The digital economy has reached a point where data-driven decision-making is no longer a competitive advantage but a prerequisite for survival. As organizations strive to optimize user experiences and maximize conversion rates, the adoption of A/B testing has moved from the periphery of marketing departments to the core of product development and business strategy. However, the transition from a localized, low-volume testing initiative to an enterprise-wide experimentation engine is fraught with systemic challenges. While the initial stages of a testing program are often characterized by rapid wins and high enthusiasm, the process of scaling introduces a level of complexity that can compromise data integrity, organizational trust, and ultimately, the return on investment.
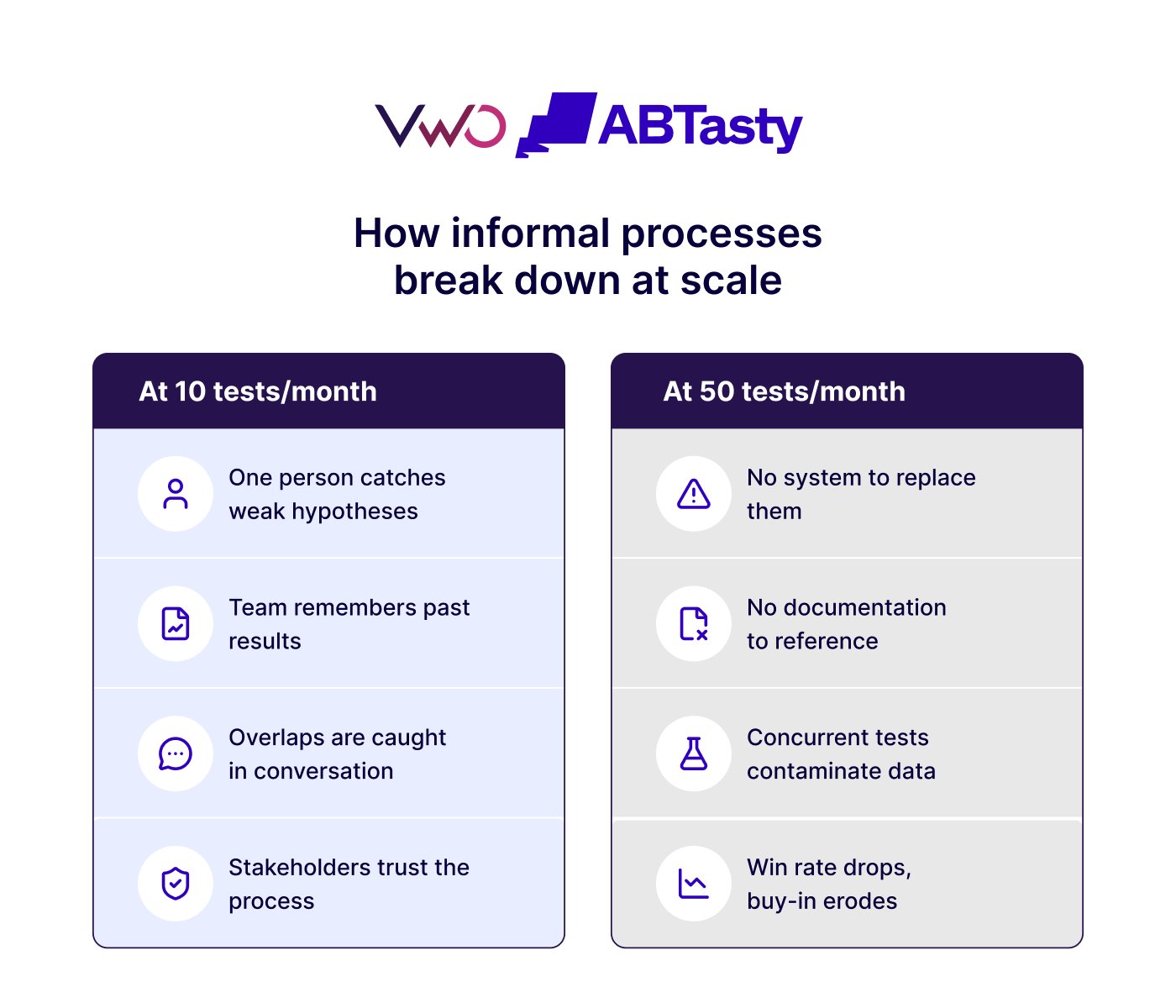
The trajectory of a typical experimentation program often begins with a “scrappy” approach. A single team, armed with a handful of hypotheses and a shared spreadsheet, launches tests on high-traffic landing pages. These early experiments frequently yield “low-hanging fruit”—obvious improvements in UI or copy that provide immediate, measurable lifts. This initial success builds internal confidence, prompting leadership to view experimentation as a primary lever for growth. Consequently, the demand for testing increases, more departments seek access to experimentation tools, and the pressure to generate insights at a higher velocity begins to mount. It is at this critical juncture that programs often begin to fracture. The informal processes that served a small team are rarely robust enough to sustain a high-velocity, multi-team environment.
The Chronology of Experimentation Maturity
To understand why scaling often leads to failure, it is essential to examine the lifecycle of an experimentation program. Industry analysts typically categorize this evolution into four distinct phases: the Pilot Phase, the Standardization Phase, the Scaling Phase, and the Maturity Phase.

In the Pilot Phase, testing is sporadic and localized. The primary goal is proof of concept. As the program moves into the Standardization Phase, teams begin to document their workflows and settle on a primary toolset. The Scaling Phase is where the most significant risks emerge; this is the period where test volume increases exponentially, often outstripping the organization’s governance capabilities. Finally, the Maturity Phase, or the “Center of Excellence” (CoE) model, represents a state where experimentation is decentralized across the company but governed by a centralized set of standards and infrastructure.
The “Scaling Trap” occurs when an organization attempts to move from Standardization to Scaling without investing in the necessary governance. According to industry data, nearly 80% of experiments in a typical corporate environment result in a “neutral” or “negative” outcome. When a program scales without rigor, the rate of “false positives”—winning results that fail to materialize into actual business growth—increases, leading to a phenomenon known as “innovation decay.”
Critical Pitfalls in High-Volume Testing
The breakdown of a scaling program is rarely the result of a single catastrophic error. Instead, it is the cumulative effect of several distinct operational and statistical pitfalls.
1. The Erosion of Statistical Rigor
As testing velocity becomes a Key Performance Indicator (KPI) for growth teams, there is a pervasive temptation to prioritize speed over accuracy. One of the most common errors is “peeking”—the practice of checking test results prematurely and calling a winner before the pre-determined sample size is reached. In a high-pressure environment, a test that looks positive after seven days is often terminated early to clear the “testing queue” for the next experiment.

However, statistical significance is not a static milestone; it fluctuates. Early results are highly susceptible to the “novelty effect” or simple variance. Terminating tests early significantly increases the Type I error rate (false positives). When these “winners” are implemented, they fail to move the needle on downstream business metrics, such as lifetime value or retention. Over time, this erodes the organization’s trust in the experimentation program itself.
2. Institutional Amnesia and the Lack of a Centralized Repository
In a decentralized testing environment, knowledge silos are a natural byproduct. Without a shared, searchable repository of every hypothesis, variation, and outcome, teams inevitably end up “reinventing the wheel.” A marketing team in the European division might run a pricing experiment that fails, while six months later, the North American product team runs the exact same test, unaware of the prior results.
This lack of a shared knowledge base represents a significant waste of resources. A mature experimentation program treats every test—regardless of whether it “wins” or “leses”—as a valuable data point. When insights are buried in disparate slide decks or private Slack channels, the program remains a collection of one-off experiments rather than a cohesive learning engine.
3. Metric Inconsistency and Governance Gaps
As experimentation spreads across different departments—from marketing and product to engineering and customer success—the definition of “success” often becomes fragmented. Marketing might optimize for click-through rates (CTR), while the product team focuses on feature adoption, and the finance team prioritizes average order value (AOV).

Without a unified “Global Metric Map,” these teams may inadvertently work at cross-purposes. For example, a marketing experiment that increases sign-ups by 20% might simultaneously lead to a 30% drop in lead quality, negatively impacting the sales department. High-performing organizations mitigate this by establishing a hierarchy of metrics, ensuring that every micro-experiment aligns with North Star business goals.
4. The Complexity of Interaction Effects
At low volumes, the risk of a single user being enrolled in multiple, conflicting experiments is minimal. However, at scale, interaction effects become a major threat to data integrity. If the “Check out” team is testing a new button color while the “Pricing” team is testing a discount banner on the same page, the results for both tests become confounded.
Identifying which change drove the behavior becomes statistically impossible without advanced “mutual exclusivity” configurations. Many organizations fail to realize that their testing tools lack the sophisticated governance required to manage these overlapping audiences, leading to “noisy” data that makes decision-making impossible.
The Role of Leadership and Cultural Integration
Beyond the technical and statistical challenges, the success of a scaled program depends heavily on organizational culture. Rafael Damasceno, a prominent figure in the Conversion Rate Optimization (CRO) space, argues that the limitations of many programs are rooted in a lack of leadership mandates. “If leadership doesn’t demand an experimentation mindset from all departments,” Damasceno notes, “the CRO team will be limited to gains in specific areas of the customer journey.”

When experimentation is viewed merely as a “plugin” for the marketing team, high-impact areas such as pricing models, product architecture, and onboarding flows remain untouched. To truly scale, experimentation must move from a tactical tool to a cultural philosophy where “I don’t know, let’s test it” becomes the default response to uncertainty.
Sarah Fruy, an expert in personalization and experimentation, emphasizes that the transition from a “scrappy” program to a cross-functional one requires a significant shift in operational overhead. Without proper infrastructure—such as role-based access controls and automated workflow management—the sheer volume of coordination required to keep a program running can overwhelm even the most talented teams.
Strategic Recommendations for Sustainable Growth
To avoid these pitfalls, organizations must treat experimentation infrastructure with the same level of importance as their financial or security systems. Several key strategies have emerged as best practices for scaling:
- The Experimentation Charter: Organizations should develop a formal document that outlines the “rules of engagement” for testing. This includes minimum confidence levels (typically 95%), required power (80%), and standardized durations to account for business cycles (e.g., testing for at least two full weeks to capture weekend vs. weekday behavior).
- Automated Mutual Exclusivity: Utilizing platforms that allow for the creation of “mutually exclusive groups” is essential. This ensures that a user in Experiment A is automatically excluded from Experiment B, protecting the purity of the data.
- Decentralized Execution with Centralized Governance: The most successful models allow individual product squads to run their own tests while a central “Experimentation Center of Excellence” provides the tools, training, and oversight to ensure quality.
- Connecting Tests to the Bottom Line: Every experiment should be mapped to a business outcome. This prevents “vanity testing” and ensures that the program remains focused on generating actual ROI rather than just increasing test velocity.
Broader Implications and the Future of Experimentation
The shift toward high-velocity experimentation is fundamentally changing how companies operate. In the past, business strategy was often determined by the “HiPPO” (Highest Paid Person’s Opinion). Today, that model is being replaced by an empirical approach where the customer’s behavior dictates the roadmap.
As artificial intelligence and machine learning become more integrated into experimentation platforms, the “manual” pitfalls of scaling may begin to diminish. AI-driven governance can automatically flag inconsistent metrics or detect interaction effects before they ruin a data set. However, technology is only a facilitator. The core of a successful program will always be the human element: the ability to form a sound hypothesis and the organizational discipline to follow the data, even when it contradicts internal assumptions.
In conclusion, scaling an A/B testing program is not merely about running more tests; it is about building a more resilient structure. By addressing statistical rigor, investing in shared knowledge, and securing leadership buy-in, organizations can transform a simple testing tool into a formidable engine for long-term innovation and growth. The path to maturity is complex, but for those who navigate the pitfalls correctly, the rewards are a deeper understanding of the customer and a sustainable competitive edge in an increasingly volatile market.