The discipline of digital marketing has long sought to align itself with the rigors of hard science, positioning A/B testing as the ultimate expression of the scientific method in a commercial context. At its core, an A/B experiment functions as a randomized controlled trial, structurally identical to the protocols used in clinical medicine, genetics, and particle physics. However, a growing body of evidence suggests that the practical application of these tests in the corporate world is lagging behind modern statistical standards by nearly half a century. While the tools for data collection have evolved, the frameworks used to interpret that data remain rooted in "fixed-sample" frequentist statistics that were never designed for the high-velocity, real-time environment of the internet. This discrepancy has led to a crisis of reliability, where many practitioners are unknowingly basing multi-million dollar decisions on illusory findings.
The Foundational Crisis in Statistical Significance
In the current landscape of Conversion Rate Optimization (CRO), the term "statistical significance" is frequently used but rarely understood in its full mathematical context. Most A/B testing literature relies on classical significance tests, such as the Student’s T-test, without acknowledging their most critical constraint: the requirement to fix the sample size in advance.
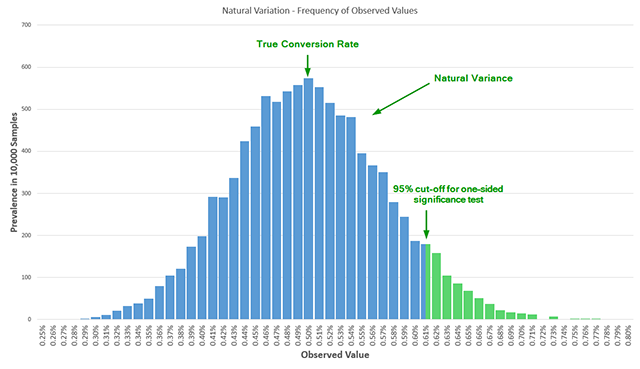
A statistical significance test is essentially an estimation of probability. It measures the likelihood of observing a specific result—or one more extreme—assuming that there is no actual difference between the control and the variant. This "null hypothesis" assumes that any observed lift is merely the result of natural variance in the data. For instance, if a marketer observes a conversion rate of 0.62% in a variant against a 0.50% control, the test calculates whether that 0.12% gap is a genuine effect or a statistical "hiccup."
The mathematical integrity of these models relies on a "single point in time" evaluation. If a practitioner determines that 40,000 users are required for a robust result, the test must only be analyzed once that 40,000th user has been recorded. However, the reality of digital marketing is characterized by constant monitoring. Stakeholders often view live dashboards daily, leading to a phenomenon known as "data peeking" or data-driven optional stopping.
The dangers of data peeking are profound. When a test is monitored continuously, the probability of a false positive—declaring a winner where none exists—inflates rapidly. Research dating back to 1969 has demonstrated that peeking at the results just five times during a test can increase the actual error rate to more than triple the reported nominal error. If a marketer peeks ten times, the error probability becomes five times larger than what the software reports. This "Garbage In, Garbage Out" (GIGO) cycle means that many "winning" variants implemented by companies are actually no better than the originals, leading to stagnant growth despite seemingly positive test results.
The Neglected Variable: Statistical Power
While significance focuses on avoiding false positives (Type I errors), statistical power is concerned with avoiding false negatives (Type II errors). Statistical power is the probability that a test will detect a true lift of a certain magnitude if it actually exists. Despite its importance, a comprehensive review of seven influential A/B testing books published between 2008 and 2014 found that only one mentioned power in a proper context. The rest ignored the concept entirely.
Running an underpowered test is an exercise in resource depletion. If a test lacks the sensitivity to detect a 5% improvement, a variant that actually provides that improvement may be discarded as a "failure." This leads to "false negatives," where potentially transformative changes are abandoned because the test was not designed with enough "reach" to validate them.
Power is intrinsically linked to sample size. To design a valid test, a practitioner must balance four variables: the historical baseline conversion rate, the desired significance threshold (usually 95%), the desired power (often 80% or 90%), and the Minimum Detectable Effect (MDE). Many free online calculators default to a power of 50%, which is essentially a coin toss. When marketers begin to use professional-grade power calculations, they often find that the required sample sizes are much larger than anticipated, forcing a difficult choice between the duration of the test and the certainty of the results.
Inefficiency and the Economic Cost of Classical Testing
Classical statistical methods, while effective in controlled environments like agricultural plots or laboratory settings, are often inefficient in the volatile world of e-commerce. In fields such as biostatistics and medical science, these older methods have been replaced by sequential testing because of the ethical and financial stakes involved.
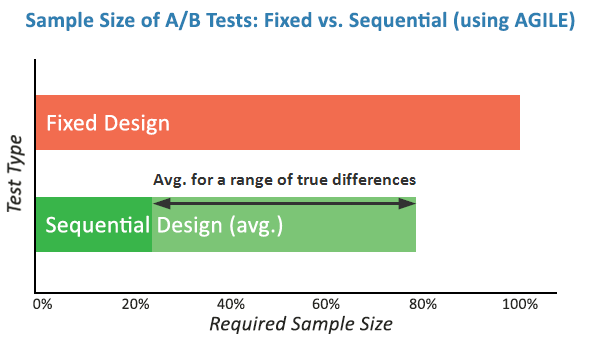
In a classical A/B test, if a variant is performing exceptionally well—or disastrously poorly—the practitioner is technically forbidden from stopping the test early without compromising the data. For example, if a test is planned for 88,000 users to detect a 10% lift, but the actual lift is 15%, the test could theoretically have reached a valid conclusion with only 40,000 users. In the classical model, the remaining 48,000 users represent a massive opportunity cost; the company is losing time and potential revenue by continuing a test that has already "won."
Conversely, if a new website feature is causing a 20% drop in conversions, a fixed-sample test requires the company to continue showing that "loser" to thousands of additional users just to satisfy the original sample size requirement. This lack of flexibility creates a tension between statistical rigor and business survival.
The AGILE Statistical Method: A New Paradigm
To bridge the gap between scientific accuracy and business agility, the "AGILE" statistical approach has been proposed as a solution inspired by group sequential trials in clinical medicine. This framework, detailed in recent industry white papers, introduces several innovations to the standard testing workflow:
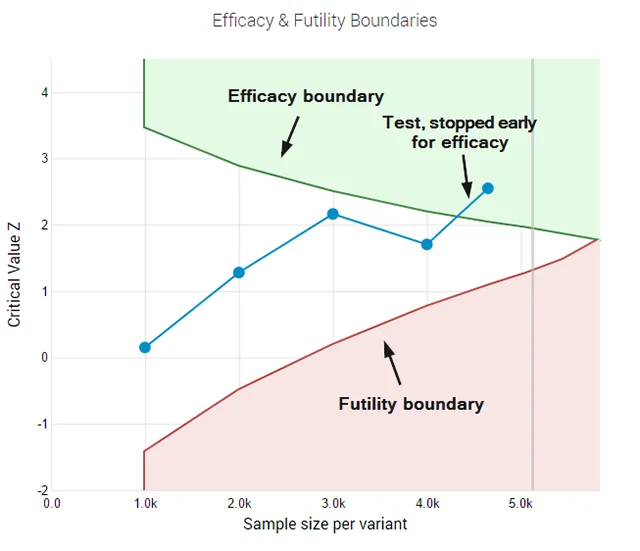
- Interim Analysis with Error-Spending Functions: AGILE allows for multiple looks at the data throughout the test’s duration. It uses mathematical "error-spending functions" to adjust the significance threshold at each look. This ensures that the overall false positive rate remains controlled (e.g., at 5%) even if the data is checked daily.
- Early Stopping for Efficacy: If a variant shows a massive, undeniable improvement early on, the AGILE method provides a mathematically sound way to "call" the test early. This allows companies to implement winners faster and move on to the next experiment.
- Futility Stopping Rules: Perhaps the most significant addition is the ability to stop a test for "futility." If the data shows that a variant has almost no chance of reaching significance, the test can be terminated early. This "fail fast" mentality prevents the wasting of traffic on stagnant ideas.
- Mandatory Power Consideration: Under the AGILE framework, statistical power is not an afterthought but a foundational component of the test design, ensuring that every experiment has a high probability of success from the outset.
Chronology of Statistical Evolution in Experimentation
The transition toward more sophisticated testing reflects a broader timeline of mathematical maturation:
- 1920s–1930s: Ronald Fisher and others develop the foundations of frequentist statistics for agriculture.
- 1969: Peter Armitage and others publish landmark papers on the "peeking" problem in clinical trials, warning of inflated error rates.
- 1970s–1980s: Medical researchers develop sequential analysis and error-spending functions to allow for ethical interim monitoring of life-saving drugs.
- 2000s: A/B testing becomes a staple of digital marketing, but relies largely on the simplified 1930s-era models.
- 2014–2017: Industry critiques highlight the "reproducibility crisis" in CRO, leading to the development of the AGILE method and a shift toward Bayesian alternatives.
Broader Impact and Industry Implications
The shift toward AGILE and other modern statistical methods represents a "coming of age" for the digital marketing industry. Simulations of the AGILE method have shown efficiency gains ranging from 20% to 80% depending on the true lift of the variant. For a high-traffic e-commerce site, this could mean the difference between running 10 tests a year and running 50.
Furthermore, the adoption of these methods addresses the psychological pressures of the workplace. By providing a framework that allows for "peeking" without the penalty of false results, AGILE aligns statistical theory with human behavior. Marketing teams no longer have to choose between being "good scientists" and "good business partners."
As the digital landscape becomes increasingly competitive, the companies that thrive will be those that can distinguish between genuine growth and statistical noise. The move away from "Garbage In, Garbage Out" toward rigorous, flexible, and powerful statistical models like AGILE is not merely a technical upgrade—it is an economic necessity for the modern enterprise. By integrating clinical-grade rigor into the marketing stack, organizations can finally realize the full potential of the randomized controlled trial as a driver of sustainable, data-backed innovation.