In the contemporary digital economy, the transition from occasional tactical testing to a robust, high-velocity experimentation program represents a critical inflection point for enterprise growth. While small-scale businesses may find success running a handful of experiments per quarter on high-impact pages using basic tooling, the complexity of a growing organization necessitates a fundamental shift in strategy. As products, campaigns, and teams multiply, the traditional linear approach to A/B testing often fractures under the weight of increased traffic demands, implementation bottlenecks, and the logistical challenges of coordinating simultaneous tests.

To maintain growth momentum, organizations must evolve their experimentation from a series of isolated events into a centralized growth infrastructure. This evolution requires a sophisticated blend of statistical governance, standardized processes, and advanced technical architecture to ensure that the pursuit of speed does not come at the expense of data reliability or user experience.
The Strategic Shift: Why Scaling Experimentation is Mandatory for Growth
The primary benefit of scaling A/B testing lies in its ability to transform experimentation from a mere “check-the-box” activity into a primary driver of evidence-based decision-making across all departments, including product, marketing, and engineering. When executed correctly, the impact of these tests compounds across the entire customer funnel.

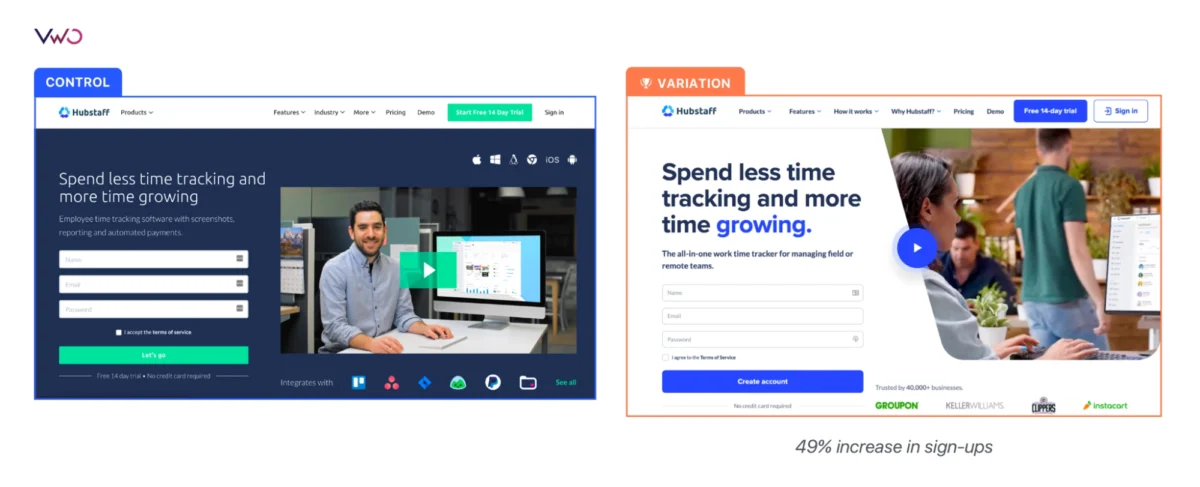
In a mature experimentation environment, teams no longer wait for a single test to conclude before initiating the next. Simultaneous experiments on calls-to-action (CTAs), checkout flows, and onboarding sequences allow for a cumulative revenue impact that far exceeds the results of isolated page-level tests. Furthermore, the compression of learning cycles allows for the rapid validation of winning ideas and the immediate abandonment of losing ones, significantly reducing the “opportunity cost” of acting on incorrect assumptions.
Furthermore, as audience diversity grows, aggregate conversion rates often become misleading. Scaling allows for sophisticated segmentation, revealing how different user cohorts—such as first-time visitors versus returning subscribers—respond to specific variations. This granularity ensures that “segment-level losses” are not hidden behind positive averages, allowing for a more personalized and effective user experience.

Identifying the Breaking Point: Signs of Ineffective Scaling
Before an organization can successfully scale, it must recognize the symptoms of a program that has outgrown its current infrastructure. Industry analysts point to several “red flags” that indicate a breakdown in experimentation efficiency:
- Stagnant Statistical Significance: Tests frequently run for extended periods without reaching a clear result. This often indicates that traffic is being fragmented across too many concurrent experiments, diluting the power of the data.
- The Deployment Gap: A “winning” variation is identified but remains in the engineering queue for weeks or months. This suggests a failure in release coordination rather than an experimentation problem.
- Conflicting Data Sources: Discrepancies between testing platforms and primary analytics (such as GA4) erode trust in the results, leading to decision paralysis.
- Hypothesis Degradation: As the backlog grows, the quality of ideas often drops. Teams may find themselves testing minor cosmetic changes or re-testing ideas that were previously invalidated because past results were not properly documented.
- Leadership Disengagement: When executive stakeholders stop inquiring about test outcomes, it is usually a sign that past results failed to hold up in production or were never clearly linked to strategic business metrics.
A Phased Framework for Scaling A/B Testing
To move beyond these bottlenecks, organizations must follow a structured roadmap designed to build a scalable experimentation culture.
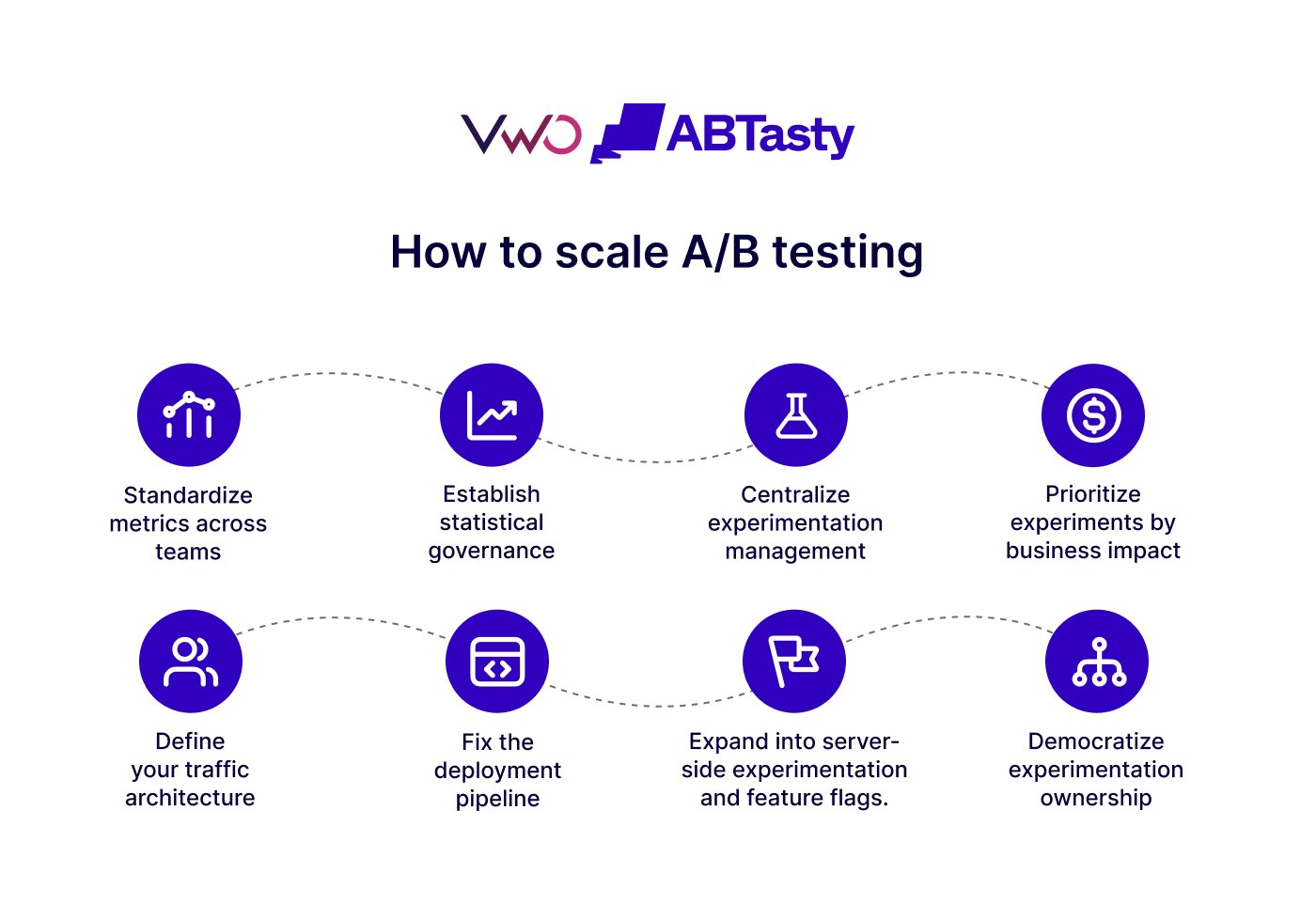
Phase 1: Establishing Statistical and Metric Governance
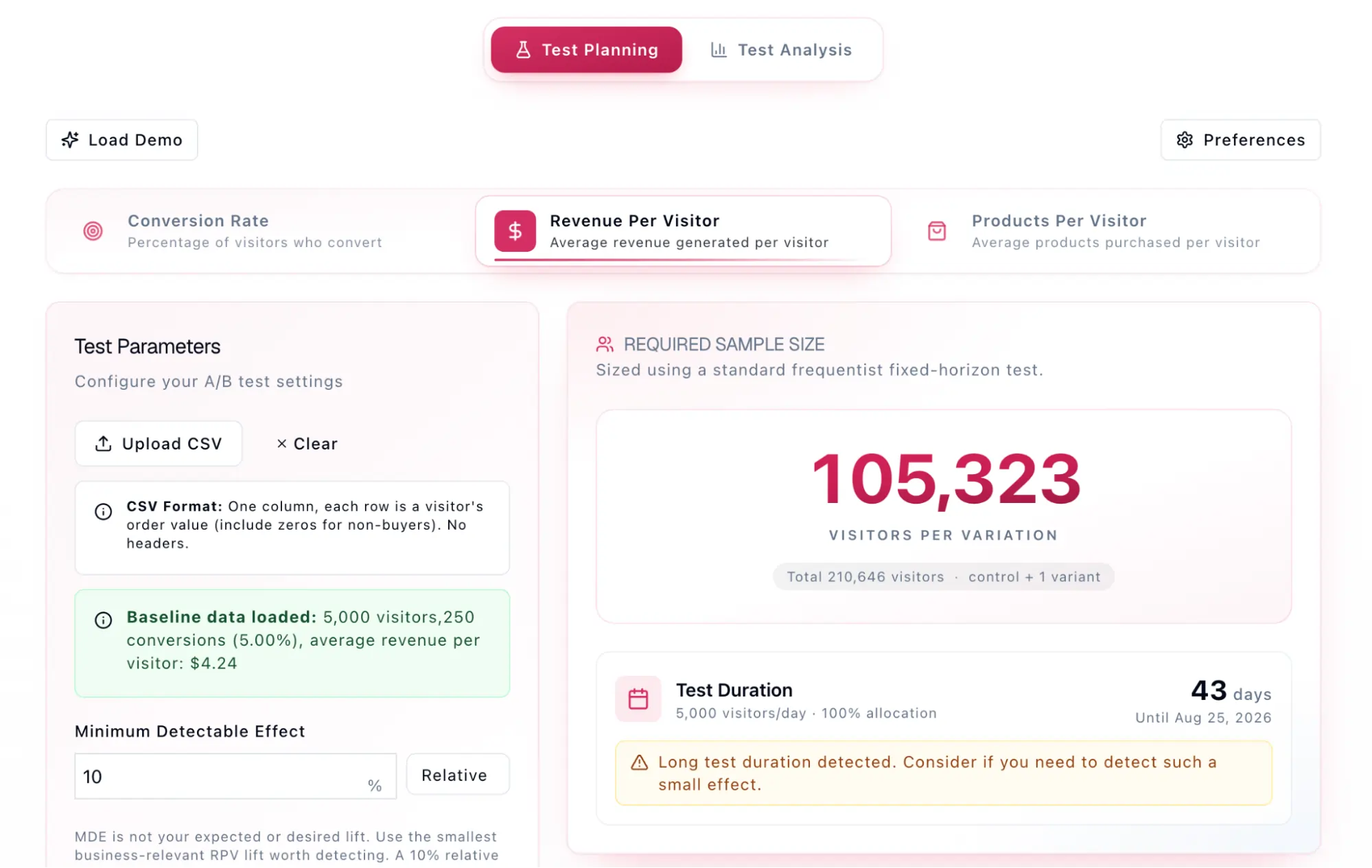
The foundation of any scaled program is the standardization of metrics. Teams must agree upon universal definitions for conversion rates, activation, and attribution windows. Without this, results remain open to interpretation and debate. Crucially, every test must define both “primary metrics” (success indicators) and “guardrail metrics” (indicators that the change is causing harm elsewhere in the funnel).
Statistical governance is equally vital. This involves embedding controls into the workflow, such as pre-launch sample size calculations, fixed end dates, and Sample Ratio Mismatch (SRM) checks. These automated checks ensure that the increase in test volume does not lead to an accumulation of false positives.
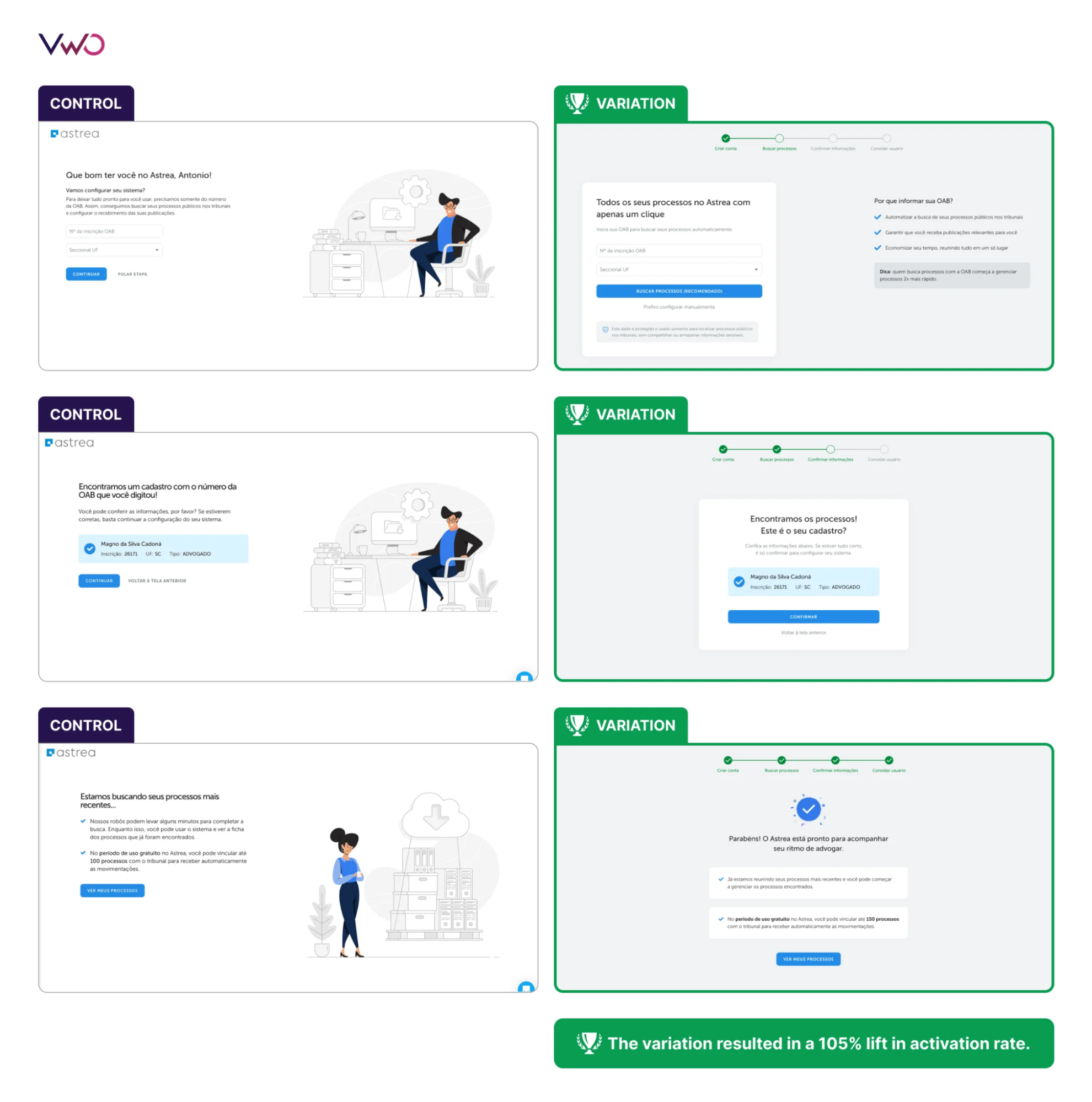
Phase 2: Centralization and Prioritization
As the number of teams involved in testing grows, a centralized hypothesis repository becomes essential. This shared log ensures that institutional knowledge is preserved even as personnel change. To manage the influx of ideas, organizations often adopt scoring frameworks like ICE (Impact, Confidence, Ease) or PIE (Potential, Importance, Ease).
Antonia Grzelak, Manager of Growth & Innovation at FUNKE Works, emphasizes the utility of the ICE score in a structured approach: “We start where the leverage is high and the effort is low—typical low-hanging fruit for growth—and work our way up from there.”
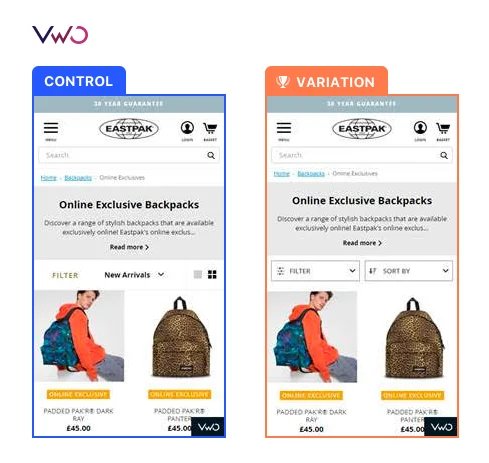
Phase 3: Traffic Architecture and Deployment Optimization
High-concurrency testing requires a sophisticated “traffic architecture.” Organizations must decide which experiments are mutually exclusive and which can run simultaneously on non-overlapping segments.
Furthermore, the deployment pipeline must be decoupled from standard engineering sprint cycles. Front-end changes should ideally be deployable directly from the testing platform, while more complex server-side changes should be managed via feature flags. This allows for “progressive rollouts,” where a new feature is exposed to 5% of traffic to validate stability before a full release.
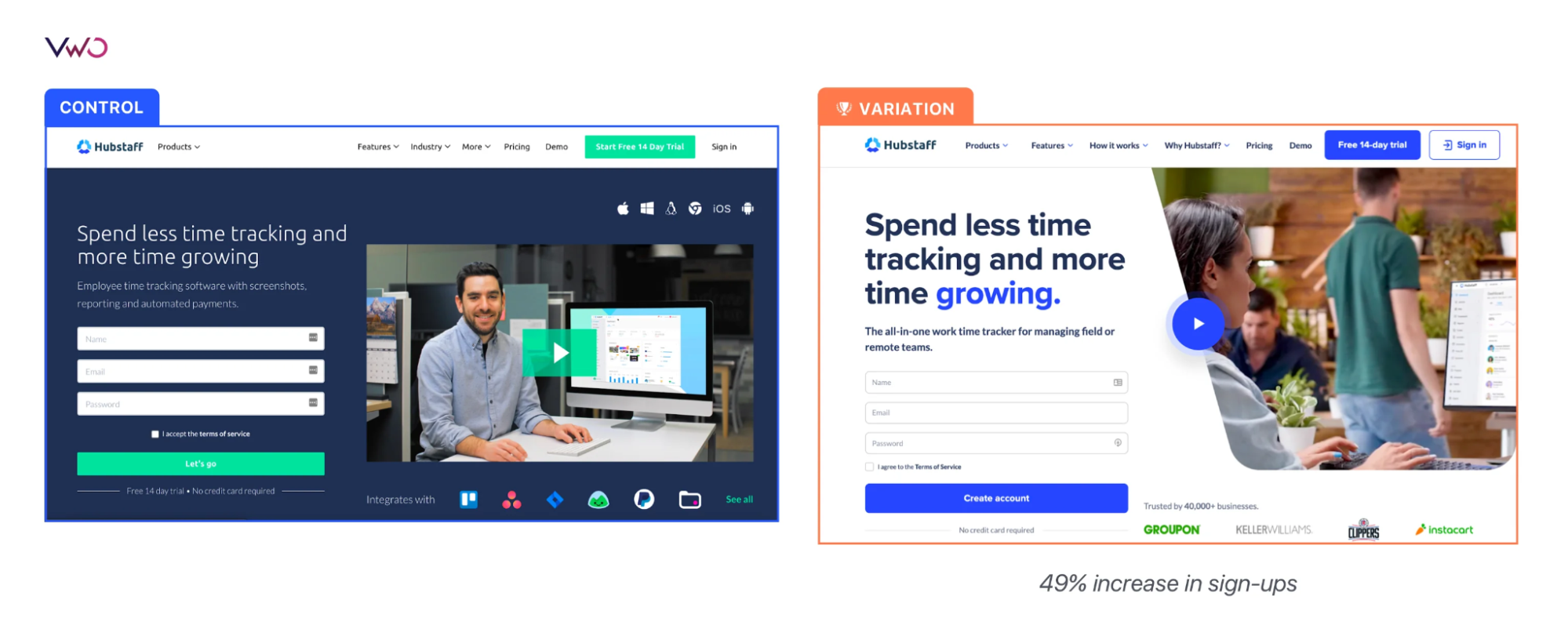
Advanced Technical Strategies for High-Volume Testing
For organizations reaching the upper echelons of maturity, several advanced strategies can further accelerate velocity:
- CUPED (Controlled-experiment Using Pre-Experiment Data): This statistical technique reduces metric variance by incorporating historical user data into the analysis. By lowering variance, teams can detect meaningful effects with smaller sample sizes, effectively increasing the speed of every test.
- Server-Side Experimentation: While client-side testing is sufficient for UI changes, server-side testing is required for pricing logic, recommendation algorithms, and backend architecture. This provides more security and deeper integration with the product’s core functionality.
- AI-Assisted Experimentation: Artificial Intelligence is increasingly used to identify friction points in user behavior data, generate new hypotheses, and automate the creation of variations. AI can process vast amounts of behavioral data far faster than human analysts, helping to maintain quality as volume increases.
Measuring Success: The Three Tiers of Metrics
A scaled program cannot be judged solely by conversion rates. Success must be tracked across three distinct tiers:
- Program-Level Metrics: These include “Experiment Velocity” (number of tests started per month), “Win Rate” (percentage of tests that reach a positive significant result), and “Implementation Rate” (the percentage of winning variations actually deployed).
- Business and Revenue Metrics: These focus on commercial impact, such as Average Revenue Per User (ARPU), Customer Acquisition Cost (CAC), and Customer Lifetime Value (LTV).
- North Star Metrics: These are the long-term growth indicators the entire company optimizes around, such as “Monthly Active Users” or “Recurring Revenue.” High-performing programs ensure that every individual test can be logically linked back to these strategic goals.
Evidence from the Field: Case Studies in Scaled Success
Several global organizations have demonstrated the power of this structured approach:
- AURUM: The legal technology firm utilized feature experimentation to optimize its 10-day free trial. By testing guided onboarding flows and retroactive data access, they achieved a four-fold increase in trial activation rates within a year.
- Eastpak: Operating across 12 European websites in eight languages, the accessories brand moved from outsourced testing to an in-house, centralized workflow. By using web rollouts to deploy changes without developer intervention, they improved filter interactions by 106%.
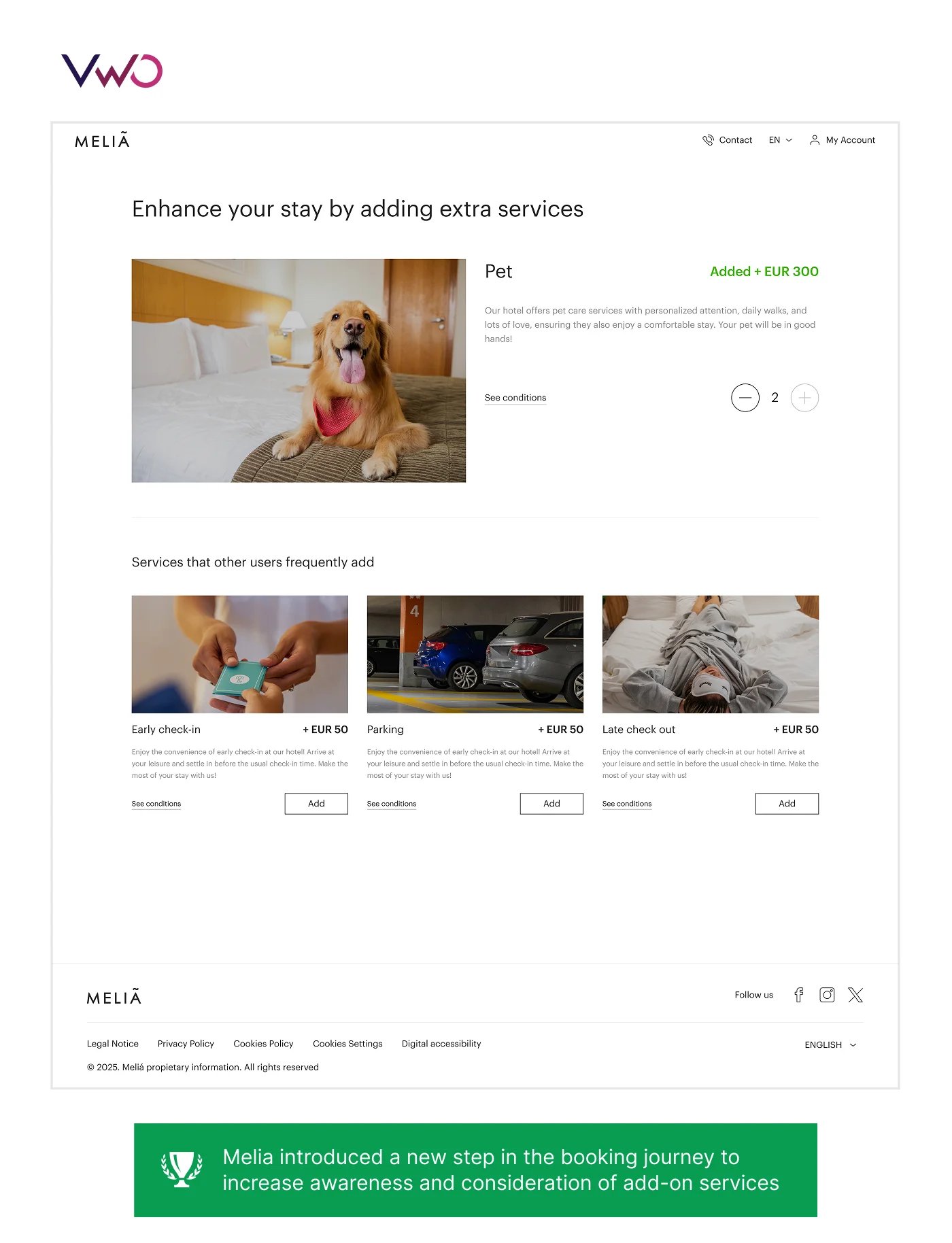
- Meliá Hotels International: To de-risk the addition of new steps in its booking funnel, the hotel group used feature flags to progressively roll out changes. This “safety-first” approach resulted in a 1.85% uplift in revenue per visitor without increasing funnel drop-offs.
- One Click Ventures: By integrating experimentation into agile sprint cycles, this eyewear retailer achieved a velocity of three to five tests per week across three brands. One regional personalization test alone resulted in a 30% increase in conversion rates.
The Broader Impact: Towards a Democratized Experimentation Culture
The ultimate goal of scaling is the democratization of experimentation. In this model, marketing teams run acquisition tests, engineering teams run backend optimizations, and product teams test new features—all operating autonomously within a shared governance framework. The role of the central experimentation team shifts from “doing the work” to “enabling the work” through training, quality assurance, and knowledge sharing.
In conclusion, scaling A/B testing is not merely about running more tests; it is about building the infrastructure, processes, and culture necessary to make data-driven decisions at the speed of modern business. For organizations that successfully make this transition, experimentation becomes a sustainable competitive advantage, turning every user interaction into an opportunity for learning and growth. As the digital landscape becomes increasingly crowded and complex, the ability to validate ideas quickly and reliably will remain the primary differentiator between market leaders and those left behind.