The determination of A/B test duration has emerged as a pivotal factor in the success of digital experimentation programs, directly influencing the reliability of data-driven decisions and the overall velocity of product development cycles. While the industry lacks a singular, universal timeframe for running experiments, the consensus among leading conversion rate optimization (CRO) specialists suggests that duration is a complex function of traffic volume, minimum detectable effect (MDE), statistical significance thresholds, and power settings. In the contemporary landscape of high-stakes digital commerce, the ability to accurately forecast and adhere to a test duration is no longer merely a technical requirement but a strategic necessity for maintaining data integrity and organizational trust.
The Foundational Mechanics of Experimentation Timing
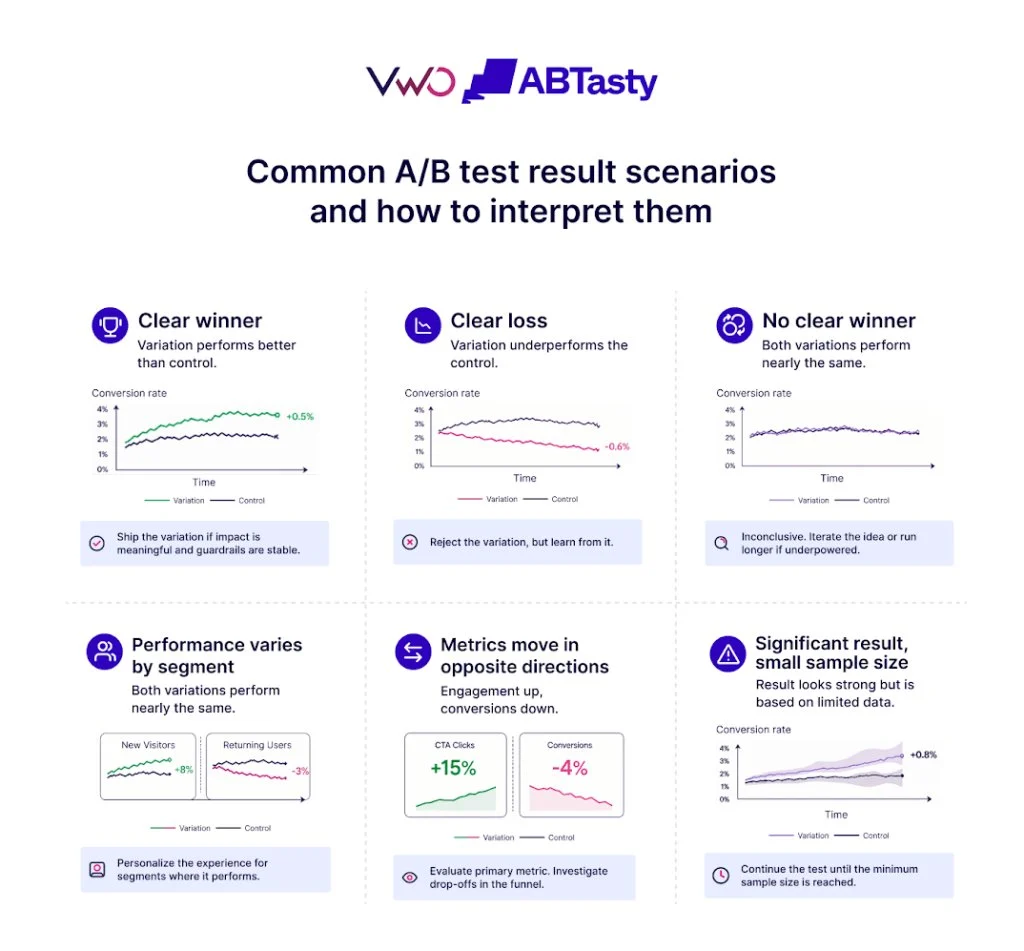
Test duration is defined as the elapsed time from the initial split of user traffic between variants to the final moment a result is declared or the experiment is terminated. This period serves as a critical filter for determining the feasibility of a hypothesis. Before the deployment of any code, a duration estimate acts as a reality check, signaling whether an experimental concept is viable within the constraints of current traffic patterns and business timelines.
Industry experts emphasize that the mathematical requirements of significance often clash with business desires for rapid iteration. For instance, if a proposed change affects only a small segment of homepage visitors, such as 3%, and the required duration to reach statistical significance is calculated at 14 weeks, the hypothesis may be fundamentally unsuited for a standard A/B test. In such scenarios, the data suggests that the segment is too narrow or the expected effect size is too subtle to be detected within a reasonable business cycle. This necessitates a pivot in strategy, such as targeting a broader audience or refining the hypothesis to aim for a more substantial impact.

Expert Methodologies in Duration Calculation
Leading practitioners in the field of experimentation have developed various frameworks to mitigate the risks of improper test timing. Kateryna Berestneva, a CRO Manager at SomebodyDigital, advocates for a threshold-based approach. Her methodology requires a minimum of 100 conversions per variation combined with a statistical significance level of at least 95%. In practical application, this frequently translates to a duration of four to six weeks, depending on the specific traffic environment. Berestneva notes that while high-traffic landing pages might reach these thresholds quickly, tests deeper in the conversion funnel—such as checkout confirmation pages—require significantly more time due to the natural attrition of users.
Complementing this approach, Sadie Neve, Group Digital Experimentation Manager at Rubix, stresses the importance of mapping the experimentation landscape prior to launching any test. By analyzing traffic volumes and baseline performance across various site sections, experimenters can identify which areas are capable of supporting multi-variant tests. Neve utilizes a structured spreadsheet model that integrates baseline performance, daily traffic, and significance thresholds to generate a range of MDEs. This preemptive analysis prevents the design of experiments that are mathematically destined to fail due to insufficient sample sizes.
Furthermore, Ruben de Boer, owner of Conversion Ideas, highlights the necessity of accounting for full business cycles. De Boer suggests that tests should typically run for two to four weeks to ensure that data captures the variance in user behavior across different days of the week and times of day. He posits that a stable sample over three weeks with a 3% MDE is often more valuable than a volatile one-week sample aiming for a 10% MDE.
The Concept of Experiment Resolution
A growing trend in the experimentation community is the use of the “resolution” analogy to explain the relationship between MDE and duration. Introduced by Ellie Hughes of Eclipse Group, this concept compares the depth of detail in a drawing to the granularity of an A/B test. Just as a highly detailed portrait requires more time for an artist to complete, detecting a fine, subtle change (a low MDE) requires a larger sample size and, consequently, a longer duration.
This analogy helps bridge the gap between complex statistical rules and practical application. If a business requires high-resolution data to detect a 1% lift in conversions, it must be prepared to invest the time necessary to collect a massive sample. Conversely, if the business is only interested in “low-resolution” or high-impact changes (e.g., a 10% lift), the test can reach a conclusion much faster.
The Strategic Impact on the Experimentation Backlog
The duration of an individual test does not exist in a vacuum; it directly dictates the throughput of the entire experimentation program. Every test running on a specific page or segment represents an opportunity cost, as it prevents other hypotheses from being tested in that same space.
For an organization running four concurrent tests that each take six weeks, the capacity of the program is limited to approximately two cycles per quarter. If duration estimates can be tightened through better targeting or more focused MDEs, a team might increase its capacity to three or four cycles. This acceleration allows for more ideas to be validated, leading to a faster pace of innovation and a more agile response to market changes.
However, for teams with limited traffic, the pressure to produce results can lead to the deprioritization of bold, high-risk ideas. Longer test durations often force teams to favor “safe” changes that are likely to show results quickly, potentially stifling the kind of radical experimentation that leads to significant breakthroughs.
Risks of Premature Termination and the “Peeking” Problem
One of the most significant threats to data integrity in A/B testing is the temptation to stop a test early once a result looks promising. This practice, often referred to as “peeking,” can lead to severely inflated false positive rates. Because p-values naturally fluctuate as data accumulates, an early lead by one variant may simply be the result of random noise rather than a genuine behavioral shift.
Stopping a test the moment it hits a significance threshold—a practice known as “p-hacking”—undermines the statistical foundation of the experiment. Gerda Thomas, co-founder at Koalatative, compares early stopping to leaving a basketball game after the first basket is scored. Without allowing the full duration to play out, the experimenter fails to account for novelty bias, weekend versus weekday behavior, and other external variables.
The long-term consequences of early stopping extend beyond a single incorrect result. Sadie Neve warns that these inaccuracies compound over time. If the underlying learnings from an experiment are flawed, they will inevitably misinform the future roadmap, leading to the prioritization of the wrong features and the eventual erosion of trust in the experimentation program when the “winning” results fail to replicate in a production environment.
Justifiable Exceptions for Stopping Tests Early
While the general rule is to adhere to a predetermined duration, certain “fringe” scenarios allow for safe early termination. Ioana Iordache, Founder and Product Growth Consultant at Io Growth Lab, identifies three primary conditions:

- Technical Malfunctions: If a variant is found to be broken, causing critical errors or preventing users from completing a task, the test must be stopped immediately to protect the user experience and revenue.
- Extreme Negative Impact: If a variant causes a catastrophic drop in key metrics that exceeds a pre-defined “guardrail” threshold, the business may choose to cut its losses.
- Clear Winners in High-Velocity Environments: In rare cases where a variant shows an overwhelming and stable lead that far exceeds the MDE within a high-traffic environment, and the result is validated by secondary metrics, a calculated decision to stop may be made—though this remains controversial among statisticians.
Chronology of a Successful Duration Strategy
To ensure scientific rigor, organizations are encouraged to follow a structured timeline for test duration planning:
- Pre-Test Audit: Analyze historical traffic and conversion data for the specific URL or app screen.
- MDE Calibration: Determine the minimum level of improvement that justifies the cost of implementation.
- Duration Calculation: Utilize specialized tools, such as the Convert Test Duration Calculator, to input traffic, conversions, and the number of variants to generate a fixed timeframe.
- Commitment Phase: Document the end date and agree that no decisions will be made based on interim data.
- Execution: Run the test through at least two full business cycles (14 days) to account for weekly variability.
- Post-Hoc Analysis: Once the window closes, evaluate the results against the original MDE and significance targets.
Analysis of Broader Implications
The shift toward more disciplined test duration management reflects a maturing digital industry. As organizations move away from “gut-feeling” decisions toward rigorous data science, the role of the experimenter has evolved into that of a gatekeeper for truth.
The broader impact of accurate duration planning is the stabilization of growth. When companies base their product roadmaps on statistically sound results, the cumulative effect of small, validated wins leads to sustainable long-term revenue increases. Conversely, programs that prioritize speed over accuracy often find themselves in a cycle of “winning” tests that never actually move the needle on the company’s bottom line.
In conclusion, the science of A/B test duration is a balance between mathematical necessity and business agility. By leveraging expert frameworks, avoiding the pitfalls of peeking, and utilizing advanced calculation tools, experimentation teams can ensure that every test they run provides a solid foundation for the next stage of organizational growth. Adhering to a calculated duration is not just about the numbers; it is about building a culture of evidence-based decision-making that can withstand the pressures of a fast-paced digital economy.