The landscape of artificial intelligence is currently witnessing a pivotal shift from monolithic, all-purpose models toward specialized agents designed to master specific segments of the information processing pipeline. At the forefront of this evolution is Harness-1, a compact yet formidable retrieval subagent developed through a high-level collaboration between researchers from the University of Illinois Urbana-Champaign (UIUC), UC Berkeley, and the vector database firm Chroma. By decoupling the cognitive task of generating search queries from the administrative task of tracking search progress, Harness-1 addresses a fundamental bottleneck in modern AI search: the “messy” entanglement of high-level strategy and low-level bookkeeping.
Traditional retrieval agents are typically trained in an end-to-end fashion, a method that forces a single neural network to manage every aspect of a search episode. In these legacy systems, the model must simultaneously generate new queries, read through massive data chunks, identify relevant evidence, deduplicate information, and determine when to terminate the search. While this approach is theoretically simple, it often leads to a performance plateau. Reinforcement Learning (RL) struggles to optimize these disparate functions because semantic search decisions—such as choosing between “merger date” and “acquisition year”—require different learning dynamics than the mechanical tasks of tracking which documents have already been scanned. Researchers identify this as a “core design flaw” in current agentic architectures, where low-level state management interferes with high-level reasoning.
The Architectural Breakthrough: The Stateful Harness
The primary innovation of Harness-1 is the introduction of a “stateful harness” that functions as an external state machine for the model. Instead of requiring the 20-billion-parameter model to remember every step of its journey within its own context window, the harness maintains four persistent, structured data components: a query history, a repository of retrieved chunks, a comprehensive evidence graph, and a curated set of final documents. This externalization of memory allows the model to remain “clean,” focusing its computational budget entirely on processing signals rather than navigating noise.

The evidence graph is particularly sophisticated. It utilizes a regex-based extractor to scan retrieved data for specific entities such as proper nouns, dates, and fiscal years. When the system identifies “bridge documents”—files that contain two or more entities frequently appearing together—it flags them as high-priority targets. Conversely, “singletons” (entities appearing in isolation) are marked for potential follow-up searches. By presenting this pre-processed information to the model in a compact format at each turn, the harness enables the agent to make significantly more informed decisions about its next action.
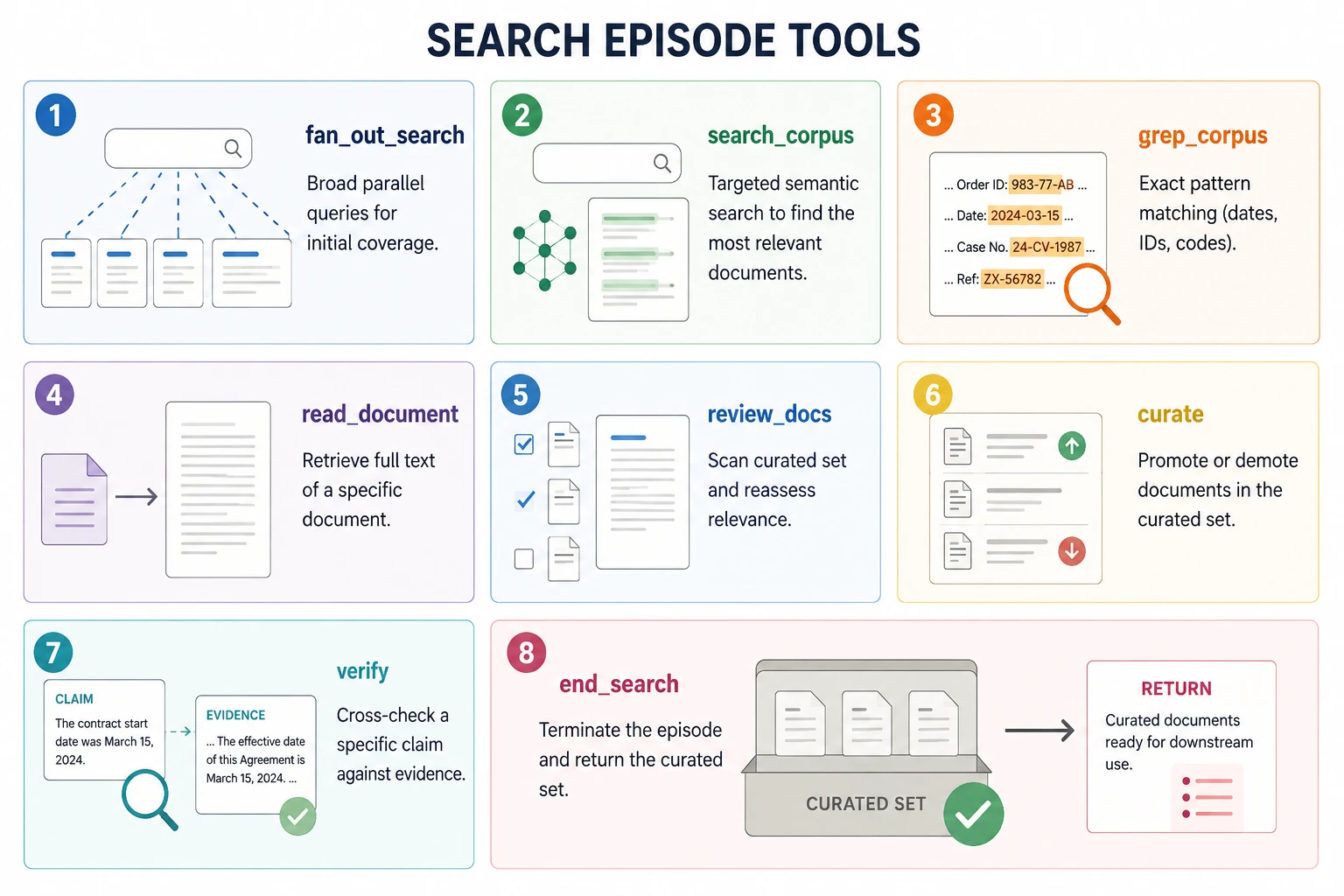
The Eight-Tool Interface and Data Compression
Harness-1 operates through a specialized eight-tool interface, where the model emits exactly one structured action per turn. This restricted but powerful vocabulary includes commands such as search_corpus, grep_corpus, verify, and read_document. By limiting the model to specific tool calls, the researchers ensure that the agent remains a dedicated retrieval specialist rather than drifting into conversational or reasoning tasks that are better handled by downstream Large Language Models (LLMs).
To manage the volume of data retrieved during a search episode, the system employs a rigorous two-phase compression strategy. In the first phase, Sentence-BM25 is used to rank sentences within retrieved chunks, selecting only the top four most relevant sentences. The second phase involves a dual-layered de-duplication process: first by chunk ID and then by a content fingerprint. The policy never interacts with raw, unrefined retrieval output, ensuring that every token processed by the model contributes directly to the search objective. This focus on “signal-only” input is a major contributor to the model’s ability to outperform models five times its size.
Overcoming the Cold Start Problem
One of the most significant hurdles in training retrieval agents is the “Cold Start Problem,” where a policy in its early RL stages lacks a prior foundation for curation. Without a starting point, early models often exhibit erratic behavior, either hoarding every document they find or failing to collect any at all. Harness-1 resolves this through a mechanism called “warm-start seeding.”
In this approach, once the harness performs its initial search, it automatically populates a curated dataset using the top eight reranked results. This shifts the model’s primary objective from “creation from scratch” to “refinement.” By tasking the model with improving an existing set—increasing the weight of high-quality documents and discarding weaker ones—the researchers observed a dramatic increase in training stability. This suggests that for AI agents, the ability to curate is more effectively learned through iterative refinement than through initial assembly.
Training Methodology: SFT and CISPO Reinforcement Learning
The development of Harness-1 followed a two-stage training pipeline. The first stage, Supervised Fine-Tuning (SFT), utilized a teacher model—the frontier-class GPT-5.4—to generate trajectories within the harness environment. After filtering for high-performance episodes, a dataset of 899 trajectories was used to train the base model (gpt-oss-20b) on how to structure actions and update curated sets using LoRA (Low-Rank Adaptation) configurations.
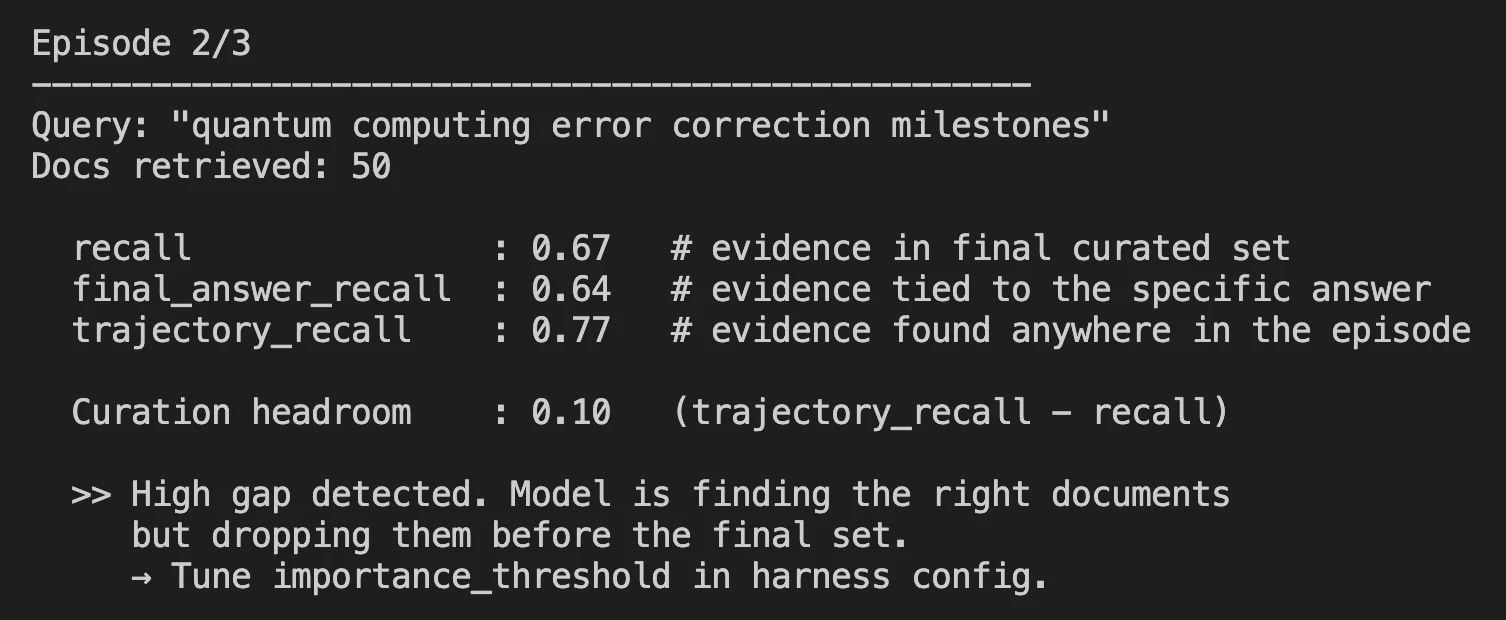
The second stage involved Reinforcement Learning using an on-policy CISPO (Constrained Iterative Soft Policy Optimization) algorithm. A critical component of this stage was the implementation of a terminal reward function with a “diversity bonus.” Without this bonus, agents frequently became trapped in “stalling” loops, issuing repetitive queries and filling curated sets with redundant information, resulting in a recall score of approximately 0.53. By rewarding the use of diverse tools like grep_corpus and verify, the researchers boosted the curated recall to 0.60 during the training phase on SEC financial documents.
Benchmarking and Performance Metrics
Harness-1 was subjected to rigorous testing across eight diverse domains, including SEC financial filings, patent databases, web searches, and multi-hop question-answering (QA) tasks. The primary metric for success was “Curated Recall”—the percentage of relevant documents that successfully made it into the final output of 30 documents.
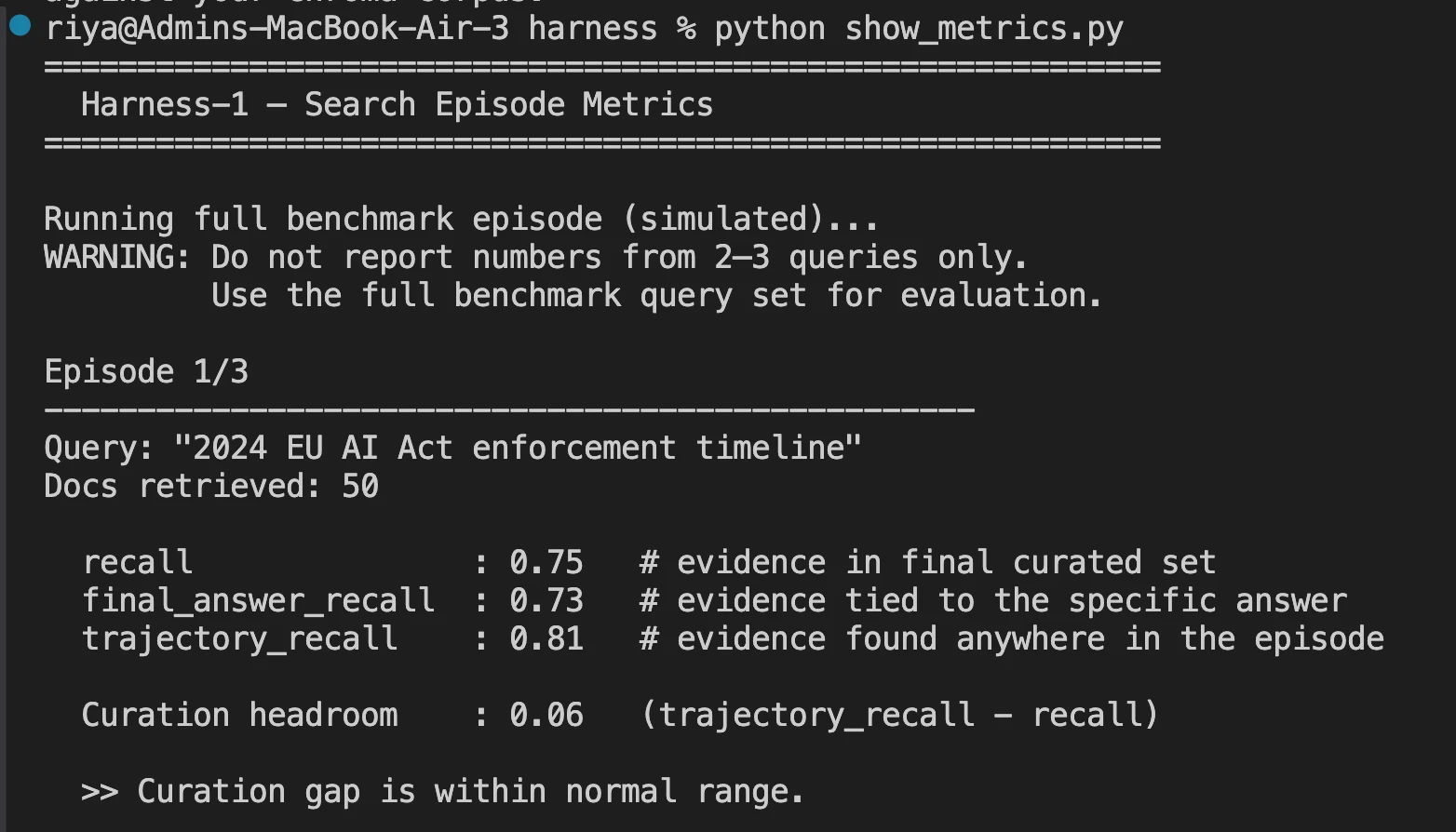
The results positioned Harness-1 as a “giant killer” in the retrieval space. Despite its 20B parameter size, it achieved a Curated Recall score of 0.730. This outperformed several frontier models and larger open-weights competitors:
- Harness-1 (20B): 0.730
- GPT-5.4 (Frontier): 0.709
- Sonnet-4.6 (Frontier): 0.688
- Tongyi DeepResearch (30B): 0.616
- Search-R1 (32B): 0.289
Only the frontier-grade Opus-4.6 (0.764) managed to exceed the recall performance of Harness-1. This data underscores a significant realization in AI development: a smaller, specialized model with a well-designed external “harness” can effectively compete with, and often beat, general-purpose models with significantly higher parameter counts.
Implementation and Local Deployment
For researchers and developers, the Harness-1 project has been made accessible via public weights and a GitHub repository. The system is designed to run efficiently on local hardware, requiring roughly two 40GB GPUs to avoid out-of-memory issues when utilizing the vLLM inference server. The deployment process involves cloning the repository, syncing dependencies via the uv package manager, and serving the model using a local OpenAI-compatible API.
Notably, Harness-1 does not return a narrative answer. When queried, it provides structured tool actions, such as fan_out_search(queries=[...]). This output is then fed back into the stateful harness to execute the search against the user’s specific corpus. This makes it an ideal “sub-agent” for integration into larger RAG (Retrieval-Augmented Generation) pipelines where the goal is to provide a high-reasoning model with the most relevant possible context.
Analysis of Implications and Future Outlook
The success of Harness-1 provides a compelling counterpoint to the “scaling laws” that have dominated AI discourse for the past several years. While increasing parameter counts and compute budgets remains a viable path to intelligence, the Harness-1 results suggest that architectural modularity and state management are equally potent levers for performance.
By treating retrieval as a specialized discipline rather than a subset of general chat, the developers have created a tool that is more interpretable and easier to debug. When a search fails in a monolithic model, it is often impossible to determine if the failure occurred during query generation, document reading, or internal memory management. In Harness-1, the separation of these concerns allows developers to pinpoint exactly where a trajectory went off-course.
However, the model does have recognized limitations. Its training was heavily focused on financial (SEC) documents, and while it showed remarkable generalization to patents and web data, the fundamental differences in document structure across domains remain a challenge for future iterations. Furthermore, the reliance on an expensive teacher model like GPT-5.4 for SFT trajectories poses questions about the scalability of creating training data for even more niche domains.
Conclusion
Harness-1 serves as a blueprint for the next generation of AI agents. It demonstrates that by moving state management out of the neural network and into a structured harness, we can build systems that are more efficient, more accurate, and more capable than their size would suggest. As the industry moves toward more complex agentic workflows, the “retrieval subagent” model pioneered here is likely to become a standard component in high-performance RAG architectures, providing the precision necessary for professional-grade AI applications in law, finance, and scientific research.