The global landscape of artificial intelligence is currently undergoing a seismic shift in accessibility, driven primarily by a collapse in the cost of large language model inference. Only two years ago, the deployment of advanced AI models was a significant capital expenditure, forcing developers and enterprises to meticulously calculate the necessity of every query. Today, those same high-performance models have become so cost-effective that their usage is increasingly treated as a background utility, similar to electricity or bandwidth. This transformation is not merely the result of general technological progress but is rooted in a fundamental restructuring of "token economics"—the methodology by which AI systems allocate and spend computational resources.
The Token as the Fundamental Economic Unit
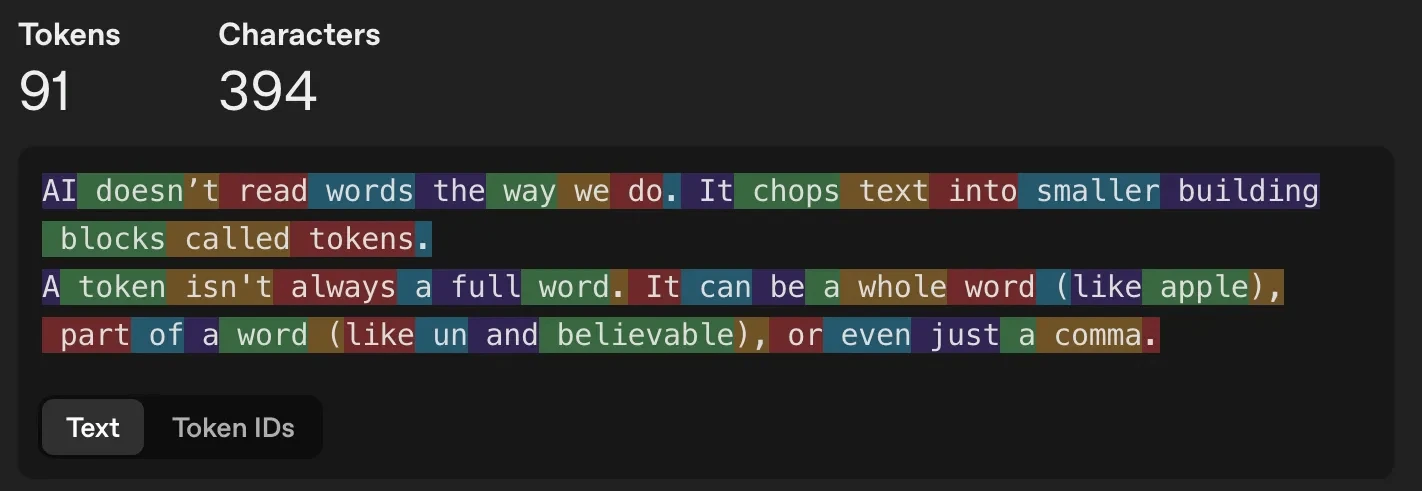
To understand the plummeting costs of artificial intelligence, it is necessary to examine the "token," the atomic unit of modern natural language processing. Large Language Models (LLMs) do not process human language in the form of strings or whole words. Instead, they decompose text into smaller building blocks known as tokens. A token can represent a single word, a prefix such as "un-," a suffix like "-ing," or even individual punctuation marks and whitespace.
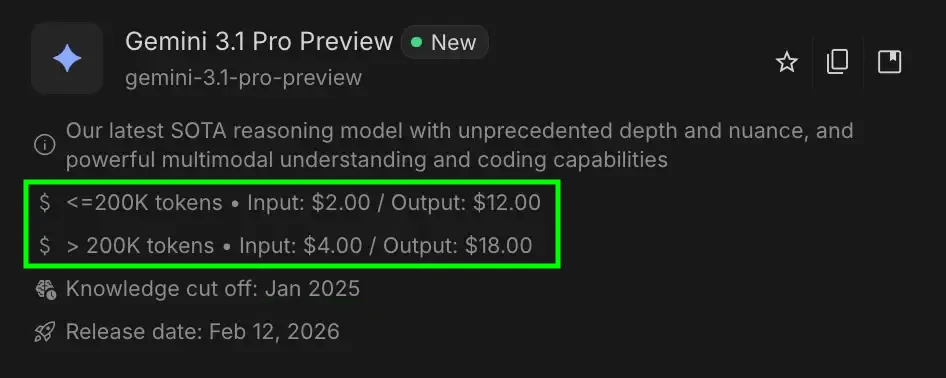
The economic relationship of an AI interaction is defined by a specific mathematical formula: the total cost of a query is the sum of the input tokens and output tokens, each multiplied by their respective rates per million units. For example, a model like Gemini 3.1 Pro might be priced at a specific rate for processing a 50,000-token prompt and a higher rate for generating a 2,000-token response. Because every token generated requires a discrete amount of floating-point operations (FLOPs), the ability to reduce the cost of AI has depended on two primary levers: reducing the amount of computation required per token and making that computation cheaper to execute on a hardware level.
The Shift Toward Computational Efficiency
The initial wave of AI development was characterized by a "brute force" approach, where models were scaled to hundreds of billions of parameters, and every request—regardless of complexity—utilized the entire weight of the neural network. Industry analysts now recognize this period as one of extreme computational waste. Over the last 18 months, the industry has pivoted toward several algorithmic breakthroughs designed to minimize unnecessary work.
Model Quantization and Precision Reduction
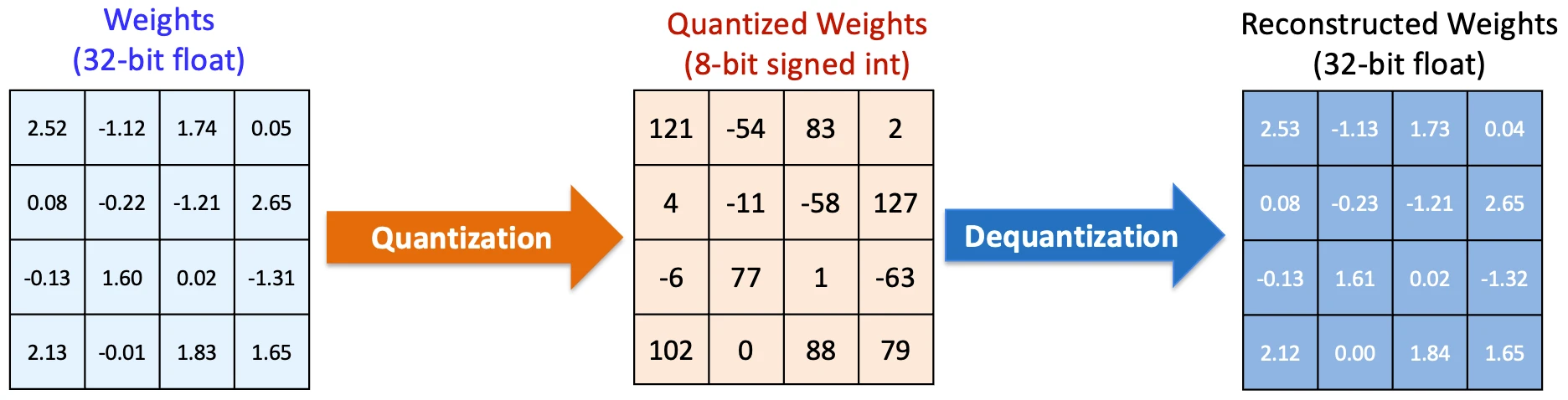
One of the most effective methods for reducing per-token costs is quantization. In their raw state, AI models often use high-precision 16-bit or 32-bit floating-point numbers to represent weights and perform calculations. However, research has demonstrated that reducing this precision to 8-bit, 4-bit, or even lower does not significantly degrade the quality of the output for most general-purpose tasks.
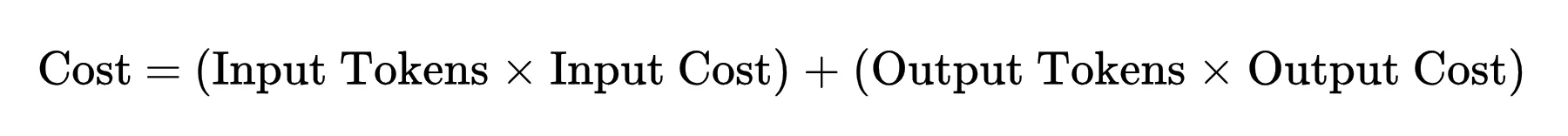
By utilizing lower-precision math, the computational structure remains the same, but the individual operations become significantly lighter. This reduction compounds across the thousands of operations required for every single token, leading to a meaningful drop in the energy and time required for inference. Furthermore, modern quantization techniques utilize constants such as scales and zero points for data blocks, allowing the system to de-quantize data only when absolutely necessary, thereby saving memory bandwidth.
The Rise of Mixture of Experts (MoE) Architecture
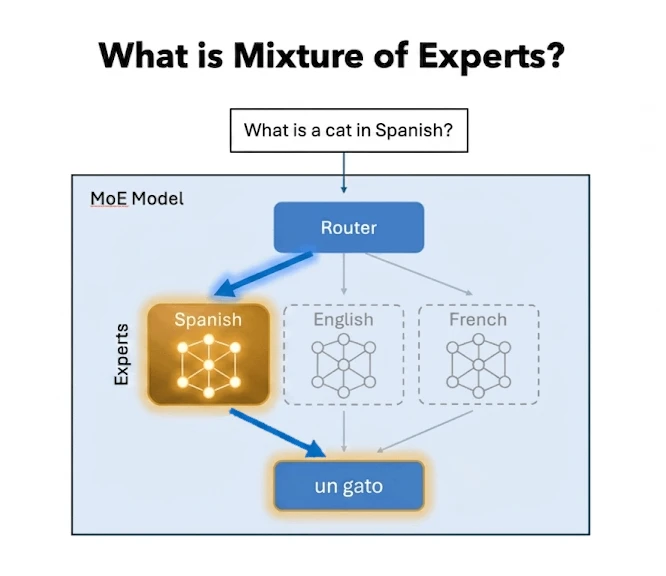
Perhaps the most significant architectural shift in the pursuit of efficiency is the Mixture of Experts (MoE) model. In a traditional "dense" model, every parameter is activated for every token generated. In an MoE architecture, the model is subdivided into specialized "expert" nodes. A routing mechanism analyzes the incoming prompt and activates only the relevant experts.
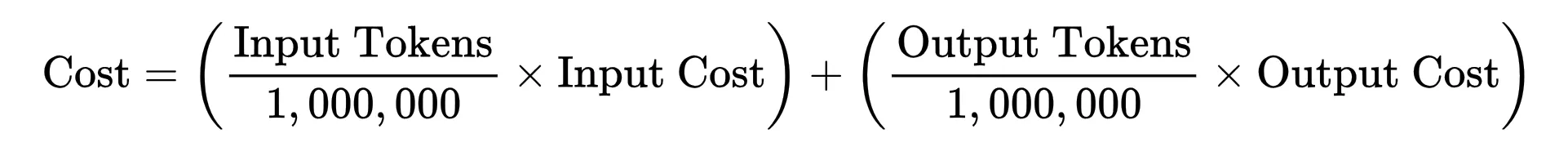
For instance, if a user asks a question in Spanish, the router activates the nodes specialized in Spanish linguistics while leaving the rest of the model idle. This allows for a model that possesses the broad intelligence of a massive network while only utilizing a fraction of its total parameters for any given task. This "sparse" activation directly reduces the compute-per-token cost without sacrificing the overall sophistication of the system.
Small Language Models (SLMs) and Distillation
The industry has also seen a resurgence in Small Language Models (SLMs). Developers have observed that many enterprise tasks—such as text summarization, data formatting, or basic customer service—do not require the full reasoning capabilities of a frontier model like GPT-4 or Gemini Ultra. By deploying smaller, purpose-built models, organizations can achieve the same results at a fraction of the cost.
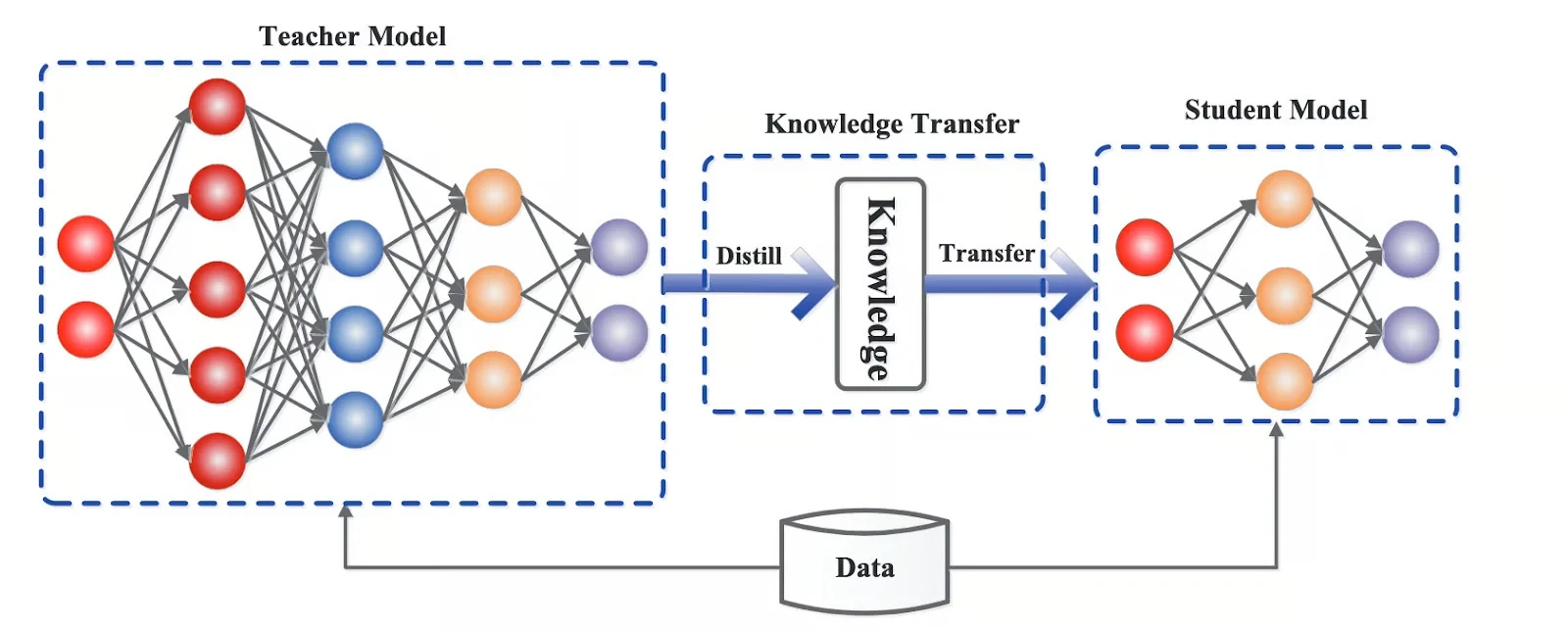
This trend is supported by "distillation," a process where a massive "teacher" model is used to train a smaller "student" model. The student model learns to mimic the teacher’s behavior and reasoning patterns but in a highly compressed form. Distillation allows for the creation of lightweight models that retain high performance in specific domains while being significantly cheaper to serve.
Operational Optimizations and KV Caching
Beyond the architecture of the models themselves, the way systems handle data during a conversation has been optimized. In any AI interaction, there is a significant amount of redundant work. In a multi-turn conversation, the model often re-processes the same initial prompt multiple times.
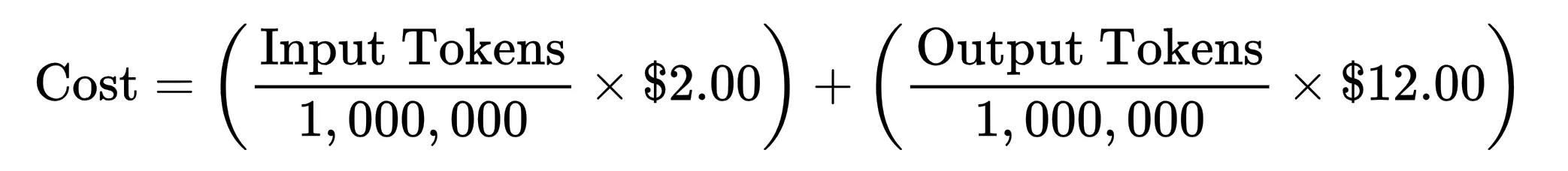
To solve this, modern systems utilize Key-Value (KV) Caching. This technique stores the intermediate mathematical states of previous tokens in a conversation, allowing the model to "pick up where it left off" rather than recalculating the entire context window for every new response. Advanced implementations, such as Google’s TurboQuant, offer extreme compression of these caches, leading to higher memory efficiency and lower costs for long-form interactions.
Hardware Evolution and the Role of Specialized Silicon
While algorithmic efficiency has reduced the workload, hardware evolution has made the remaining workload cheaper to execute. The transition from general-purpose CPUs to GPUs (Graphics Processing Units) was the first step, but the current era is defined by the rise of TPUs (Tensor Processing Units) and AI-specific ASICs (Application-Specific Integrated Circuits).
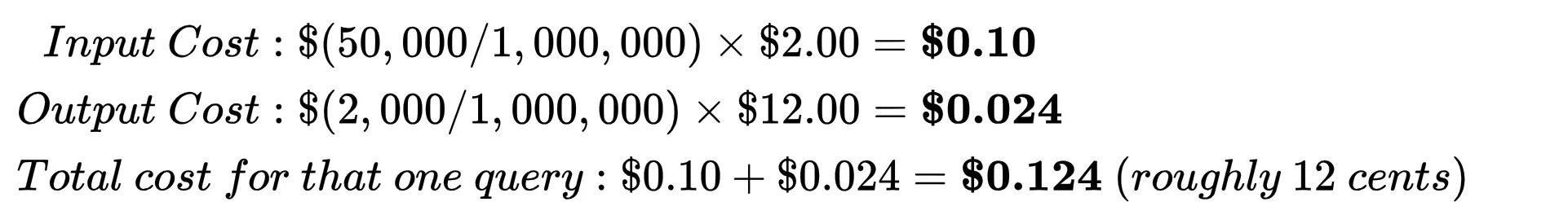
Companies like NVIDIA, Google, and Amazon have developed chips specifically engineered for the large-scale matrix multiplications that define AI inference. These specialized chips provide:
- Higher Throughput: The ability to process more tokens per second.
- Improved Energy Efficiency: Lowering the electricity cost per operation.
- Optimized Memory Bandwidth: Reducing the bottleneck of moving data between the processor and memory.
This hardware does not just make existing models faster; it amplifies the benefits of quantization and MoE architectures, creating a synergistic effect that drives prices down further.
Chronology of the AI Price War
The collapse in token pricing can be tracked through a series of competitive releases over the last two years:
- Early 2023: Frontier models were priced at roughly $60 per million tokens for high-end reasoning tasks.
- Late 2023: The introduction of "Turbo" and "Flash" variants saw prices drop by 50% or more as providers optimized their inference stacks.
- 2024: The "Race to Zero" began in earnest. Models like GPT-4o-mini and Gemini 1.5 Flash entered the market with prices as low as $0.15 per million input tokens—a 99% reduction from the peak prices of the previous year.
This timeline suggests that the "Moore’s Law" equivalent for AI tokens is moving at a significantly faster pace than traditional semiconductor advancement, doubling in efficiency every few months rather than every two years.
Broader Impact and Industry Implications
The implications of cheap AI tokens are profound for the global economy. As the cost of intelligence approaches zero, the barrier to entry for AI-integrated software vanishes. This has led to the rise of "agentic" workflows, where AI systems perform hundreds or thousands of background tasks—researching, coding, and debugging—without human intervention. Such workflows were economically impossible when tokens were expensive.
However, this transition also presents challenges. While the per-token cost is falling, the total volume of tokens being processed is exploding. This has led to concerns regarding the environmental impact of massive data centers and the sustainability of the "free tier" models offered by major tech firms. Industry analysts suggest that we are moving toward a tiered economy where "commodity intelligence" is nearly free, while "frontier reasoning"—the ability to solve novel, complex scientific problems—remains a premium service.

Conclusion
The rapid decline in AI costs is a multifaceted phenomenon. It is the result of a shift from wasteful, dense computation to efficient, sparse, and quantized architectures. When combined with specialized hardware and clever caching techniques, the result is a technological environment where AI is no longer a luxury for the few, but a utility for the many. As the industry continues to refine token economics, the focus is shifting from making AI possible to making it ubiquitous, invisible, and essential to the fabric of modern digital life.
Frequently Asked Questions
Q: Why is the price of AI calculated in "millions of tokens"?
A: Because individual tokens are so cheap, pricing them by the unit would result in fractions of a cent that are difficult to track. Using "per million" provides a standard metric for comparing the efficiency of different models.
Q: Does cheaper AI mean lower quality?
A: Not necessarily. While "Flash" or "Mini" models are optimized for speed and cost, they often outperform the massive models of just a year ago due to better training data and distillation techniques.
Q: How does specialized hardware lower my subscription costs?
A: Specialized hardware reduces the electricity and cooling costs for the companies hosting the AI. When their operational expenses drop, they can lower prices to remain competitive in a crowded market.