The landscape of open-weight artificial intelligence has shifted dramatically with the introduction of structured tool-calling capabilities in Google’s Gemma 4 model. This development represents a significant departure from traditional conversational AI, which has historically been limited by its static training data and a propensity for "hallucination" when queried about real-time events. By integrating native function-calling support directly into the model’s architecture, Google has provided developers with the means to create AI agents that can interact with the physical and digital worlds in real-time. When paired with Ollama—a tool designed for running large language models (LLMs) locally—Gemma 4 allows for the creation of sophisticated, non-cloud-dependent AI agents that maintain data privacy and eliminate subscription costs.
The Evolution of Functional AI: From Chatbots to Agents
For years, the primary limitation of large language models was their "knowledge cutoff." Because these models are trained on historical datasets, they cannot inherently know the current weather in Tokyo, the live price of Bitcoin, or the specific contents of a user’s local database. To solve this, developers initially built complex API wrappers around models, but these often lacked reliability. The AI would frequently struggle to format data correctly or fail to recognize when a specific tool should be invoked.
Gemma 4 addresses these challenges by making tool-calling a first-class citizen within the model’s logic. This "agentic" approach allows the model to act as a central processing unit—the "brain"—while external Python functions serve as the "hands." This architecture ensures that the AI does not just guess an answer but instead identifies the need for external data, requests the correct tool, and processes the returned information to provide a factual, evidence-based response.

Technical Architecture: The Two-Pass Execution Loop
Understanding the implementation of Gemma 4 requires a grasp of its operational loop. Unlike standard text generation, function calling involves a multi-stage communication process between the user, the model, and the local environment. This process is generally categorized as a two-pass pattern:
- The Initial Inquiry: The user submits a natural language prompt (e.g., "What is the current exchange rate between USD and EUR?").
- Tool Identification: The model analyzes the query and the available "tools" (JSON schemas of Python functions). If it determines a tool is necessary, it pauses text generation and instead produces a structured JSON object containing the function name and the required arguments.
- Local Execution: The developer’s code intercepts this JSON object and executes the corresponding Python function locally. The model itself never executes the code, ensuring a secure "sandbox" environment where the user remains in control of what the AI can do.
- The Second Pass: The output of the Python function (e.g., "1 USD = 0.92 EUR") is fed back into the model.
- Final Synthesis: The model receives the raw data, interprets it, and formulates a natural language response for the user.
This structured loop is the foundation of modern AI orchestration, enabling the development of agents that are far more reliable than those relying on prompt engineering alone.
Setting Up the Local Environment
To implement this locally, the hardware and software requirements have been significantly lowered by the efficiency of the Gemma 4 Edge 2B model. With a footprint of approximately 2.5 GB, the model is designed to run on consumer-grade hardware, including laptops and even high-end mobile devices.
Installation and Model Retrieval
The primary engine for local execution is Ollama. For users on macOS or Linux, the installation is handled via a simple terminal command:

curl --fail -fsSL https://ollama.com/install.sh | sh
Once Ollama is active, the Gemma 4 Edge model—specifically the E2B variant optimized for function calling—is retrieved using:
ollama pull gemma4:e2b
This model is specifically fine-tuned to adhere to JSON schemas, a critical requirement for tool-calling. Without this fine-tuning, models often generate malformed JSON that breaks the execution loop.
Establishing the Connection
The bridge between the AI model and the local Python environment is established through a helper function. By utilizing Python’s standard urllib and json libraries, developers can maintain a zero-dependency environment, which is vital for security-sensitive applications.
import json, urllib.request, urllib.parse
def call_ollama(payload: dict) -> dict:
data = json.dumps(payload).encode("utf-8")
req = urllib.request.Request(
"http://localhost:11434/api/chat",
data=data,
headers="Content-Type": "application/json",
)
with urllib.request.urlopen(req) as resp:
return json.loads(resp.read().decode("utf-8"))Practical Application: Implementing Real-World Tools
The true power of Gemma 4 is best demonstrated through practical tasks that require real-time data retrieval. Three primary use cases—weather lookup, currency conversion, and time zone management—highlight the model’s ability to handle diverse API structures.
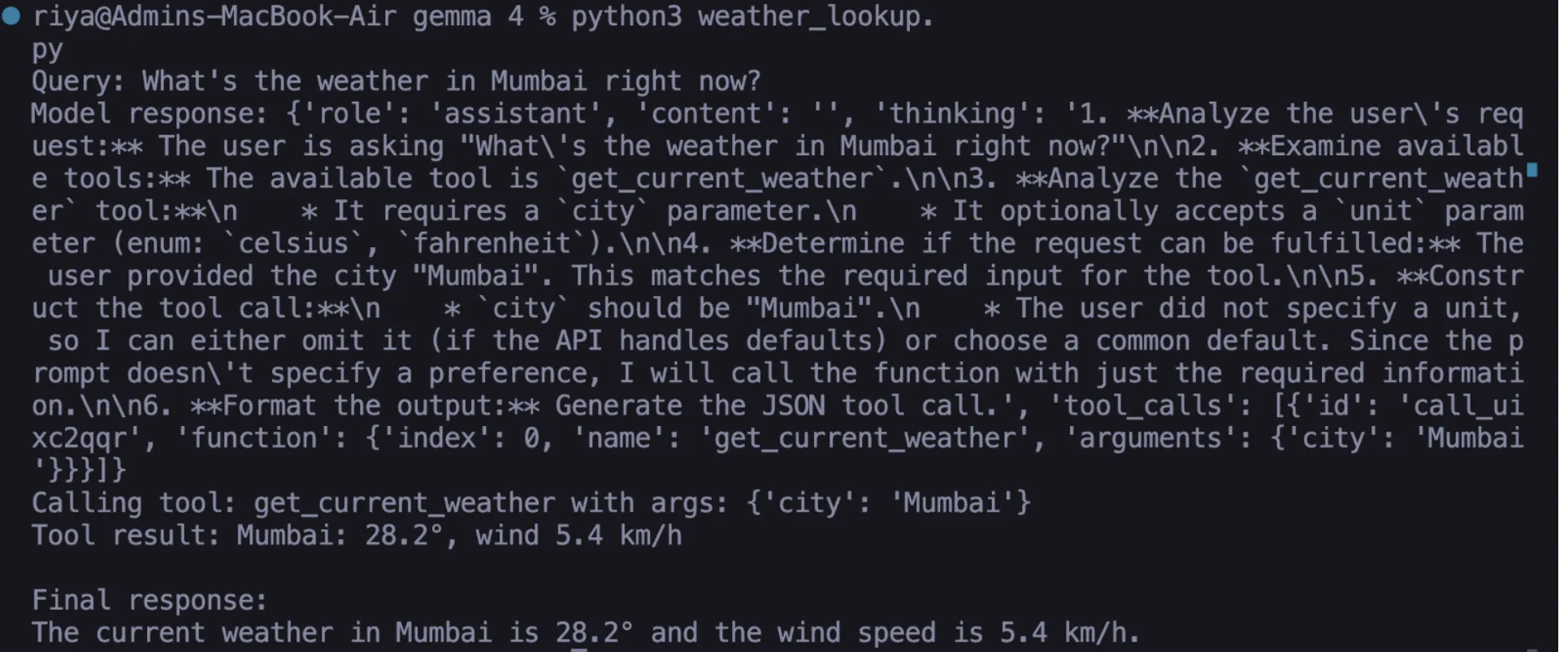
Task 1: Real-Time Weather Intelligence
Using the Open-Meteo API, developers can create a tool that fetches live meteorological data without requiring an API key. This involves defining a Python function that handles geocoding (converting a city name to coordinates) and a second API call for the weather data. The model is provided with a JSON schema that describes the get_current_weather function, including its parameters and expected data types. When a user asks about the weather in Mumbai, Gemma 4 recognizes the city name, extracts it as an argument, and triggers the local function.
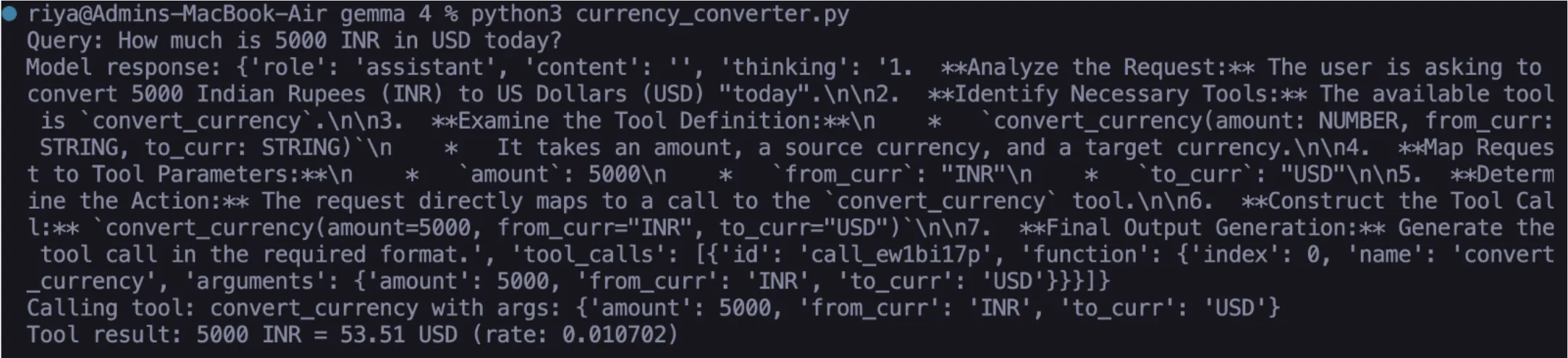
Task 2: Financial Data Accuracy
Currency conversion is a notorious pitfall for standard LLMs, which often provide outdated rates. By connecting Gemma 4 to the ExchangeRate-API, the agent can fetch live foreign exchange rates. This implementation demonstrates the model’s ability to handle numerical data and perform precise rounding, ensuring that the final output is both accurate and user-friendly.
Task 3: Multi-Intent Agent Orchestration
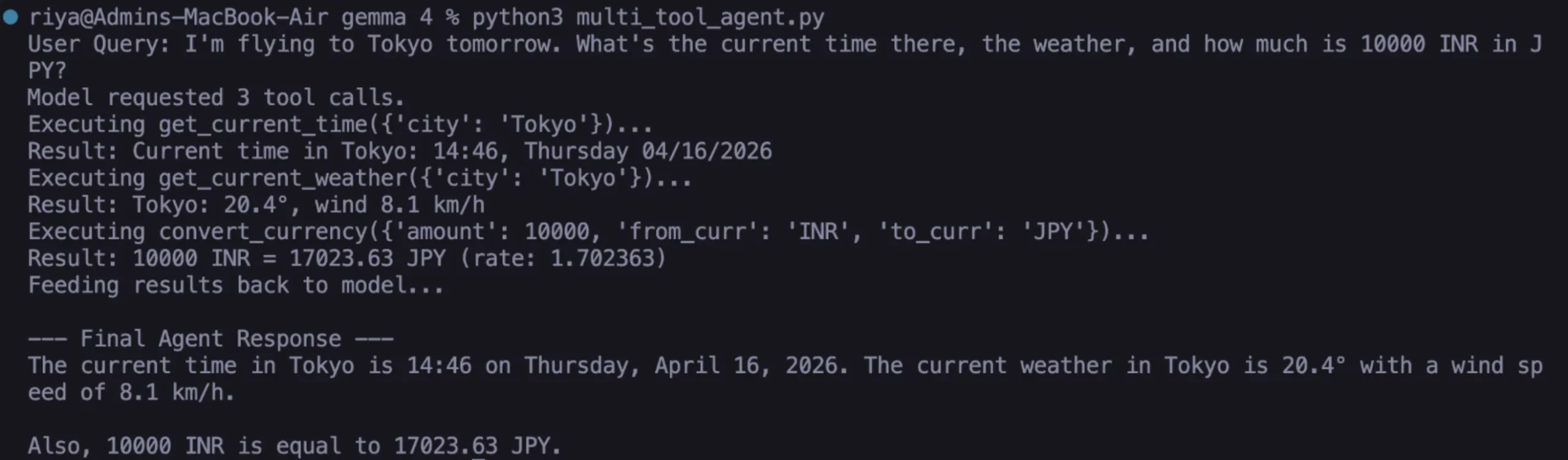
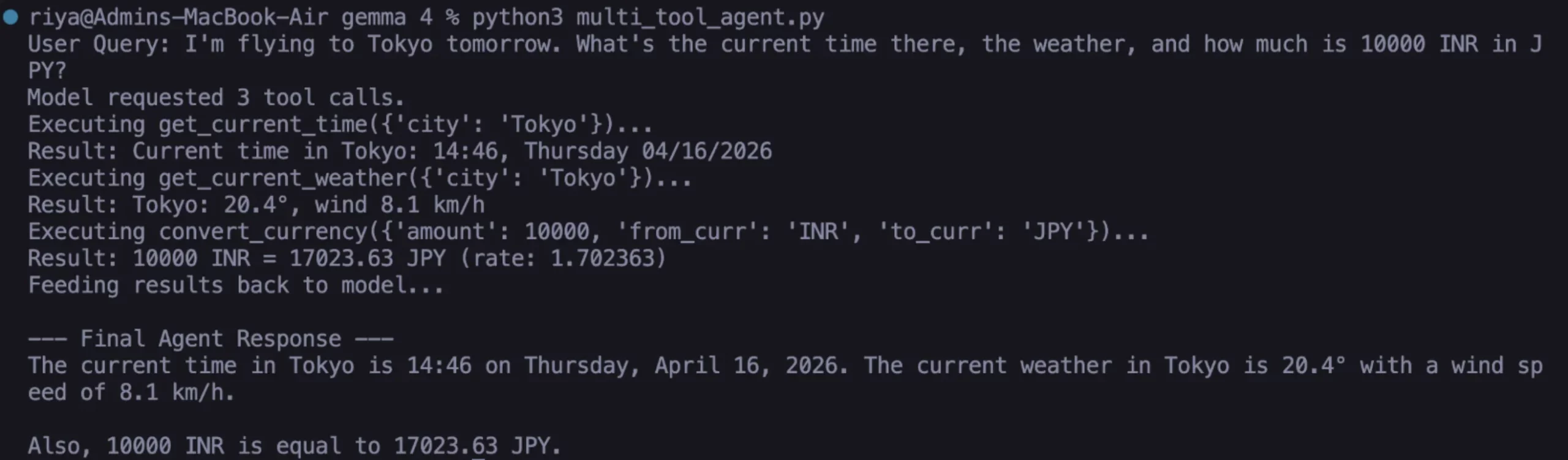
Perhaps the most impressive feature of Gemma 4 is its ability to handle compound queries. If a user says, "I’m flying to Tokyo; what’s the time there, the weather, and the conversion for 10,000 INR?" the model does not fail or require manual chaining. Instead, it identifies that three separate tools are needed. It generates a list of tool calls, processes them sequentially or in parallel, and then synthesizes a single, cohesive response. This level of coordination was previously reserved for massive, proprietary models like GPT-4 or Claude 3.5.
Analysis of Implications: Why Local Function Calling Matters
The shift toward local, agentic AI has profound implications for both individual developers and large enterprises.
Data Privacy and Security: By running the model and the functions locally, sensitive data never leaves the user’s machine. For industries such as healthcare or finance, where data residency is a legal requirement, this architecture provides a viable path to AI adoption without compromising compliance.
Cost Efficiency: Cloud-based AI APIs typically charge per token, and tool-calling often requires multiple passes, which can quickly become expensive. Local execution via Ollama and Gemma 4 is free, allowing for unlimited experimentation and high-frequency API polling without financial overhead.
Reliability in Edge Computing: As AI moves toward "the edge"—devices like smart home hubs, industrial sensors, and autonomous vehicles—the ability to function without a persistent internet connection becomes critical. Gemma 4’s lightweight architecture (2B parameters) makes it an ideal candidate for these environments.
The Future of Open-Weight AI Agents
The introduction of Gemma 4’s function-calling capabilities marks a milestone in the democratization of AI. By providing a model that consistently produces valid JSON and accurately identifies tool-use scenarios, Google has lowered the barrier to entry for building complex AI systems.
Future developments in this space are expected to focus on "long-horizon" tasks, where agents can perform sequences of dozens of steps, such as managing a local file system or automating software testing. As the ecosystem around Ollama and the Gemma family grows, the reliance on centralized, proprietary AI "gatekeepers" is likely to diminish, giving way to a more distributed and autonomous AI landscape.
For developers, the message is clear: the era of the passive chatbot is ending. The era of the functional, local AI agent has begun. By mastering these tool-calling techniques today, builders can create the foundation for the next generation of autonomous digital assistants.