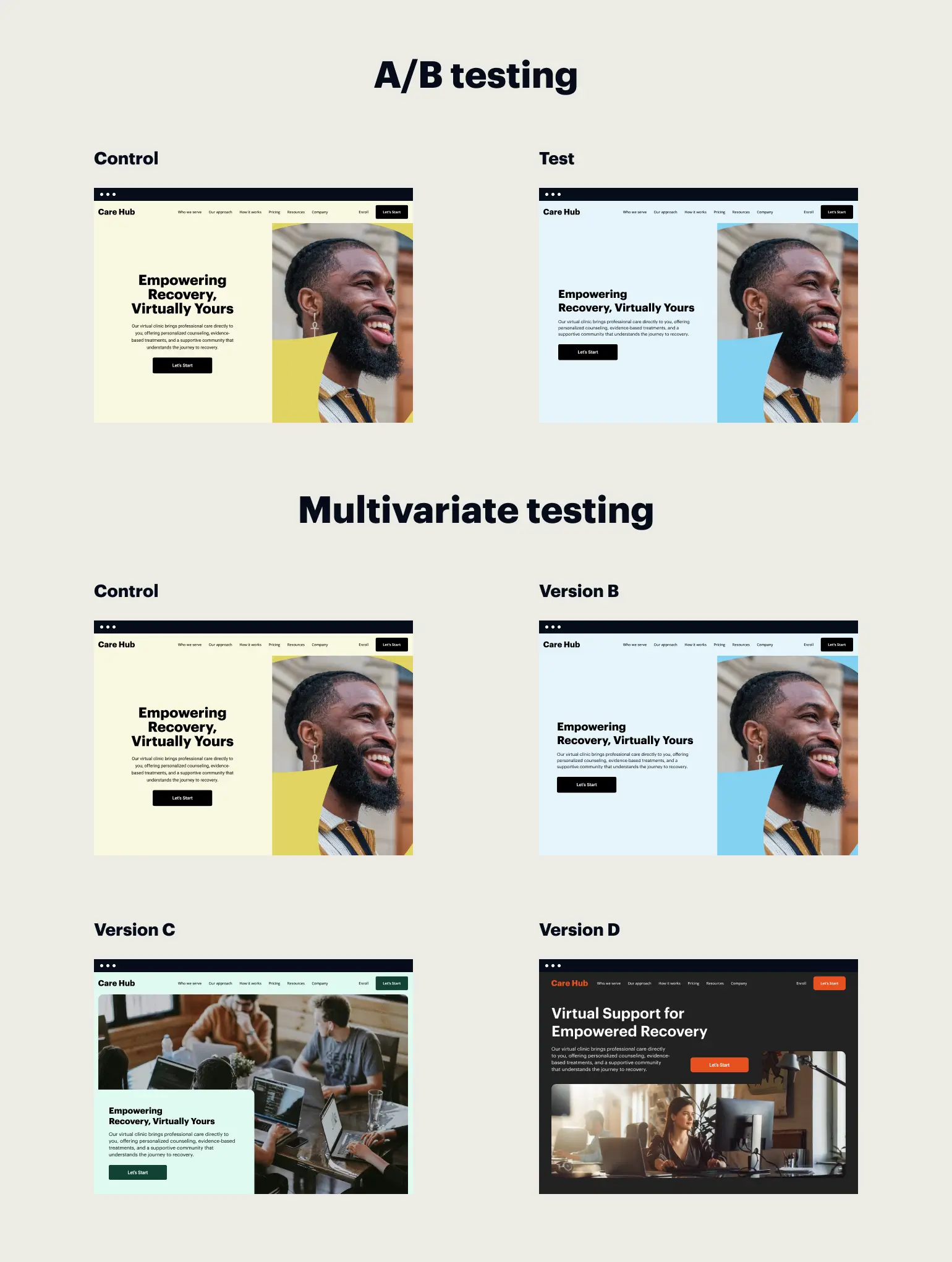
The determination of how long an A/B test should run remains one of the most critical yet misunderstood aspects of digital experimentation and conversion rate optimization (CRO). While the impulse of many marketing teams is to declare a winner as soon as a graph shows a positive trend, experts in the field of data science and user experience emphasize that test duration is not a matter of intuition, but a rigorous calculation involving traffic volume, the minimum detectable effect (MDE), statistical power, and significance thresholds. In an era where data-driven decision-making dictates the allocation of millions of dollars in advertising and development resources, the methodology behind test duration has moved from a peripheral concern to a central pillar of corporate strategy.
The Fundamental Framework of Experimentation Timing
At its core, test duration is defined as the total timeframe required for an experiment to produce a statistically valid result, spanning from the initial traffic split to the final conclusion of the test. In the professional experimentation landscape, this duration serves as a feasibility filter. Before a single line of code is deployed for a new website variant, duration estimates act as a "sanity check" to determine if a hypothesis is worth pursuing. If a mathematical model suggests that a specific test requires six months to reach statistical significance on a low-traffic page, the business must decide whether that insight is worth the opportunity cost of stalling other experiments.

The industry consensus, supported by specialists such as Kateryna Berestneva and Sadie Neve, suggests that a successful test duration is built upon four primary pillars: the baseline conversion rate, the desired minimum detectable effect (MDE), statistical significance (usually set at 95%), and statistical power (usually set at 80%). These metrics ensure that the results observed are not the product of random noise but are representative of true user behavior.
Expert Methodologies in Determining Duration
Professional experimenters utilize varied but complementary approaches to ensure their data remains robust. Kateryna Berestneva, a CRO Manager at SomebodyDigital, advocates for a threshold-based approach. In her methodology, a test should ideally reach a minimum of 100 conversions per variation and maintain at least 95% statistical significance. Berestneva notes that in many practical scenarios, this translates to a window of four to six weeks. This timeframe is not arbitrary; it accounts for the natural ebb and flow of user behavior across different days of the week and pay cycles.
Sadie Neve, Group Digital Experimentation Manager at Rubix, approaches the problem through the lens of "landscape mapping." Before committing to a specific experiment, Neve recommends a comprehensive audit of site-wide traffic volumes and baseline performance. By mapping these variables, teams can design experiments that their current traffic can actually support, rather than setting unrealistic goals for low-traffic segments. This preventive measure ensures that the experimentation backlog is populated only with viable tests, thereby increasing the overall velocity of the optimization program.
Gerda Thomas, co-founder of Koalatative, emphasizes the removal of human bias through the use of pre-test duration calculators. These tools allow teams to input their weekly traffic and current conversion data to generate a fixed timeframe. Thomas argues that once this duration is calculated, the team must commit to it fully. The "NBA game" analogy is frequently cited in this context: one would not leave a basketball game after the first basket is scored and claim to know the final winner; similarly, an A/B test cannot be judged by its early-stage fluctuations.
The Statistical Risks of "Peeking" and Early Termination
One of the most pervasive issues in modern A/B testing is the "peeking problem." This occurs when stakeholders monitor live results and decide to stop a test because a specific variant appears to be winning. Statistically, this is a dangerous practice. Because p-values (the measure of statistical significance) fluctuate naturally throughout the course of an experiment, stopping early based on a "significant" result often leads to false positives.
Ruben de Boer, owner at Conversion Ideas, highlights that the issue is often less about the duration itself and more about the stability of the sample. He advocates for running tests through full business cycles—typically one to four weeks—to ensure that the data accounts for weekend versus weekday behavior. De Boer suggests that it is mathematically superior to run a three-week test with a 3% MDE than a one-week test with a 10% MDE, as the former provides a much higher degree of confidence in the result.
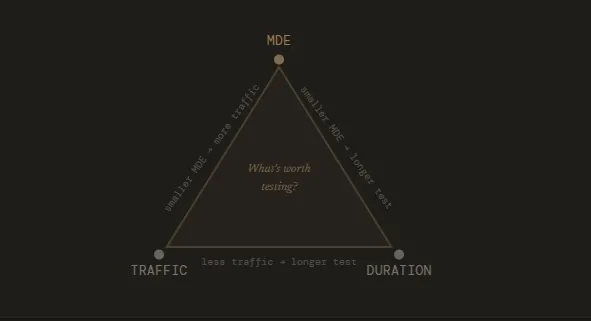
The phenomenon of p-hacking—repeatedly checking data and stopping the moment it looks favorable—further undermines the integrity of an experimentation program. When tests are stopped prematurely, the observed "uplift" is often exaggerated. If these inaccurate results are then used to shape the future product roadmap, the company may invest heavily in features that do not actually provide the expected return on investment.
Chronology of a Standardized Experimentation Cycle
To maintain scientific rigor, most high-performance growth teams follow a strict chronological sequence for their A/B tests:
- Pre-Test Analysis (Days 1-3): Identification of the baseline conversion rate and current traffic levels for the target page.
- Hypothesis and Parameter Setting (Days 4-5): Defining the MDE—the smallest change in conversion rate that the business deems worth the cost of implementation.
- Duration Calculation (Day 6): Using frequentist or Bayesian calculators to determine the exact number of days or weeks required to reach the target sample size.
- The "Dark" Period (Weeks 1-4): The test is launched. Experts recommend avoiding the "peeking" of results during this phase to prevent emotional bias.
- Data Stabilization and Review (Final Week): The test reaches its pre-determined sample size. Only now are the results analyzed for significance.
- Implementation or Iteration (Post-Test): If a winner is found, it is moved to production. If the result is inconclusive, the hypothesis is refined for a future cycle.
When Early Termination is Justified
While the general rule is to never stop a test early, there are specific "fringe" scenarios where immediate intervention is necessary. Ioana Iordache, a Product Growth Consultant, identifies three primary exceptions:

- Technical Failure: If the tracking pixels are broken or data is not being recorded correctly, the test is invalid and should be stopped immediately.
- Severe User Experience Regression: If a variant causes a catastrophic drop in revenue or a surge in error messages (e.g., the checkout button stops working), the test must be halted to protect the business’s bottom line.
- The "Winner-Stay" Scenario in High-Risk Events: In rare cases of extreme seasonality where a variant is clearly causing massive brand damage, human intervention overrides statistical purity.
Outside of these emergencies, the "acid test" of a professional experimenter is their ability to let a test run its course, even when early data looks tempting.
Broader Implications for Digital Strategy
The discipline of calculating test duration has significant implications for how companies manage their product backlogs. Every test that runs represents a choice not to run something else. Therefore, duration directly controls the "throughput" of an experimentation program. If a team can refine their duration estimates and focus on higher-traffic areas, they can increase the number of test cycles per quarter.
Furthermore, accurate duration planning builds organizational trust. When a CRO team can present a result and explain the rigorous statistical framework that supports it—including why they waited four weeks despite an early lead—leadership is more likely to trust the data. This trust is the foundation of a "test-and-learn" culture, where decisions are made based on evidence rather than the "Highest Paid Person’s Opinion" (HiPPO).
Ultimately, the goal of A/B testing is not just to find "winners," but to generate reliable insights that can be built upon. By adhering to calculated test durations, companies ensure they are not just chasing ghosts in the data, but are instead identifying true shifts in user behavior that will drive long-term growth and sustainable competitive advantage in an increasingly crowded digital marketplace.