The landscape of artificial intelligence has shifted dramatically from centralized, API-dependent models toward a decentralized ecosystem where localized fine-tuning is not only possible but increasingly preferred. The emergence of high-performance open-source libraries has effectively democratized the ability to customize Large Language Models (LLMs), allowing developers and researchers to adapt massive architectures like Llama 3, Mistral, and Qwen to specific tasks without the need for massive industrial compute clusters. This evolution is driven by advancements in parameter-efficient techniques and memory optimization, which have collectively lowered the barrier to entry for individual developers and small-to-medium enterprises.
The Evolution of Local Fine-Tuning: Context and Background
Historically, the process of fine-tuning a model with billions of parameters required a specialized infrastructure stack, often involving dozens of A100 or H100 GPUs. The "pre-training" phase of a model provides it with general world knowledge, but "fine-tuning" is what transforms a general-purpose model into a specialized tool—whether for medical diagnosis, legal drafting, or coding assistance.

The catalyst for the current local fine-tuning boom was the release of Meta’s Llama series, which sparked a community-driven race to optimize model performance on consumer-grade hardware. Techniques such as Low-Rank Adaptation (LoRA) and Quantized LoRA (QLoRA) revolutionized the field by allowing users to train only a tiny fraction (often less than 1%) of the model’s total parameters. This reduced the Video Random Access Memory (VRAM) requirements from hundreds of gigabytes to under 24GB, the capacity of a standard high-end consumer graphics card.
A Chronology of Technical Milestones
The timeline of local LLM fine-tuning is marked by several pivotal releases that shifted the industry’s direction:
- June 2021: Microsoft researchers introduce LoRA, providing the mathematical foundation for parameter-efficient fine-tuning.
- May 2023: The introduction of QLoRA by University of Washington researchers allows for 4-bit quantization during training, making it possible to fine-tune a 65B parameter model on a single 48GB GPU.
- Late 2023 – Early 2024: The "Library Wars" begin, with tools like Unsloth and LLaMA-Factory emerging to provide higher abstraction layers and massive speed optimizations.
- Mid 2024: Preference optimization techniques like Direct Preference Optimization (DPO) and Generative Reward Profile Optimization (GRPO) move from research papers into production-ready libraries, allowing for better alignment with human values.
Detailed Analysis of the Top 10 Open-Source Libraries
To navigate this rapidly expanding field, it is essential to categorize these tools based on their specific utility, skill requirements, and hardware optimization.

1. Unsloth: The Efficiency Pioneer
Unsloth has gained significant traction by focusing on the "inner loop" of the training process. By rewriting the underlying kernels in OpenAI’s Triton language, Unsloth claims to provide up to 2x faster training speeds and a 70% reduction in VRAM usage compared to standard Hugging Face implementations. It is particularly effective for those working on NVIDIA GPUs (from the T4 to the H100) and provides seamless integration with Google Colab and Kaggle environments.
- Key Advantage: It makes fine-tuning 7B and 8B models viable on 16GB VRAM cards with high throughput.
2. LLaMA-Factory: The Universal Interface
For developers who prefer a comprehensive suite over individual scripts, LLaMA-Factory offers a unified solution. It includes "Llama-Board," a web-based UI that allows users to configure training parameters—such as learning rate, batch size, and dataset formatting—without writing a single line of code. It supports over 100 different model architectures and various training methods, including Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF).
3. DeepSpeed: Enterprise-Grade Scalability
Developed by Microsoft, DeepSpeed is the backbone of large-scale distributed training. Its Zero Redundancy Optimizer (ZeRO) technology is critical for those who have access to multiple GPUs and need to train models that are too large to fit on a single card. While it has a steeper learning curve, it is indispensable for enterprise applications where scalability is the primary concern.

4. PEFT (Parameter-Efficient Fine-Tuning)
As a core library within the Hugging Face ecosystem, PEFT is the industry standard. It provides the fundamental implementations for LoRA, Prefix Tuning, and AdaLoRA. Most other libraries in this list use PEFT as a dependency, making it a "must-know" for intermediate developers who want to understand the mechanics of model adaptation.
5. Axolotl: The Configuration Specialist
Axolotl has become the favorite of the "open-model-maker" community. It relies on YAML configuration files, allowing for highly reproducible training runs. It supports advanced features like "Multipack," which bundles multiple short examples into a single sequence to maximize training efficiency, and integrates deeply with WandB (Weights & Biases) for experiment tracking.
6. TRL (Transformer Reinforcement Learning)
Also a Hugging Face product, TRL focuses on the "alignment" phase of training. After a model is fine-tuned on instructions, it often needs to be aligned with human preferences. TRL provides the tools for DPO, PPO (Proximal Policy Optimization), and the newer GRPO, which was notably used in the development of the DeepSeek-R1 models to achieve reasoning capabilities.

7. torchtune: The PyTorch Native Choice
Released by the Meta PyTorch team, torchtune follows a "no-abstraction" philosophy. It is designed to be easily readable and hackable, using pure PyTorch. This is ideal for researchers who want to modify the training logic itself rather than just adjusting hyperparameters through a wrapper.
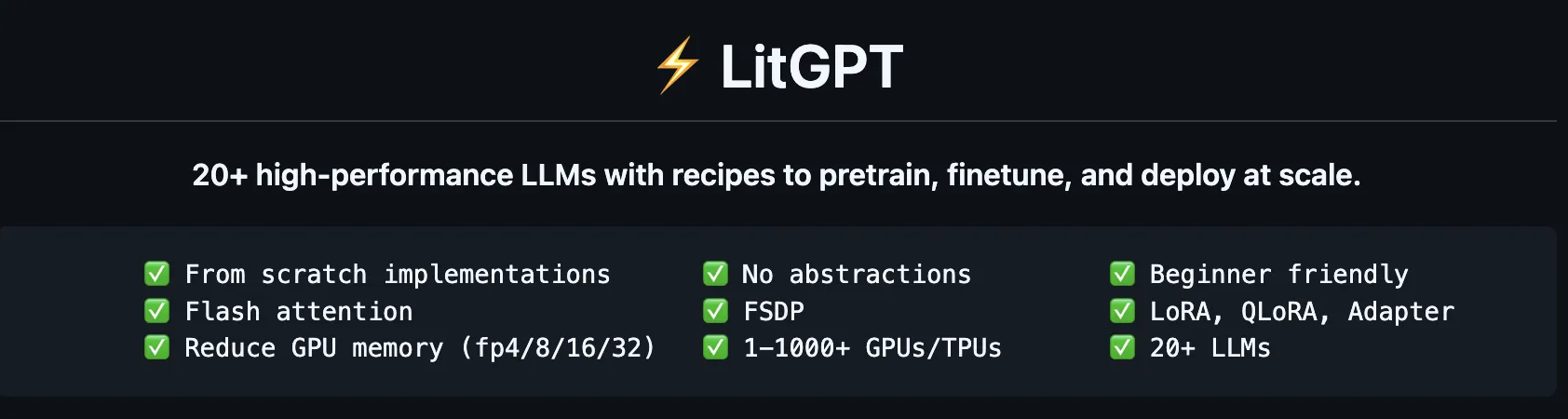
8. LitGPT: Practicality and Transparency
LitGPT, maintained by Lightning AI, offers a collection of highly optimized, clean implementations of the most popular LLMs. It focuses on "from-scratch" implementations that are easy to audit and deploy. It is particularly favored by developers who prioritize code clarity and want to avoid the "bloat" sometimes found in larger frameworks.
9. SWIFT (Scalable Weighted Iterative Fine-Tuning)
Originating from Alibaba’s ModelScope community, SWIFT is a powerhouse for multimodal models. While many libraries focus strictly on text, SWIFT provides robust support for Vision-Language models (like Qwen-VL) and audio models. It is increasingly becoming the go-to for developers in the Asian market and those working with the Qwen ecosystem.

10. AutoTrain Advanced: The No-Code Gateway
Hugging Face’s AutoTrain Advanced is designed for users who need results quickly without diving into the technicalities of the training stack. By simply uploading a CSV or JSONL dataset, users can initiate training runs that automatically handle quantization, formatting, and optimization.
Supporting Data: VRAM Requirements and Performance Metrics
The choice of library often dictates the hardware requirements. Based on industry benchmarks for fine-tuning an 8B parameter model (such as Llama 3):
- Standard Training: Requires ~160GB VRAM (unfeasible for local).
- LoRA (16-bit): Requires ~16-20GB VRAM.
- QLoRA (4-bit): Requires ~7-9GB VRAM.
- Unsloth Optimized QLoRA: Can operate on as little as 6GB VRAM, enabling training on mid-range laptop GPUs.
Industry Implications and Broader Impact
The proliferation of these open-source tools has significant implications for data privacy and corporate strategy. By fine-tuning locally, organizations can ensure that sensitive data—such as proprietary codebases or patient records—never leaves their internal servers. This addresses the primary "privacy leak" concern associated with using commercial APIs like OpenAI’s GPT-4.

Furthermore, the rise of "Vertical AI" is a direct result of these libraries. Instead of one giant model that knows everything, we are seeing a shift toward a "MoE" (Mixture of Experts) approach or a collection of small, highly specialized models. A 7B model fine-tuned on a specific legal dataset often outperforms a general 175B model in that specific domain, while being significantly cheaper to run.
Official Responses and Community Sentiment
The developer community has largely embraced these tools, with GitHub stars for repositories like LLaMA-Factory and Unsloth growing at exponential rates. In recent developer surveys, "ease of setup" and "memory efficiency" were cited as the two most important factors when choosing a fine-tuning library.
Representatives from Hugging Face have noted that the "democratization of fine-tuning is the final piece of the puzzle for open-source AI." By providing the tools to not just run models (inference) but to also improve them (training), the community has created a self-sustaining feedback loop where open-source models are rapidly closing the gap with their proprietary counterparts.
Conclusion: Future Outlook
As we look toward 2025, the focus of these libraries is shifting toward "On-Device" fine-tuning and "Multimodal" optimization. We can expect future iterations of these tools to support training on non-NVIDIA hardware, such as Apple’s M-series chips and specialized AI accelerators from AMD and Intel, with even greater efficiency. The era of the "Local AI Engineer" is firmly established, powered by a robust stack of open-source libraries that continue to push the boundaries of what is possible on a single machine.