The release of Claude Opus 4.7 comes at a time when the AI industry is moving beyond simple text generation toward "agentic" workflows—systems that can plan, execute, and troubleshoot tasks without constant human intervention. For developers and industry professionals, the update represents a significant leap in advanced software engineering, financial modeling, and legal analysis. Anthropic’s strategy appears focused on addressing the "supervision fatigue" often experienced by users of earlier AI models, where the time saved in generation was frequently lost to the time required for rigorous fact-checking and error correction.
The Evolution of the Claude Ecosystem: A Brief Chronology
To understand the significance of Claude Opus 4.7, it is necessary to view it within the context of Anthropic’s rapid development cycle. Founded in 2021 by former OpenAI executives, Anthropic has consistently prioritized "Constitutional AI," a framework designed to ensure AI systems are helpful, honest, and harmless. The Claude 3 family, introduced in early 2024, established the brand as a formidable competitor to OpenAI’s GPT series and Google’s Gemini.
Following the success of Claude 3.5 Sonnet, which became a favorite among programmers for its speed and logic, the transition to the 4.0 series marked a shift toward "frontier-scale" reasoning. Claude Opus 4.6 was released to critical acclaim for its nuanced understanding of context, yet users still identified gaps in long-term project management and high-resolution visual processing. The introduction of Opus 4.7 addresses these specific pain points, integrating feedback from enterprise partners who required a model capable of handling "the hardest coding work" with minimal oversight. This version marks the first time a Claude model has been specifically optimized for "self-verification," a feature that allows the AI to double-check its own logic before presenting a final answer.
Advanced Software Engineering and Autonomous Problem Solving
The most substantial gains in Claude Opus 4.7 are found in the domain of software engineering. Unlike traditional code generators that provide snippets or line-by-line suggestions, Opus 4.7 is architected to manage entire repositories and complex, multi-file projects. Anthropic describes the model as being built for "the most difficult tasks," a claim supported by its performance on specialized benchmarks.
One of the defining features of Opus 4.7 is its "rigor and consistency" in long-term projects. In practical terms, this means the model can maintain the logic of a large-scale application across multiple sessions without losing track of architectural requirements. Developers have reported a marked decrease in the need for manual supervision. This is largely due to the model’s new ability to verify its own outputs. Before reporting back to the user, Opus 4.7 runs internal checks to identify potential bugs or logic flaws, acting as both the developer and the quality assurance (QA) engineer.
Furthermore, the model’s adherence to complex, multi-layered instructions has been sharpened. In previous versions, a model might ignore a specific constraint when dealing with a massive prompt; Opus 4.7 demonstrates a more literal and precise following of guidelines, ensuring that technical specifications are met even in highly dense documentation.
High-Resolution Vision and Data Extraction
While text reasoning is the core of the LLM experience, visual capabilities have become increasingly vital for professional workflows. Claude Opus 4.7 introduces a major upgrade in vision, supporting images with resolutions up to 2,576 pixels on the long edge, or approximately 3.75 megapixels. This is more than triple the resolution capacity of previous Claude models.

The implications for professional sectors are vast. In finance and legal industries, documents often contain dense screenshots of spreadsheets, complex flowcharts, and intricate diagrams. Standard AI models frequently struggle with these high-density visual inputs, often misreading small numbers or failing to grasp the relationship between elements in a diagram. Opus 4.7’s high-resolution capabilities allow for precise data extraction from these sources. For example, a financial analyst can upload a high-resolution screenshot of a complex balance sheet, and the model can accurately interpret every line item, despite small fonts or crowded formatting. This improvement extends to user interface (UI) design, where the model can now analyze detailed mockups to suggest code implementations with much higher accuracy than its predecessors.
Memory Management and Context Retention
A recurring challenge in AI interaction is the "forgetting" problem, where a model loses track of important details during a long, multi-session conversation. Anthropic has addressed this in Opus 4.7 by improving file system-based memory. This allows the model to remember and retrieve important notes across extended work periods.
This enhanced memory structure is particularly beneficial for research and development teams. When starting a new task within an ongoing project, the user needs to provide less "up-front context" because the model retains a more robust understanding of the previous sessions’ goals and constraints. This effectively turns the AI into a more persistent partner that grows more familiar with a user’s specific project over time, rather than a stateless tool that resets after every interaction.
Benchmark Performance: A Comparative Analysis
In the competitive landscape of AI, benchmarks serve as the primary metric for progress. Anthropic’s internal and external testing shows that Claude Opus 4.7 is a dominant force in real-world agentic work.
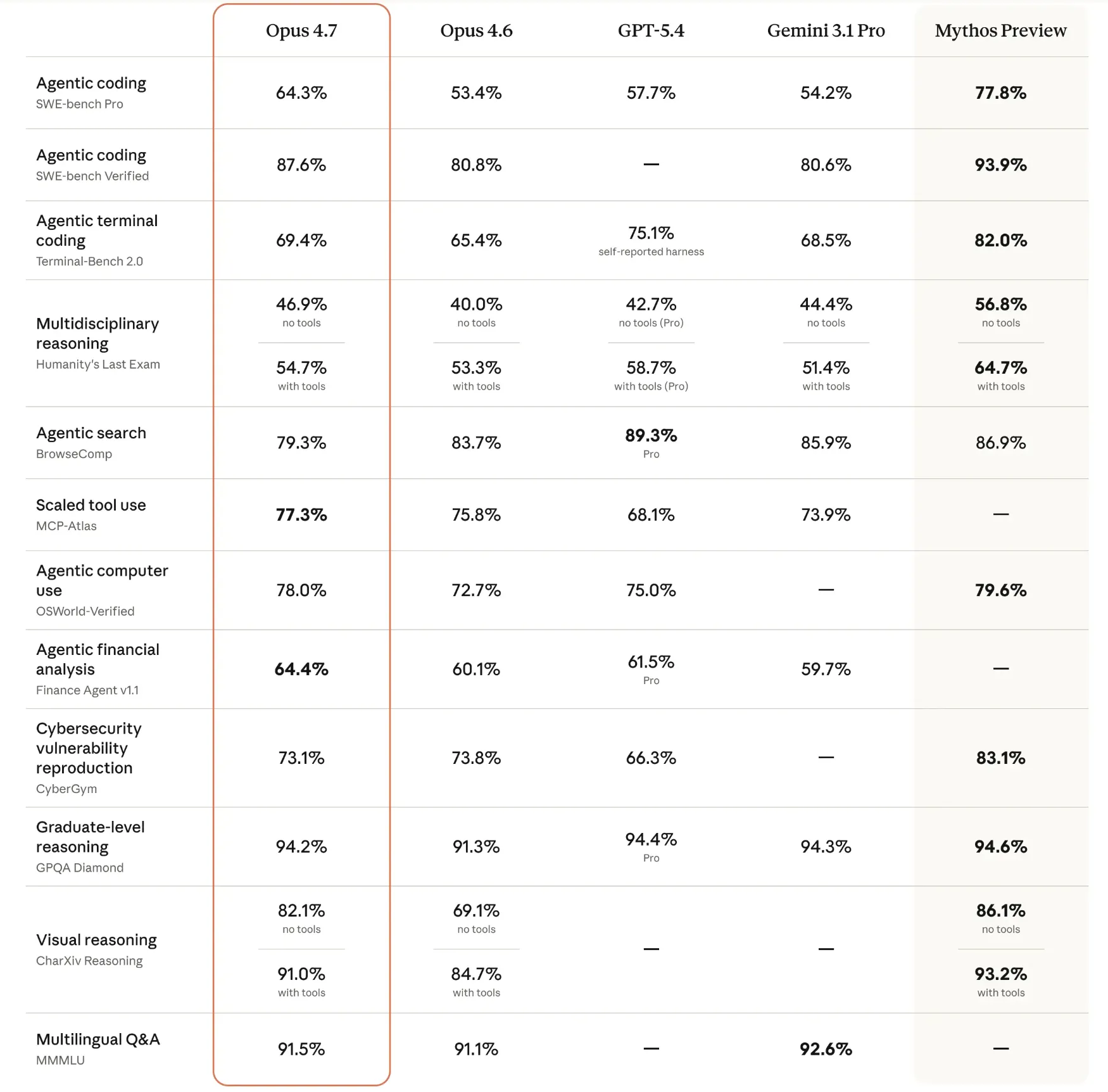
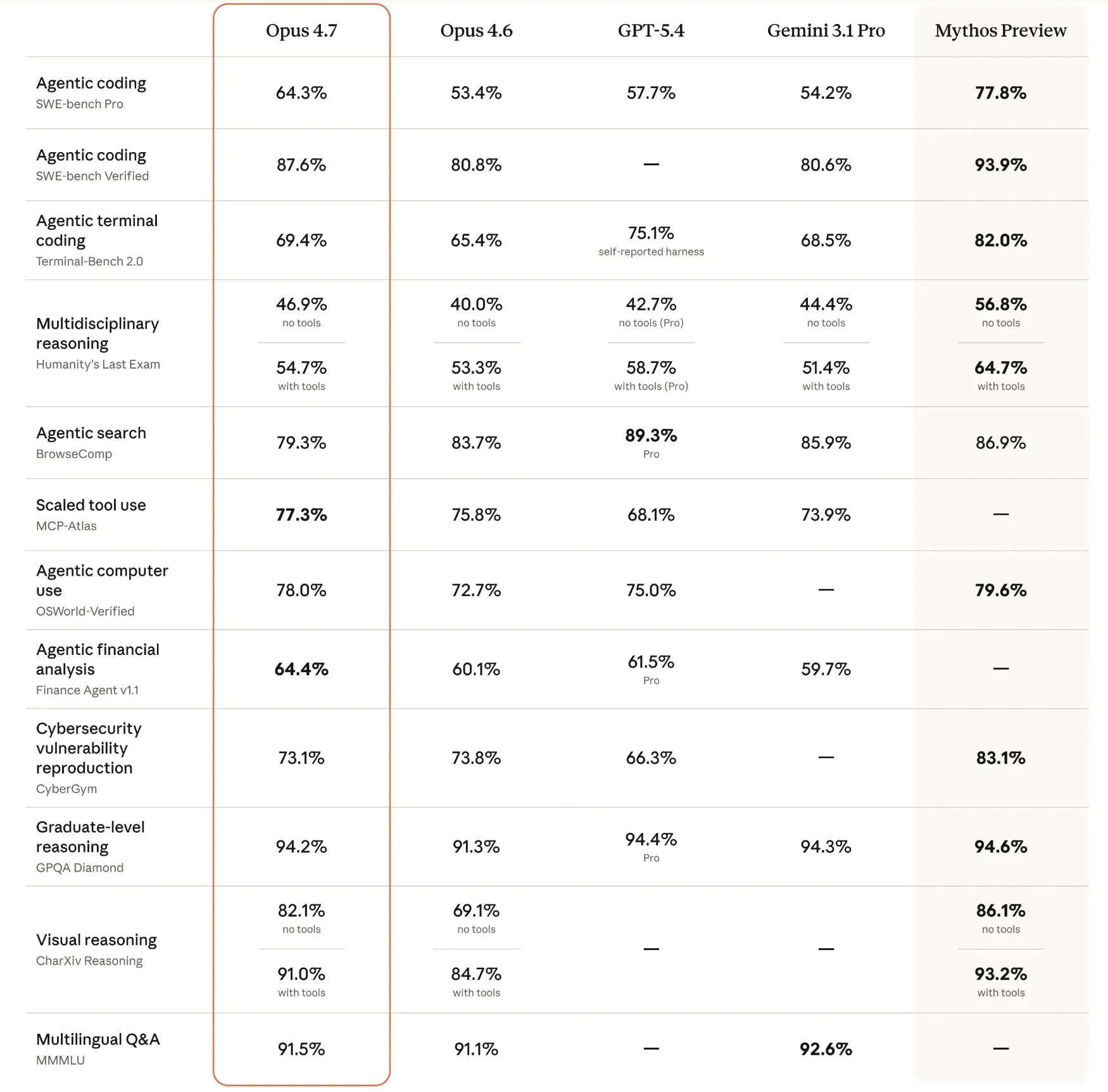
On the SWE-bench Pro, a rigorous test for software engineering capabilities, Opus 4.7 posted a score of 64.3%. Even more impressive was its 87.6% score on SWE-bench Verified. These figures place it ahead of current industry leaders like GPT-5.4 and Gemini 3.1 Pro in specific coding categories. In terminal-based workflows, evaluated via Terminal-Bench 2.0, the model scored 69.4%. While this was slightly behind GPT-5.4’s self-reported 75.1%, it represents a massive jump from the 4.6 version.
Beyond coding, the model’s reasoning capabilities were tested on the GPQA Diamond benchmark (a test of graduate-level science questions), where it scored 94.2%. On the MMMU (Massive Multi-discipline Multimodal Understanding) benchmark, it achieved 91.5%, indicating high proficiency in multilingual and visual Q&A.
However, the data also highlights areas where the competition remains fierce. In agentic web browsing (BrowseComp), GPT-5.4 maintains a lead with 89.3%. On "Humanity’s Last Exam," a benchmark designed to test the limits of AI knowledge, Opus 4.7 scored 54.7% with tools, trailing behind the Mythos Preview model. These results suggest that while Opus 4.7 is a premier choice for coding and structured reasoning, the market for general-purpose AI remains highly contested.
Safety and Security: Project Glasswing
Anthropic’s identity is deeply rooted in safety, and the launch of Opus 4.7 coincides with the debut of "Project Glasswing." This initiative is designed to ensure that as models become more autonomous and "agentic," they do not inadvertently facilitate harm.
Opus 4.7 is the first model to feature a built-in high-risk cybersecurity request detector. This system is designed to identify and block prompts that involve hacking, vulnerability exploitation, or unauthorized system analysis. To balance this restriction, Anthropic has launched the Cyber Verification Program. This program allows vetted, legitimate security professionals to access the model’s full capabilities for defensive purposes, such as hardening codebases or identifying vulnerabilities in their own systems before they can be exploited.
This proactive approach to safety reflects a broader industry trend toward "red-teaming" AI models. By integrating these safeguards into the core architecture of Opus 4.7, Anthropic aims to mitigate the risks associated with a model that is capable of writing and executing sophisticated code autonomously.
Industry Implications and Professional Use Cases
The release of Claude Opus 4.7 is expected to accelerate AI adoption in sectors that were previously hesitant due to accuracy concerns.
- Finance: The model’s ability to produce "rigorous analyses and models" makes it a viable assistant for quantitative analysts. Its tighter integration across tasks allows it to take raw data from a PDF, process it through a complex financial model, and then generate a professional presentation—all with minimal human correction.
- Legal: In legal discovery and contract analysis, the high-resolution vision and improved memory allow the model to track inconsistencies across thousands of pages of documentation, a task that typically requires hundreds of billable hours from junior associates.
- Research and Development: For scientists and researchers, the model’s high scores on the GPQA Diamond benchmark suggest it can act as a high-level peer reviewer, helping to synthesize complex data and suggest new avenues for investigation based on existing literature.
Availability and Integration
Anthropic has ensured that Claude Opus 4.7 is accessible across all major platforms immediately upon launch. It is available via the standard Claude.ai interface for individual and Team subscribers. For enterprise users, the model is integrated into the Claude API and is available through major cloud providers, including Amazon Bedrock and Google Cloud’s Vertex AI.
In terms of pricing, Anthropic has maintained the same structure as the previous Opus 4.6 version. However, the company has noted that a new tokenizer has been implemented. This may result in a slight increase in token counts for certain inputs, though the increased efficiency of the model’s reasoning is expected to offset any minor cost variations for most professional users.
Conclusion: Toward a New Paradigm of AI Collaboration
Claude Opus 4.7 represents a milestone in the evolution of artificial intelligence. It moves the needle from "AI as a tool" to "AI as a partner." By focusing on the attributes that professionals value most—accuracy, self-verification, high-resolution visual processing, and safety—Anthropic has created a model that is uniquely suited for the complexities of modern knowledge work.
While the competitive landscape remains intense, with OpenAI and Google continuously updating their own frontier models, Anthropic’s emphasis on reliability and "Project Glasswing" safety protocols provides a distinct value proposition for the enterprise. As the technology continues to mature, the success of models like Opus 4.7 will likely be measured not just by their benchmark scores, but by their ability to seamlessly integrate into human workflows, reducing the burden of supervision and allowing professionals to focus on higher-level strategic decision-making.