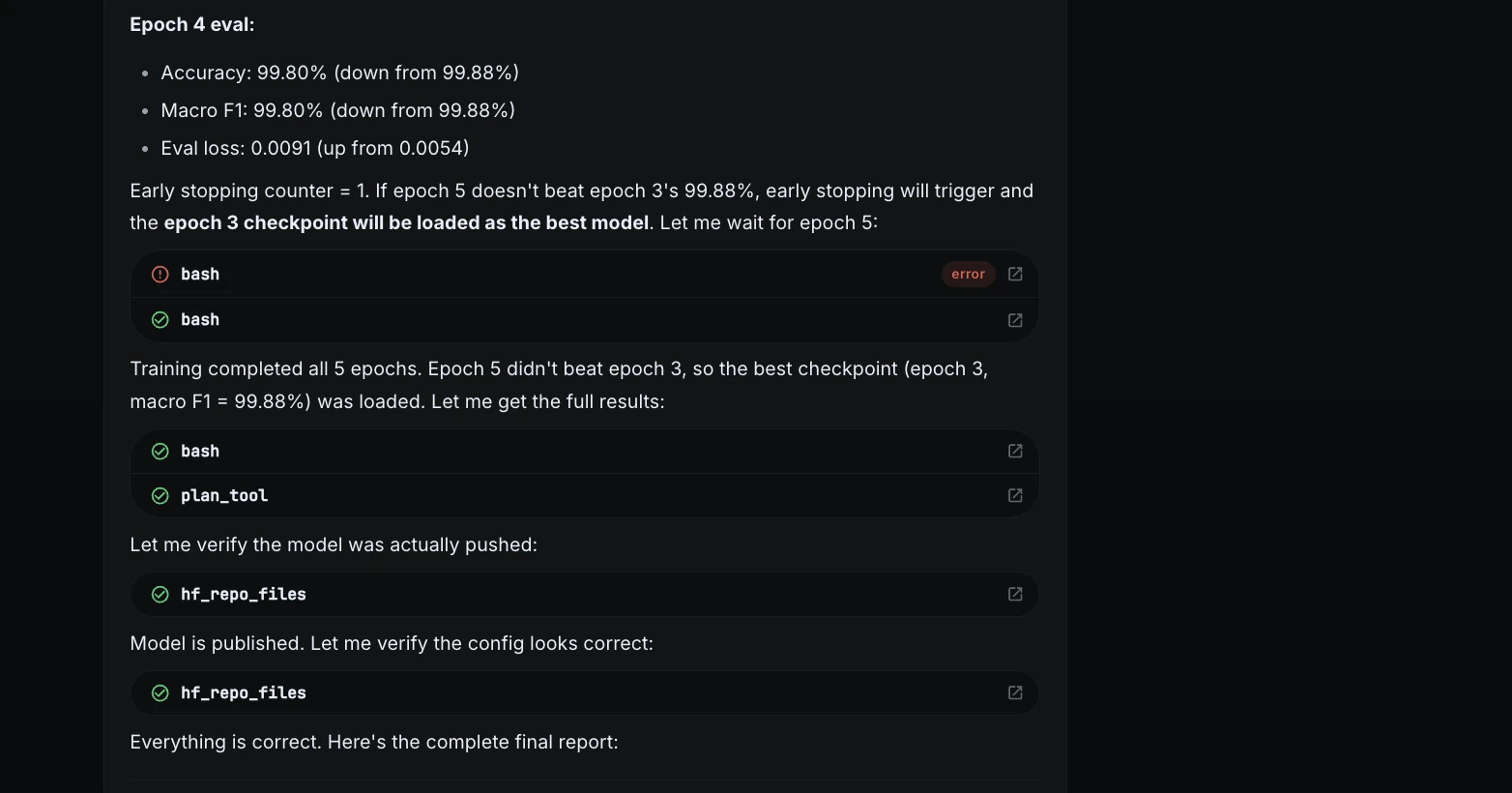
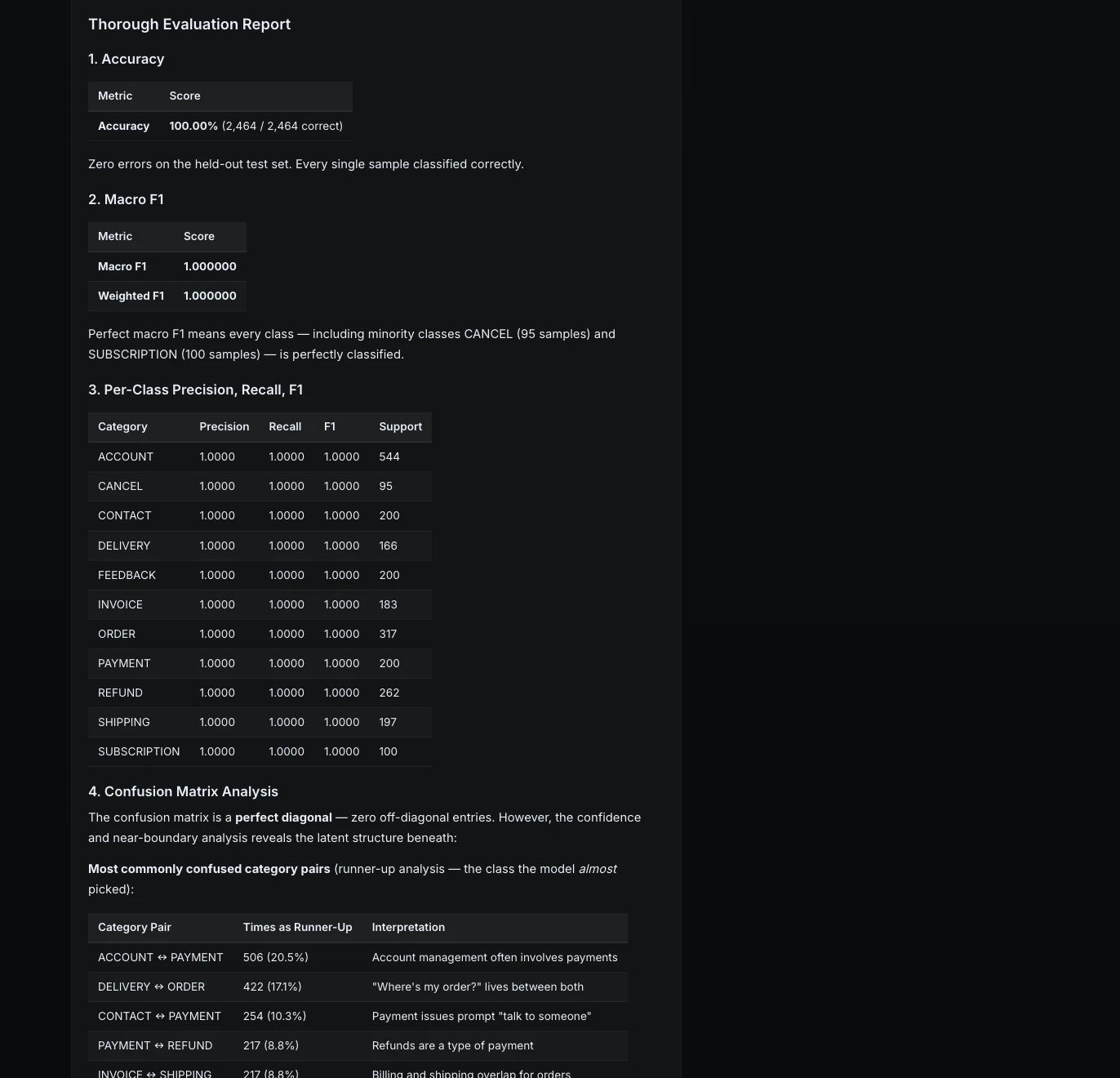
Upon completion, the model achieved a 100% accuracy rate on the held-out test set. While such a result is often a cause for celebration, ML Intern’s evaluation protocol was designed to be more rigorous.
Beyond Metrics: Failure Analysis and Stress Testing
A significant contribution of the ML Intern framework is its insistence on "honest evaluation." Recognizing that perfect test scores can be misleading—often masking a lack of robustness to real-world noise—the assistant was tasked with performing a failure analysis using synthetic "hard" examples.
The assistant identified several high-risk areas where the model, despite its perfect scores, might fail in production:
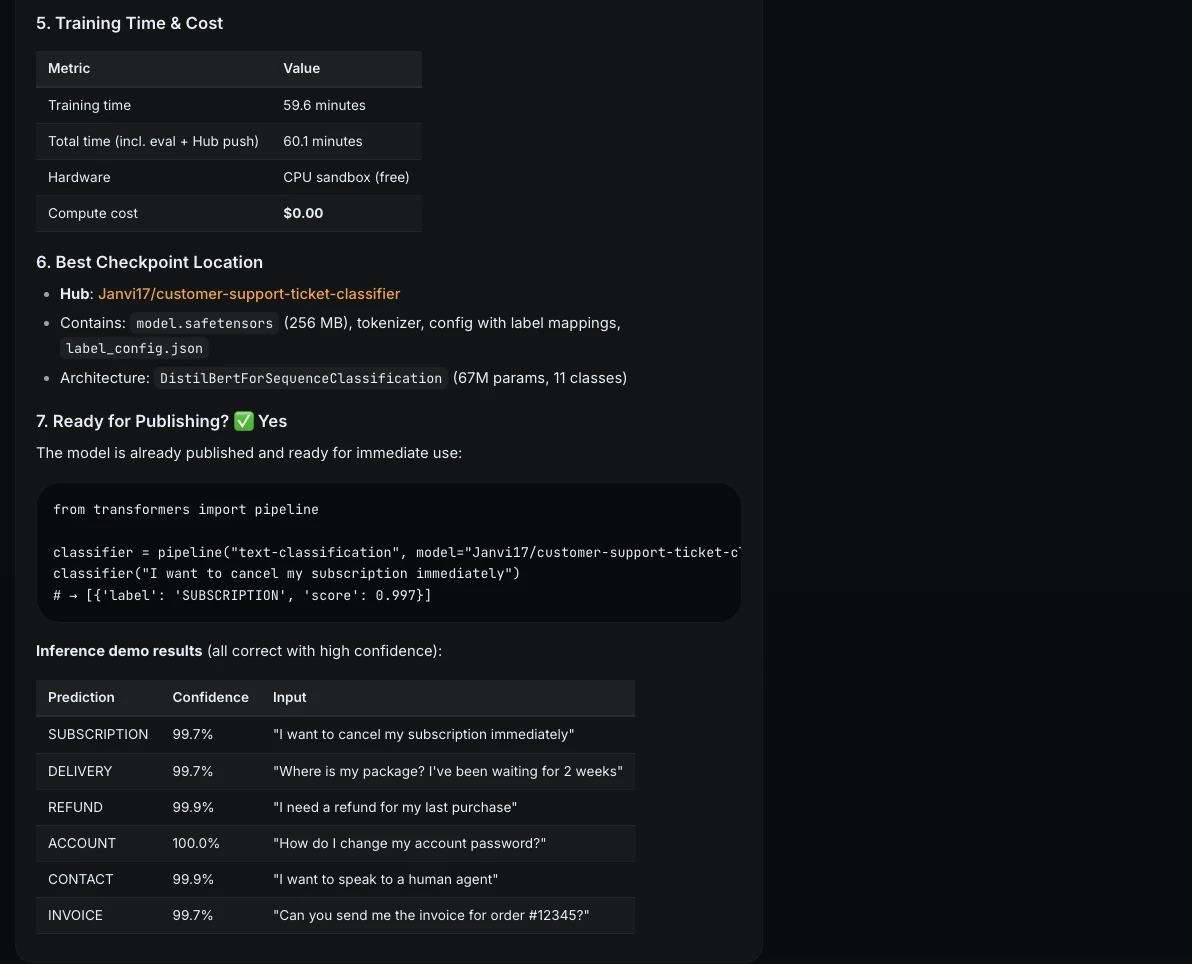
- Negation: Phrases like "Don’t refund me, just fix the product" were prone to being mislabeled as "Refund" because the model over-indexed on specific keywords.
- Ambiguity: Inputs mentioning both shipping and billing created label confusion.
- The "Unknown" Problem: Since the model was trained on 11 classes, it lacked a mechanism to handle "gibberish" or unrelated inputs, forcing it to pick the most likely (but incorrect) category.
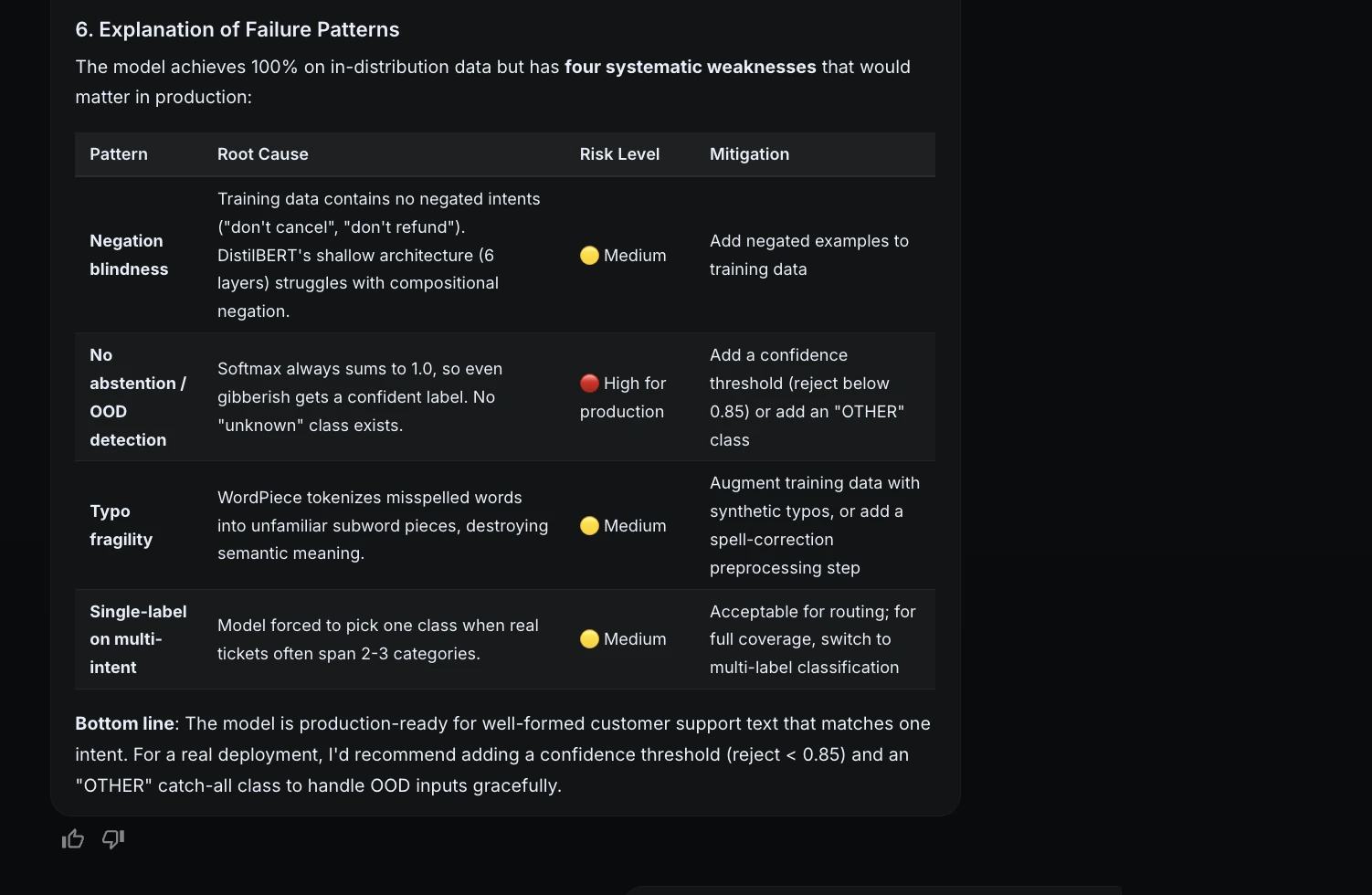
To address these, ML Intern suggested future improvements such as typo augmentation, the introduction of an "UNKNOWN" class, and label smoothing to reduce overconfidence. This level of critical analysis moves the tool from a simple code generator to a strategic engineering partner.
Deployment and Documentation
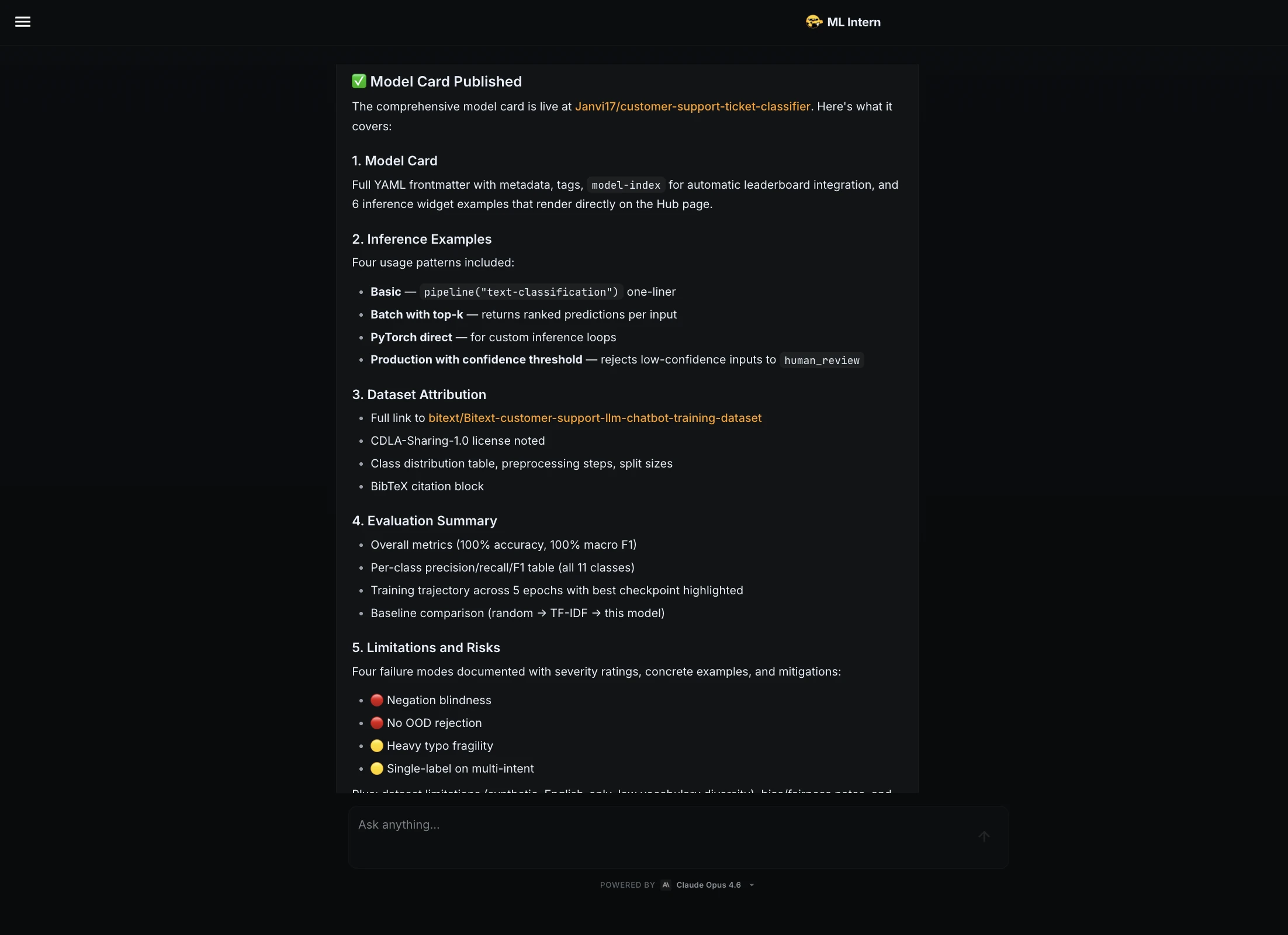
The final phase of the project involved packaging the model for public consumption. Documentation is frequently the most neglected aspect of ML engineering, yet it is vital for reproducibility and safety. ML Intern automatically generated a comprehensive Model Card for the Hugging Face Hub, which included:
- Dataset attribution and licensing.
- Detailed per-class precision and recall metrics.
- Training hyperparameters and hardware logs.
- A clear statement of limitations and risks.
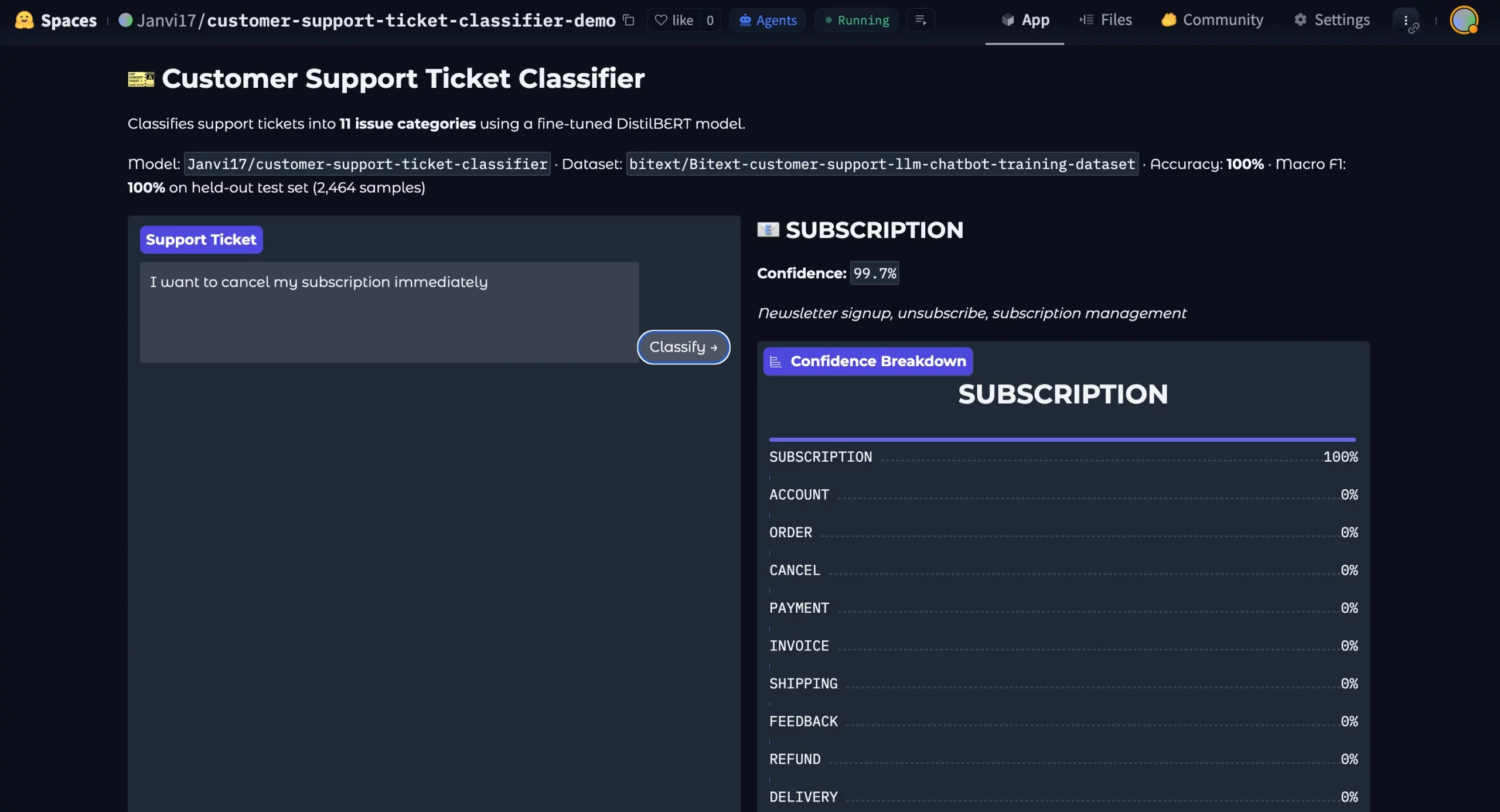
Furthermore, the assistant developed a functional Gradio demo and deployed it as a Hugging Face Space. This allowed stakeholders to interact with the model in real-time, providing a tangible interface for a previously abstract classification script.
Comparative Analysis: ML Intern vs. Traditional AutoML
To understand the value proposition of ML Intern, it is necessary to compare it against existing AutoML solutions.
| Feature | Traditional AutoML | ML Intern |
|---|---|---|
| Starting Point | Cleaned, formatted dataset | Natural language objective |
| Workflow Scope | Model selection and tuning | End-to-end (Research to Deployment) |
| Data Interaction | Fixed schema | Active inspection and discovery |
| Error Handling | Logs errors for human fix | Self-debugs and suggests fixes |
| Final Output | Model weights/Pickle file | Weights, Model Card, Demo, and Logs |
Analysts suggest that while AutoML remains superior for structured, tabular data where the goal is purely predictive performance, ML Intern represents the future of unstructured data tasks (NLP, Computer Vision) where the "engineering" of the solution is as important as the model itself.

Broader Implications for the AI Workforce
The emergence of tools like ML Intern raises questions about the evolving role of the machine learning engineer. Rather than replacing the engineer, these assistants appear to be shifting the focus of the role. By automating the repetitive "messy middle," engineers are freed to focus on high-level architecture, ethical considerations, and business alignment.
However, the "junior teammate" analogy remains apt. The risks associated with AI-assisted development include the potential for the tool to choose unsuitable data or suggest weak fixes that a human might overlook. The consensus among early adopters is that the safest and most productive approach is a "human-in-the-loop" model. In this project, humans maintained control over critical checkpoints—approving compute costs, reviewing failure patterns, and validating the final model card.
Conclusion
ML Intern demonstrates that the next frontier of AI productivity is not necessarily in larger models, but in more intelligent workflows. By supporting the wider ML engineering lifecycle—from initial research and dataset inspection to debugging, evaluation, and publishing—it provides a template for how complex technical tasks can be managed in the age of generative AI. For organizations looking to bridge the gap between a conceptual AI idea and a working production artifact, tools that address the "messy middle" are no longer just a luxury; they are a strategic necessity. As the ecosystem continues to mature, the value of an ML project will be measured not just by the accuracy of its predictions, but by the robustness, transparency, and speed of the engineering process that created it.