The landscape of professional recruitment for product management, management consulting, and artificial intelligence engineering has undergone a seismic shift as of 2026. The traditional case study, which once focused on market entry or basic feature prioritization, has been largely superseded by the Generative AI (GenAI) case study. Today, candidates across the technology and business spectrum are frequently met with a daunting prompt: “A major enterprise wants to deploy a GenAI solution; how do you approach this?” In high-stakes interview rooms from Silicon Valley to Bangalore, the ability to navigate the probabilistic and often unpredictable nature of Large Language Models (LLMs) has become the primary filter for top-tier talent.

Industry data from late 2025 suggests that while 85% of Fortune 500 companies have integrated some form of GenAI into their workflows, nearly 60% of these projects struggle with scaling beyond the pilot phase due to poor architectural planning and risk mismanagement. This failure rate in the corporate world is mirrored in the interview room, where most candidates fail not because of a lack of technical knowledge, but because they lack a structured, repeatable process to solve non-deterministic problems. To address this gap, the GATHER framework has emerged as the gold standard for navigating GenAI case studies, providing a rigorous six-step playbook that balances business objectives with technical feasibility and ethical safeguards.
The Structural Divergence of GenAI Case Studies
To understand why traditional frameworks are no longer sufficient, one must analyze the fundamental differences between deterministic software and probabilistic GenAI systems. Traditional product management follows a linear trajectory: identifying a user pain point, building a feature with a predictable output, and measuring success through clear-cut metrics like click-through rates.

GenAI products, however, introduce three distinct layers of complexity. First, the output is probabilistic; the same input may yield different results, making quality assurance a moving target. Second, the “black box” nature of LLMs introduces significant safety and hallucination risks that can lead to legal and reputational damage. Third, the evaluation of these systems requires a “compound” approach, combining traditional software metrics with model-specific benchmarks and human-in-the-loop validation. Candidates who treat a GenAI prompt like a traditional feature request often overlook these nuances, leading to responses that interviewers categorize as superficial or high-risk.
The GATHER Framework: A Strategic Deep Dive
The GATHER framework—Ground, Assess, Technical Architecture, Hallucinations, Evaluation, and Roadmap—offers a comprehensive methodology designed to demonstrate both technical literacy and executive reasoning.

G: Ground the Problem
The initial phase of any GenAI initiative must involve grounding the technology in business reality. Professional consultants emphasize that GenAI should never be a “solution in search of a problem.” In an interview setting, this requires the candidate to pause and ask critical clarifying questions: What is the specific business objective (e.g., cost reduction vs. revenue growth)? Who is the end user? What is the current technical infrastructure? By spending the first three minutes grounding the problem, a candidate demonstrates the maturity to prioritize business value over technological hype.
A: Assess AI Appropriateness
A common pitfall is the assumption that an LLM is the best tool for every task. Expert practitioners argue that GenAI excels at generation and unstructured reasoning but may be inefficient for simple classification or structured data extraction. A candidate earns significant “seniority points” by suggesting that a traditional machine learning model or a simple heuristic might be more cost-effective or reliable for certain components of the solution.

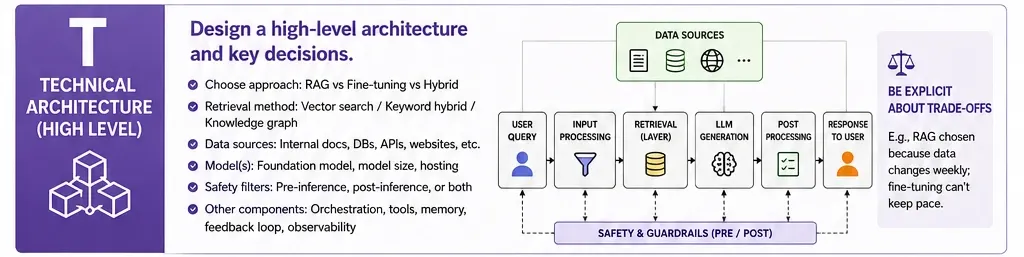
T: Technical Architecture (High-Level)
While candidates are rarely expected to write code during a case study, they must understand how system components interact. This involves making informed choices between Retrieval-Augmented Generation (RAG) and fine-tuning. For instance, in a retail environment where product catalogs change daily, RAG is preferred due to its ability to pull real-time data without the prohibitive costs of constant model retraining.
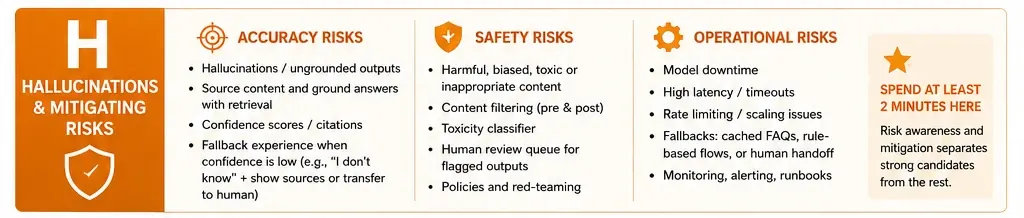
H: Hallucinations and Mitigating Risks
In 2026, risk mitigation is the most scrutinized portion of the interview. Candidates must categorize risks into three buckets: model-level (hallucinations), system-level (latency and cost), and user-level (misuse or bias). A sophisticated response includes specific mitigation strategies, such as implementing “guardrail” models that scan outputs for toxicity or factual inconsistencies before they reach the user.

E: Evaluation Metrics
Success in GenAI is measured across a “Three-Tier Metric System.” This includes technical metrics (perplexity, latency), model-specific metrics (faithfulness, relevancy via RAGAS scores), and business metrics (escalation rates, conversion uplift). By addressing all three, the candidate proves they view the AI not as an isolated script, but as a holistic business system.
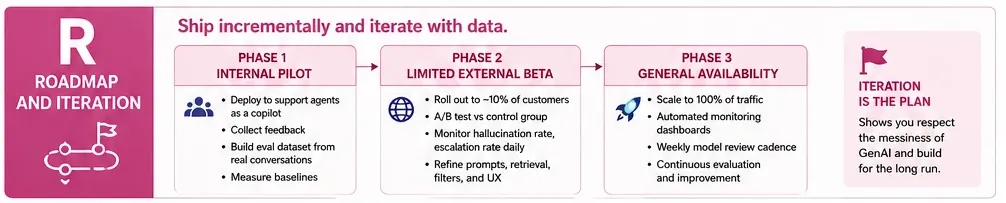
R: Roadmap and Iteration
The final step is the deployment strategy. In a professional context, “shipping” GenAI is an iterative process. A standard roadmap involves an internal pilot (Phase 1), a limited external beta with A/B testing (Phase 2), and finally, general availability with automated monitoring (Phase 3). This phased approach signals to the interviewer that the candidate understands the “messiness” of real-world AI deployment.
Scenario Analysis: E-commerce Customer Support
To see the GATHER framework in action, consider a scenario where a major retailer seeks to deploy a customer support chatbot. In 2026, the retail sector is projected to see a 40% increase in automated customer interactions.
Applying the framework, the candidate first grounds the problem by identifying that the bot must handle order tracking, returns, and product recommendations. They assess appropriateness by noting that while simple order status can be handled by an API, complex product queries require the reasoning of an LLM. Architecturally, they propose a RAG system connected to the retailer’s inventory database. To mitigate hallucinations, they suggest a “quote and cite” mechanism where the bot must provide a link to the official return policy for every claim it makes. Success is defined by a reduction in human agent hand-offs and a high “helpfulness” rating from customers.

Scenario Analysis: Healthcare Summarization at Apollo Hospitals
A more complex scenario involves clinical decision support, such as a patient record summarizer for a large network like Apollo Hospitals. This use case carries significantly higher stakes, as an incorrect summary could lead to medical errors.
In this context, grounding the problem requires understanding the diverse needs of cardiologists versus ER doctors. The assessment phase highlights that while GenAI is excellent at synthesizing disparate doctor notes, it must be used as an “extractive” tool rather than an “abstractive” one to prevent the generation of non-existent symptoms. The technical architecture must be on-premises or within a highly secure cloud to comply with India’s Digital Personal Data Protection (DPDP) Act. The roadmap would be particularly conservative, beginning with “read-only” summaries that doctors must manually verify before they are integrated into the official Electronic Health Record (EHR).
Industry Implications and Expert Perspectives
The shift toward structured GenAI reasoning is supported by recent employment trends. According to a 2025 LinkedIn Workforce Report, “AI Orchestration” has become one of the fastest-growing skill sets. Recruiters at firms like McKinsey and Google have noted that the “GATHER” approach aligns with how they evaluate candidates for “AI Product Lead” roles.
“We are no longer looking for people who can just prompt a model,” says one senior engineering manager at a leading AI lab. “We need professionals who understand the trade-offs of latency, the ethics of data privacy, and the rigorous math of evaluation. The framework isn’t just for the interview; it’s how we actually build.”
Common Pitfalls and the Path to Success
Analysis of unsuccessful interviews reveals five recurring mistakes:
- Jumping to Technical Solutions: Mentioning “RAG” or “Fine-tuning” before defining the user or the problem.
- Ignoring Costs: Failing to account for the high token costs and API latencies associated with large-scale deployment.
- Neglecting Safety: Treating hallucinations as a minor bug rather than a critical system failure.
- Weak Evaluation: Relying solely on “user feedback” instead of quantitative model benchmarks.
- Lack of Iteration: Suggesting a “big bang” release rather than a phased, risk-managed rollout.
As Generative AI continues to mature, the “GATHER” framework provides a vital bridge between theoretical knowledge and practical application. For the professional entering an interview in 2026, mastering this structure is the difference between being a spectator of the AI revolution and being one of its primary architects. The goal is not to provide a “perfect” answer—since perfect answers do not exist in probabilistic systems—but to demonstrate sound, risk-aware, and business-aligned reasoning. In the high-pressure environment of a 35-minute case study, structure is the candidate’s most powerful tool.