The rapid proliferation of generative artificial intelligence (AI) has created a fundamental paradox for the modern digital consumer: the tools that offer the most significant productivity gains also represent the most substantial risks to personal and corporate data privacy. Since the public release of ChatGPT in late 2022, the “Postcard Rule”—the concept that any data sent to a cloud-based AI should be treated as public information written on a postcard—has become the gold standard for cybersecurity experts. As these tools evolve from simple chatbots into integrated personal assistants, the urgency for users to understand the mechanics of data retention, model training, and privacy toggles has never been greater.
The Mechanics of Data Processing in Large Language Models
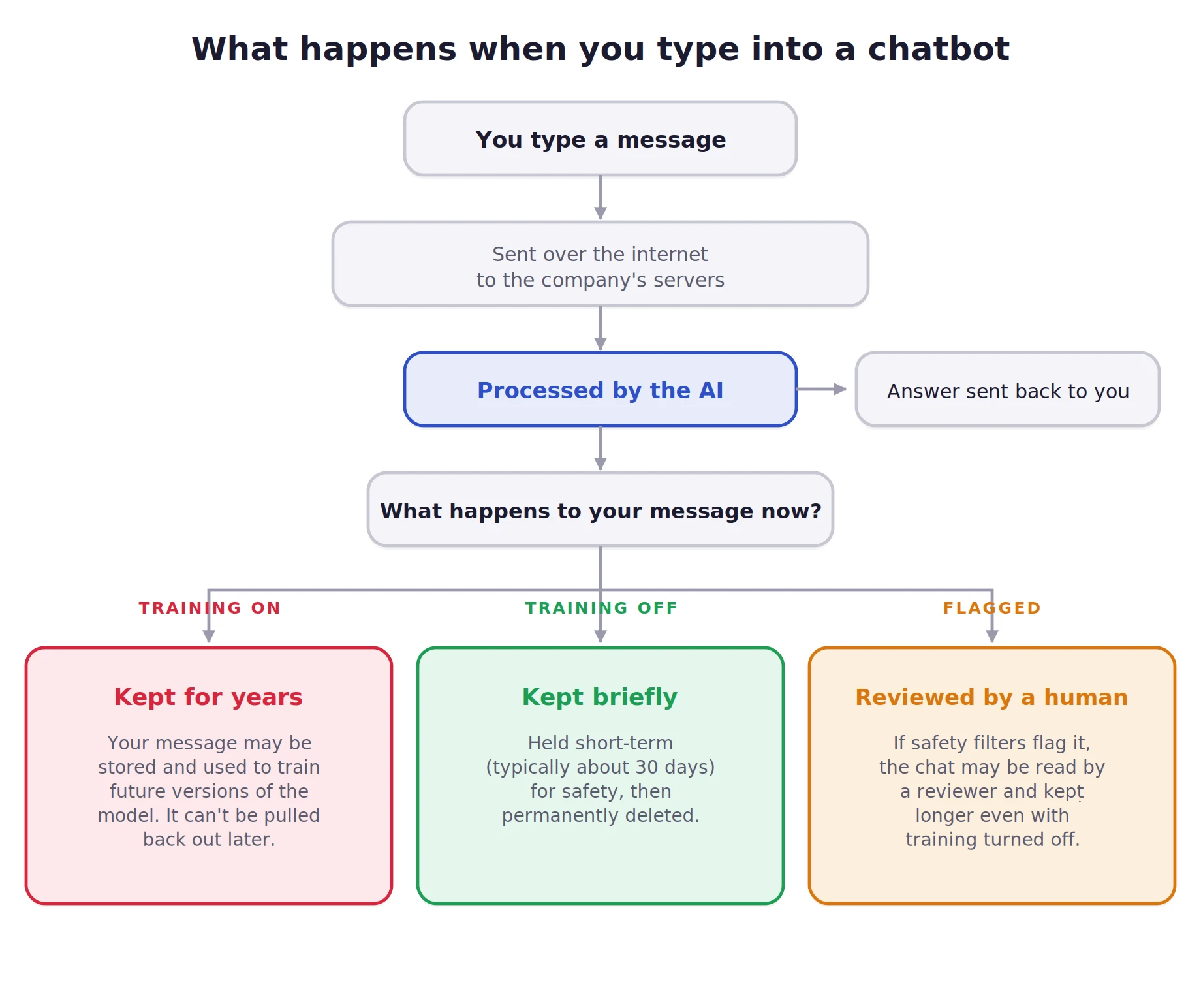
To understand the privacy risks associated with AI, one must first dismantle the misconception that a chatbot functions like a private, local notepad. When a user enters a prompt into a service like OpenAI’s ChatGPT, Anthropic’s Claude, or Google’s Gemini, the information does not remain on the user’s device. Instead, the text is transmitted to the provider’s remote servers.

Once on the server, the data typically undergoes a multi-stage process. First, it is processed to generate a real-time response. Second, it is often logged for “safety and monitoring” purposes to ensure the user is not violating terms of service. Third, and most controversially, the data may be ingested into a training pool. This process, known as Reinforcement Learning from Human Feedback (RLHF), uses real-world interactions to refine the model’s future accuracy. If a user shares a proprietary software bug or a sensitive medical diagnosis, that information could, in theory, be synthesized and surfaced in a response to a different user in the future.
A Chronology of AI Privacy Milestones
The current landscape of AI privacy has been shaped by a series of high-profile incidents and regulatory interventions over the last several years.
- November 2022: OpenAI releases ChatGPT. Initial privacy controls are minimal, and the default setting allows all user data to be used for model training.
- March 2023: A significant data breach at OpenAI exposes the chat titles and payment information of a small percentage of users, highlighting the vulnerability of centralized AI databases.
- April 2023: Italy’s Data Protection Authority (Garante) temporarily bans ChatGPT over privacy concerns, specifically citing the lack of a legal basis for the mass collection of personal data for training purposes.
- May 2023: Major corporations, including Samsung and Apple, restrict or ban the internal use of generative AI after employees inadvertently leaked sensitive source code and meeting notes into the platforms.
- Late 2023 – 2024: In response to regulatory pressure and corporate demand, AI providers begin introducing “Incognito” or “Temporary” modes and clearer “Opt-out” toggles for model training.
- 2025-2026: The industry sees a shift toward “Edge AI” and local processing, as users demand the benefits of LLMs without the necessity of cloud-based data transmission.
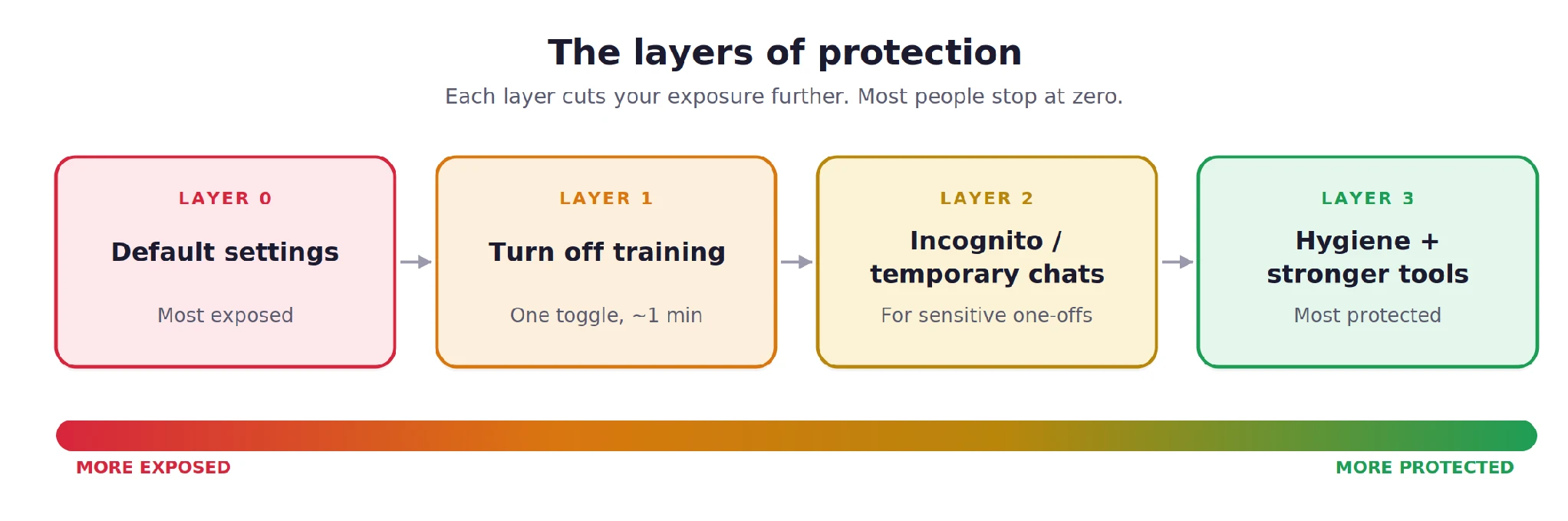
The Three-Layer Framework for Data Protection
Cybersecurity analysts suggest that users should approach AI privacy through a layered defense strategy. Relying on a single setting is often insufficient, as company policies can change with updated terms of service.
Layer 1: Disabling Model Training
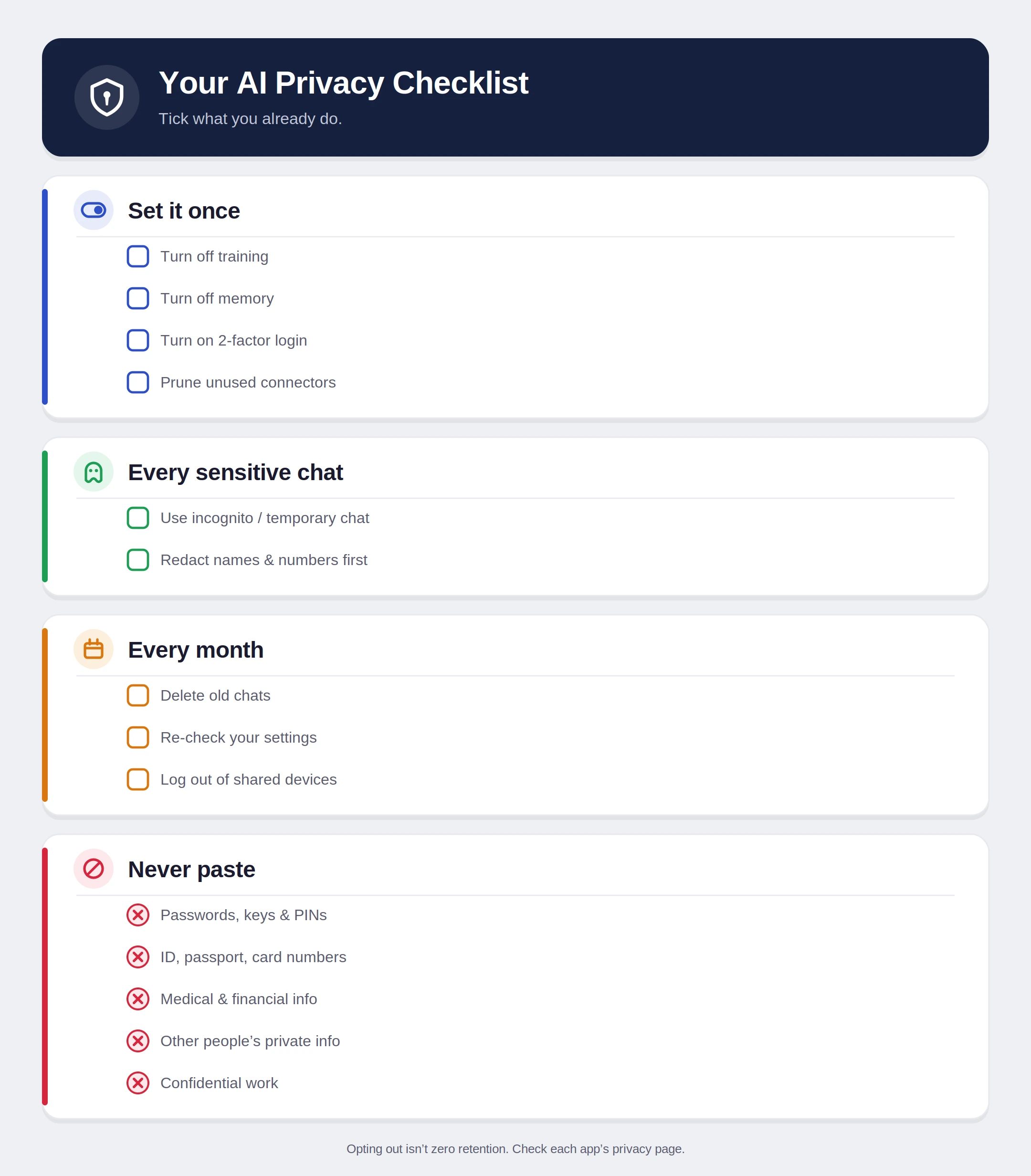
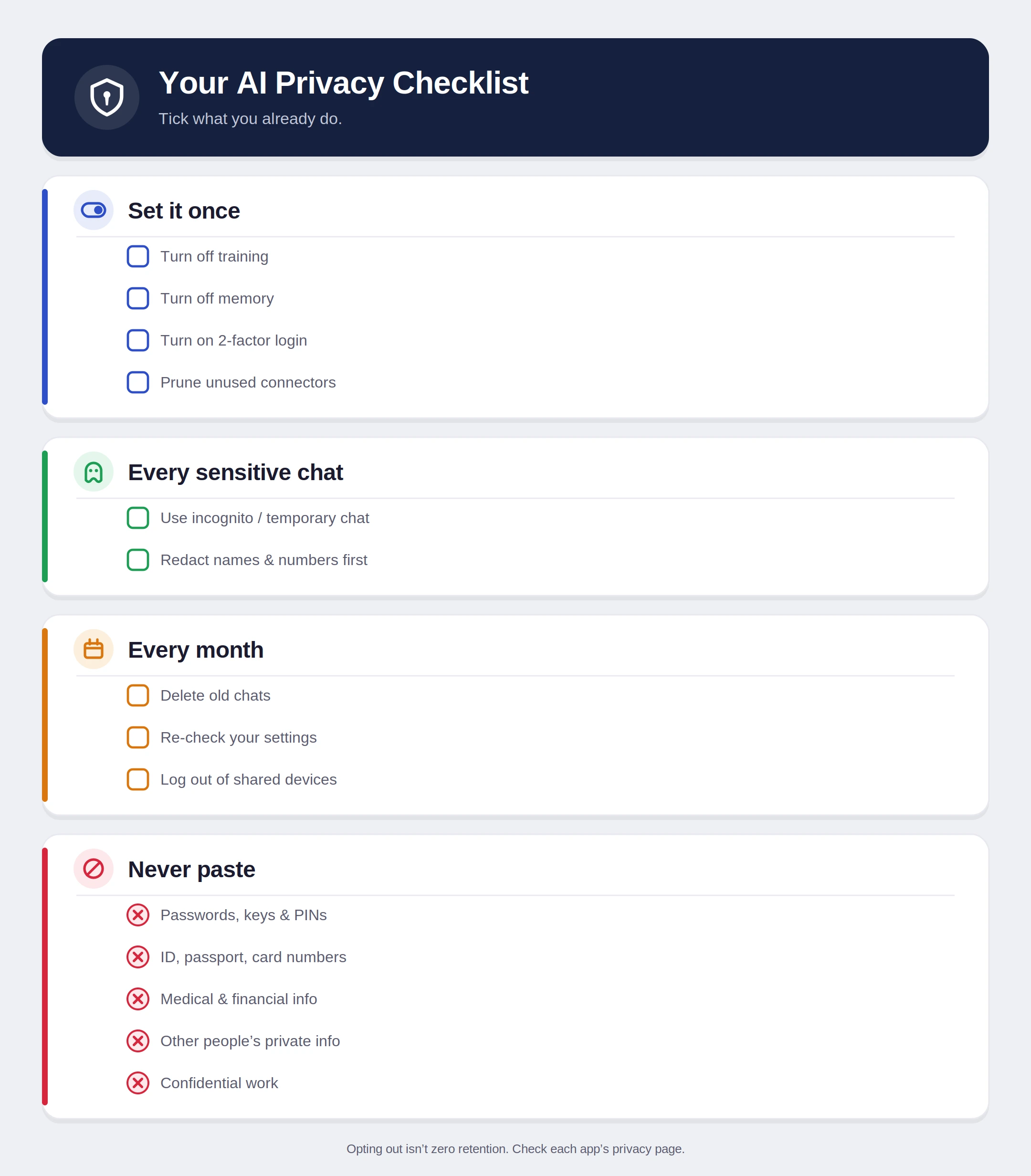
The most critical step for any AI user is to opt out of the provider’s training program. This does not necessarily stop the company from seeing the data for safety moderation, but it prevents the data from becoming a permanent part of the AI’s “knowledge.”
- ChatGPT: Users must navigate to Settings, then Data Controls, and disable the “Improve the model for everyone” toggle.
- Claude: In the Privacy settings, users should ensure that “Help improve Claude” is switched off.
- Gemini: Google integrates AI data with its broader “Gemini Apps Activity” settings. Turning this off prevents the storage of prompts in the user’s Google Account.
- Grok (X): This platform requires users to disable data sharing in both the general X settings and the specific in-chat toggles.
It is important to note that opting out of training often disables chat history features in some applications. Users are frequently forced to choose between the convenience of a searchable history and the security of data privacy.
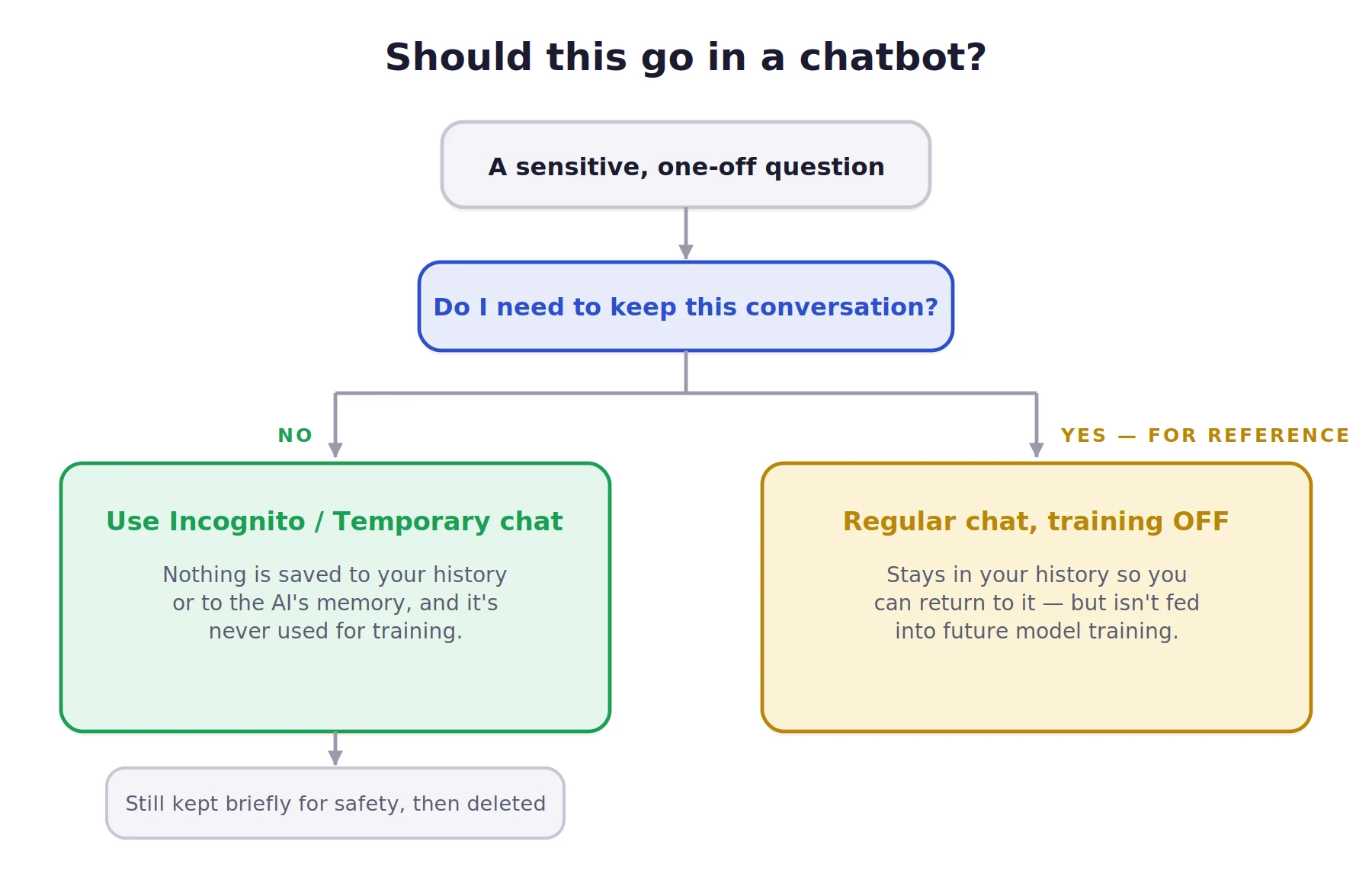
Layer 2: Utilizing Ephemeral and Incognito Sessions
For tasks involving sensitive but non-classified information, “Temporary Modes” offer a secondary layer of protection. These sessions act as a digital “Etch-A-Sketch.” Once the window is closed, the conversation is deleted from the user’s visible history and the model’s short-term memory.
While these modes are an improvement, they are not absolute. Companies typically retain “temporary” chats on their backend servers for a period ranging from 3 to 30 days to check for “abuse or harmful content” before permanent deletion. Therefore, even in incognito mode, the “Postcard Rule” still applies to extremely sensitive data.
Layer 3: Technical Sovereignty and Local Models
For users requiring absolute privacy—such as legal professionals, medical researchers, or software engineers—the only foolproof solution is to move away from consumer-grade cloud AI. This involves the use of local, open-source models (such as Llama 3 or Mistral) run on the user’s own hardware. Tools like LM Studio, Ollama, or GPT4All allow users to run powerful AI models entirely offline. In this scenario, no data ever leaves the physical machine, providing a “Zero Data Retention” environment that cloud providers cannot technically match.
Industry Data and the Cost of Inaction
The risks of negligent AI use are not merely theoretical. A 2023 study by the security firm Cyberhaven found that approximately 11% of employees have pasted sensitive corporate data into ChatGPT. Of that data, 4% was classified as “highly sensitive,” including source code, patient records, and strategic planning documents.
Furthermore, the “right to be forgotten” under the General Data Protection Regulation (GDPR) presents a significant technical challenge for AI companies. Once data is baked into a model’s weights during training, it is mathematically difficult, if not impossible, to “unlearn” that specific piece of information without retraining the entire model at a cost of millions of dollars. This makes proactive privacy settings the only reliable method of data control.
The Strategy of Redaction and Anonymization
In a journalistic and professional context, the most effective way to use AI safely is to change the way prompts are written. This is known as “Data Redaction.” Instead of providing the AI with specific identifiers, users are encouraged to generalize their queries.
For instance, a human resources manager seeking advice on a difficult termination should never input: “Draft a termination letter for John Doe, an engineer at our Austin branch who failed his performance review on June 12th.” Instead, the prompt should be: “Draft a template for a termination letter for a technical role based on performance issues, ensuring compliance with standard labor guidelines.”
The resulting output is identical in utility, but the risk of exposing personal identifiable information (PII) is reduced to zero.
Broader Implications and the Future of AI Privacy
The tension between AI utility and data privacy is driving a new sector of the economy: Privacy-Preserving Machine Learning (PPML). Technologies such as federated learning and differential privacy are being developed to allow models to learn from data without ever actually “seeing” the raw, sensitive details.
Governmental bodies are also stepping in. The European Union’s AI Act, the world’s first comprehensive AI law, mandates high transparency and data governance standards for “high-risk” AI systems. In the United States, the White House Executive Order on AI emphasizes the need for privacy-enhancing technologies (PETs) to protect citizens’ data from being exploited by AI training sets.
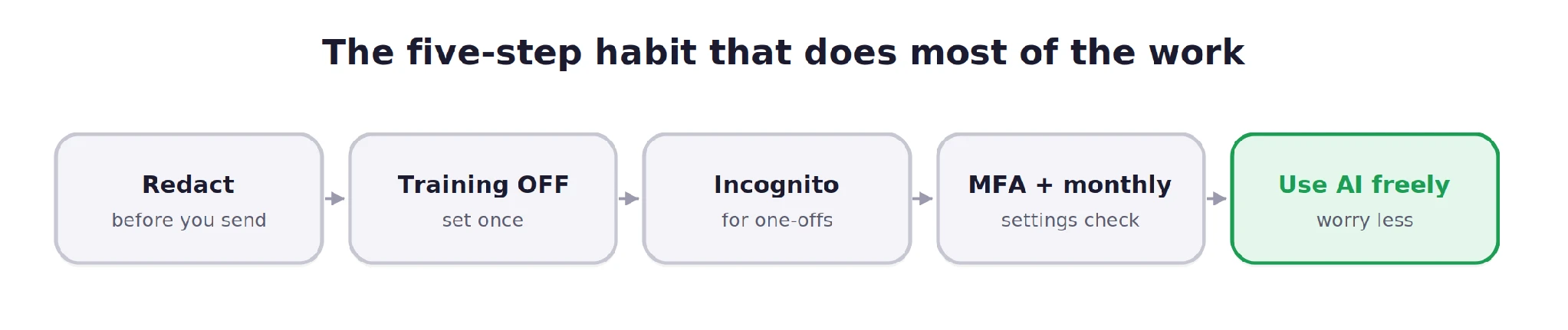
Conclusion: Adopting Digital Hygiene
Ultimately, the responsibility for AI privacy lies with the user. No software toggle can fully replace the exercise of human judgment. While the convenience of AI is undeniable, it must be balanced with the understanding that these platforms are, at their core, data-collection engines.
By following a strict protocol—disabling training, using temporary modes for sensitive tasks, and practicing aggressive redaction—users can harness the power of artificial intelligence without sacrificing their digital identity. In the modern era, distrust of cloud-based systems is not a sign of paranoia; it is the hallmark of good digital hygiene. As the technology continues to integrate into every facet of daily life, the ability to “lock the door” on one’s private data will remain the most valuable skill in the digital toolkit.