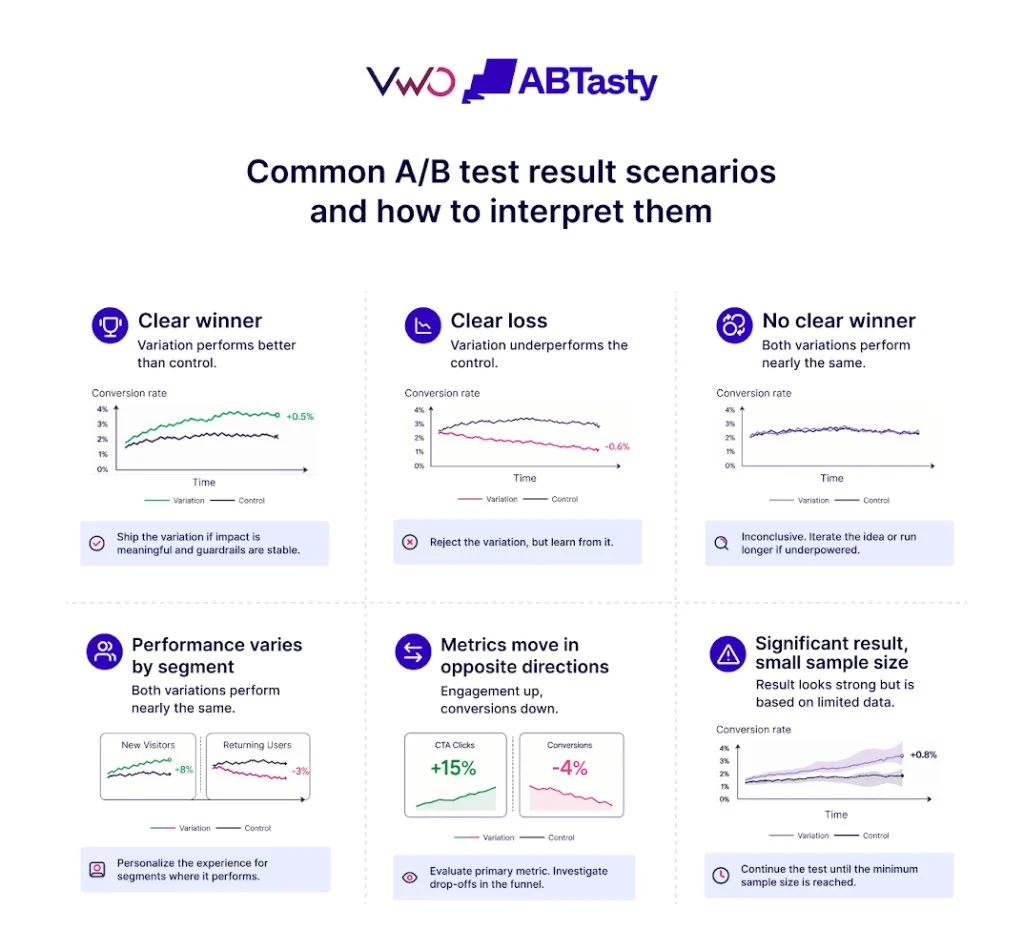
The determination of A/B test duration remains one of the most critical yet misunderstood facets of digital experimentation, directly influencing the validity of data-driven decisions and the overall velocity of conversion rate optimization (CRO) programs. While there is no universal timeframe that applies to every website, industry experts emphasize that the length of an experiment is a function of four primary variables: traffic volume, the minimum detectable effect (MDE), statistical significance thresholds, and power settings. Failure to account for these factors before launching a test can lead to “sample pollution,” where external variables like seasonal shifts or returning visitor behavior skew results, rendering the experiment’s conclusions unreliable.
A/B testing, at its core, is a statistical exercise designed to mitigate risk. By running a controlled experiment, businesses seek to confirm whether a proposed change—such as a new headline, a redesigned checkout flow, or a different pricing structure—actually improves user behavior. However, the integrity of this confirmation relies heavily on the “acid test” of duration. Before a single line of code is deployed, a duration estimate serves as a feasibility study, signaling whether a hypothesis is worth pursuing. For instance, if mathematical projections indicate that a test requires 14 weeks to reach statistical significance on a minor homepage change, the experiment may be deemed unviable, prompting the team to rethink the segment size or the expected impact.

The Strategic Importance of Pre-Test Duration Planning
In the modern landscape of digital product management, experimentation is not merely about finding “winners”; it is about managing a backlog of ideas. Expert practitioners, such as Sadie Neve, Group Digital Experimentation Manager at Rubix, argue that duration shapes the entire experimentation roadmap. Every test run represents an opportunity cost. Since teams cannot test every hypothesis simultaneously without risking cross-contamination, the time each test occupies on the calendar dictates how many ideas can be validated within a business quarter.
For high-traffic platforms, test cycles might be brief, allowing for three or four iterations per quarter. Conversely, for teams with limited traffic, durations often stretch, requiring a more rigorous prioritization of bold, high-risk ideas over subtle changes that would take months to validate. This operational reality necessitates a clear understanding of the “experimentation landscape” before committing resources. Neve recommends mapping traffic volumes and baseline performance across the site to identify which areas can realistically support multi-variant testing and which require a more streamlined approach.
Key Statistical Concepts: MDE and the Resolution Analogy
To understand how duration is calculated, one must first grasp the relationship between the Minimum Detectable Effect (MDE) and sample size. Ellie Hughes of the Eclipse Group introduces the concept of “experiment resolution” to explain this dynamic. Much like a high-resolution photograph captures finer details but requires more data (pixels), detecting a small change in user behavior (a low MDE) requires a much larger sample size and, consequently, a longer duration.
If an organization aims to detect a subtle 1% lift in conversions, the “resolution” must be incredibly high, requiring hundreds of thousands of visitors to separate the signal from the noise. If the organization is only interested in “big wins”—say, a 10% lift—the resolution can be lower, the required sample size smaller, and the test duration shorter. The tradeoff is precision; by choosing a high MDE to shorten the test, the team accepts that they may miss smaller, incremental gains that could have been identified with a longer run.
Expert Methodologies and Conversion Thresholds
Professional experimenters utilize various frameworks to ensure they do not “call” a test too early. Kateryna Berestneva, CRO Manager at SomebodyDigital, advocates for a dual-threshold approach. In her methodology, a test must meet two criteria: a minimum of 100 conversions per variation and at least 95% statistical significance. In her experience, this typically translates to a run time of four to six weeks.
The “100 conversions” rule acts as a safeguard against the volatility of small sample sizes. While a high-traffic landing page might reach 95% significance in 48 hours, early results are often driven by “novelty bias” or random variance. By enforcing a conversion floor and a multi-week duration, teams can account for the “full business cycle,” which includes fluctuations in user behavior between weekdays and weekends.
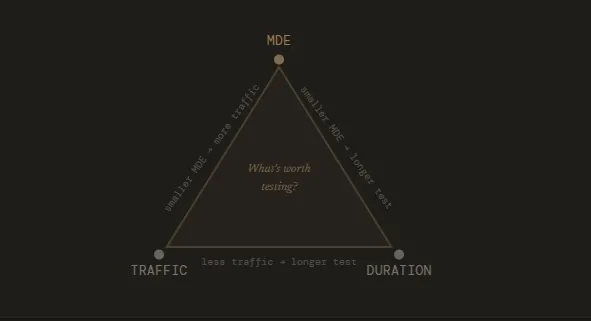
Ruben, owner at Conversion Ideas, supports this focus on stable conditions. He notes that while some practitioners warn against running tests longer than a week, the priority should be “clean” samples rather than speed. He suggests that a three-week test with a 3% MDE is often more valuable than a one-week test with a 10% MDE, as it provides a more stable reflection of true user intent.
The Risks of “Peeking” and P-Hacking
One of the most pervasive errors in digital experimentation is “peeking”—the act of checking test results before the predetermined duration has elapsed and making a decision based on those preliminary numbers. This practice significantly inflates the “false positive” rate. Because p-values naturally fluctuate as data accumulates, a test may appear to be a “winner” at day five but regress to the mean by day fourteen.
Gerda Thomas, co-founder at Koalatative, compares early stopping to leaving an NBA game after the first basket is scored. Just as the first few minutes of a basketball game do not determine the final score, the first few days of an A/B test do not provide a complete picture of user behavior. Stopping early distorts the statistics and, more importantly, undermines the long-term direction of the experimentation program. When decisions are based on “noise” rather than “signal,” teams end up prioritizing the wrong roadmap items, leading to a failure to replicate results when changes are pushed to production.

This phenomenon is closely linked to “p-hacking,” where researchers or marketers continuously monitor a test and stop it the exact moment the p-value hits 0.05. Without reaching the target sample size, this “significance” is often an illusion, leading to “eroded trust” when the projected revenue lifts fail to materialize in the company’s bank account.
Legitimate Scenarios for Early Termination
Despite the rigorous standards for test duration, there are specific, “fringe” scenarios where stopping a test early is the responsible course of action. Ioana Iordache, Founder and Product Growth Consultant at Io Growth Lab, identifies three primary justifications:
- Critical Technical Failures: If a variant is found to be broken—such as a “Buy Now” button failing to trigger on mobile devices—the test must be stopped immediately to prevent further revenue loss.
- Severe Negative Impact: If a variant causes a catastrophic drop in a primary KPI (e.g., a 30% drop in checkout completions) that cannot be explained by random variance, it is often safer to kill the experiment than to wait for full statistical significance.
- Clear Winners in High-Risk Environments: While rare, some organizations use sequential testing methodologies that allow for early stopping if a variant is performing so exceptionally well that the “cost of continuing” the test (the revenue lost by not showing the winner to 100% of traffic) outweighs the risk of a false positive.
Implementation: Utilizing Duration Calculators
To remove the guesswork from the process, modern CRO teams rely on tools like the Convert Test Duration Calculator. These tools utilize frequentist statistics to define the parameters of a “fixed-horizon” test. By inputting weekly visitors, current conversion rates, and the number of variants, the calculator provides a definitive window for the experiment.
The selection of the MDE remains the most strategic input in these calculators. This number represents the “minimum lift worth acting on.” If a developer’s time is expensive, a 0.5% lift might not justify the cost of implementation. Therefore, the MDE should be aligned with business costs. Once the duration is calculated and the test begins, the professional standard is to commit to the window and avoid acting on results until the final day.
Broader Impact and Industry Implications
The rigor applied to A/B test duration has profound implications for the credibility of the CRO industry. As businesses become increasingly data-reliant, the cost of “bad data” grows. Inaccurate experiments lead to bloated codebases, confused user experiences, and wasted marketing spend.
By adhering to strict duration protocols, organizations ensure that their experimentation programs are built on a foundation of integrity. This disciplined approach allows for a “virtuous cycle” of learning, where each test—win or loss—provides a stable insight that informs the next hypothesis. In the final analysis, the goal of calculating test duration is not just to find a winner, but to generate insights that a business can confidently build upon for years to come. The consensus among experts is clear: calculate the duration upfront, respect the statistical power of the sample, and resist the urge to sacrifice accuracy for the sake of speed.