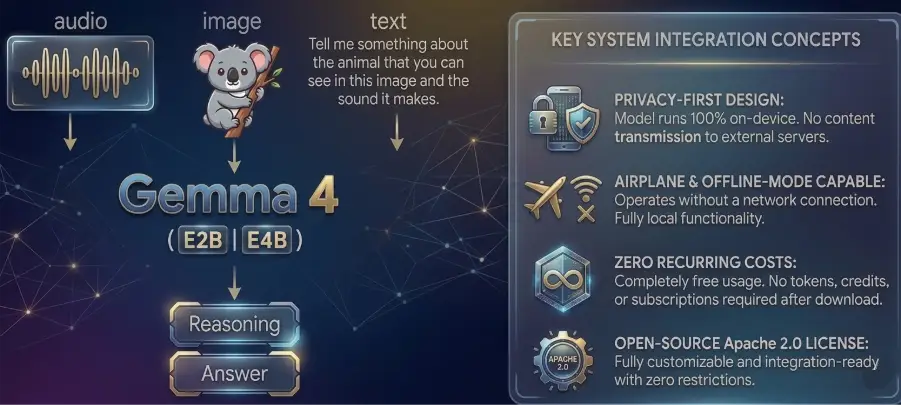
Google has officially announced a significant shift in the landscape of mobile artificial intelligence with the release of the Gemma 4 model family, a suite of open-source Large Language Models (LLMs) designed to operate entirely on-device. By integrating these models with the newly launched AI Edge Gallery application, Google is effectively removing the requirement for internet connectivity for complex AI tasks, including coding, image analysis, and multi-step agentic workflows. This move marks a departure from the traditional cloud-reliant AI architecture, where user prompts are transmitted to remote servers for processing. Gemma 4 allows for a "one-time download" approach, after which the smartphone’s local hardware handles all computational requirements, ensuring a level of data privacy and latency reduction previously unavailable to the general public.
The introduction of Gemma 4 comes at a time when the tech industry is increasingly concerned with the energy costs and privacy implications of centralized AI. By optimizing high-performance models for mobile hardware, Google is positioning itself at the forefront of the "Edge AI" movement. The Gemma 4 family is built upon the same technological foundations as Google’s flagship Gemini models but is tailored for the open-source community under the permissive Apache 2.0 license. This licensing choice is particularly noteworthy, as it allows developers and enterprises to modify, build upon, and commercialize the models without the burden of usage fees or restrictive proprietary barriers.
The Architecture of Gemma 4: From Edge to Enterprise
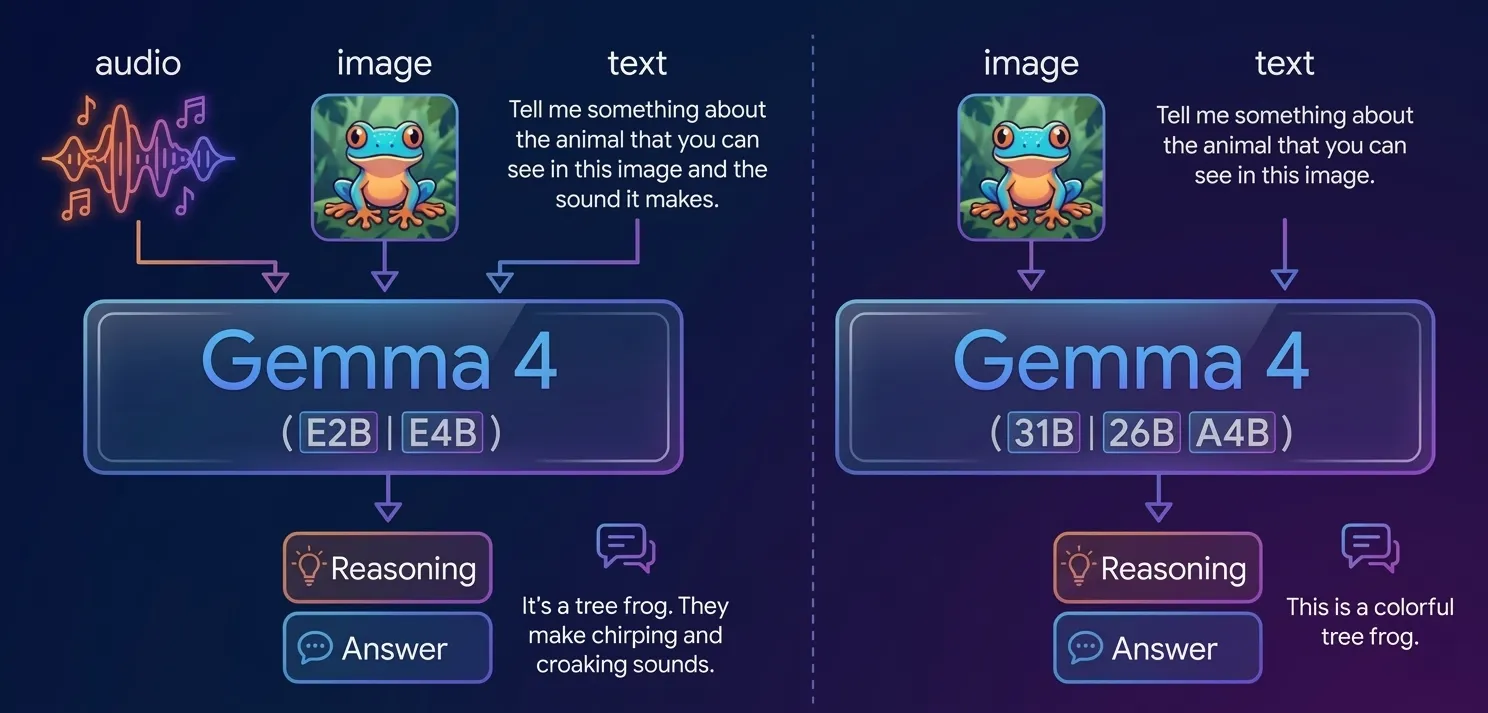
The Gemma 4 ecosystem is comprised of four distinct variants, each engineered for specific hardware profiles and performance benchmarks. Unlike previous iterations of open-source models that often forced a trade-off between size and capability, Gemma 4 utilizes advanced compression and architecture techniques to maintain high logic standards even in smaller footprints.
At the top of the hierarchy sits the 31B Dense model, which currently ranks as the third-highest-performing open-source model globally. Parallel to this is the 26B Mixture of Experts (MoE) model, ranking fifth worldwide. The MoE architecture is particularly significant as it allows the model to activate only a fraction of its parameters for any given task, thereby increasing efficiency and throughput without sacrificing the depth of its knowledge base.

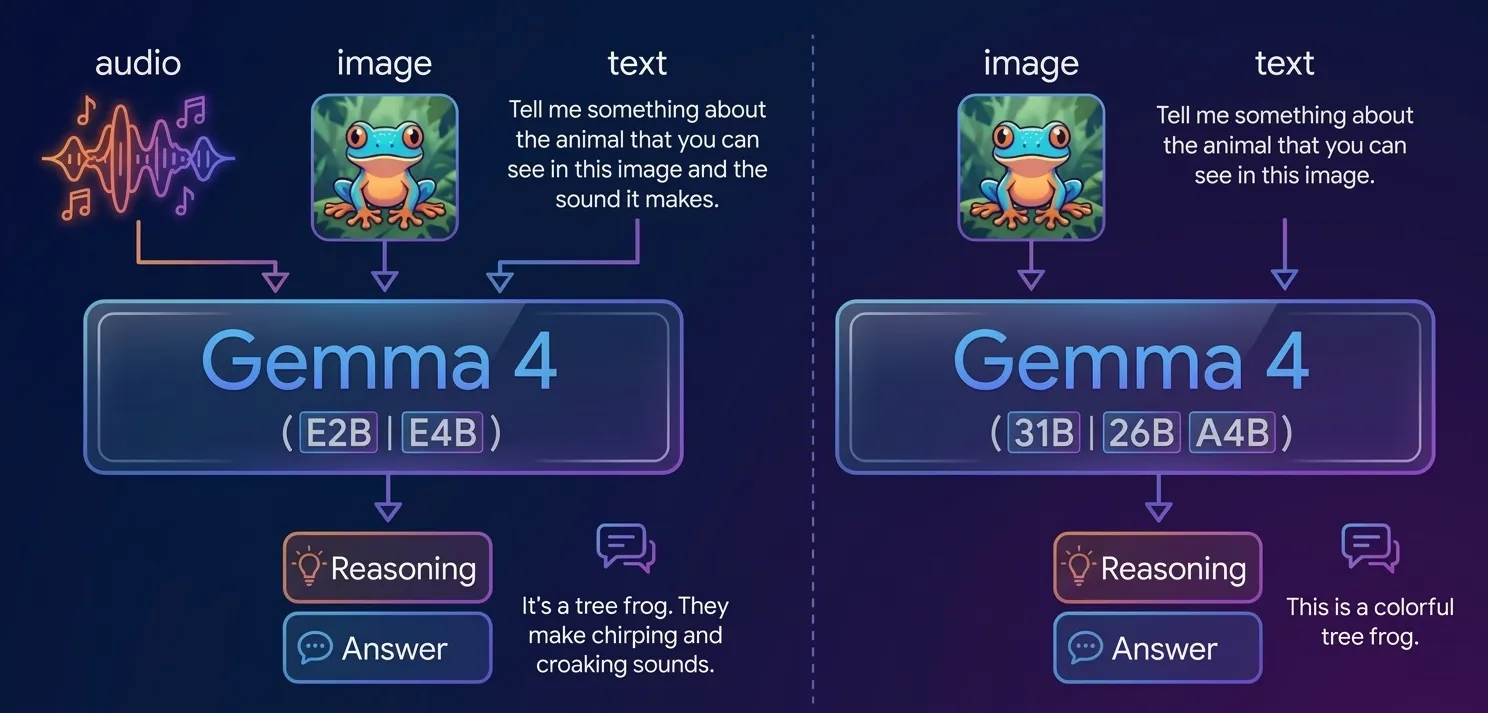
For mobile devices and resource-constrained environments, Google has introduced the "Effective" series: Gemma 4 E2B and E4B. The E2B variant is optimized for low-resource hardware, focusing on high-speed performance for basic text and logic tasks. The E4B variant, while slightly larger, is designed for higher throughput and more complex reasoning, specifically targeting function calling and agentic behaviors. These edge models are capable of processing multimodal inputs, including text, audio, and video, while remaining small enough to fit within the storage and RAM limitations of modern smartphones.
Chronology of On-Device AI Development
The path to Gemma 4 reflects a multi-year effort by Google to democratize AI. The timeline of this evolution highlights a clear trajectory from research-based demonstrations to consumer-ready applications:
- Early 2023: Google begins the "Gemma" project, aiming to distill the power of its proprietary Gemini models into open-weight versions for the developer community.
- Late 2023 – Early 2024: The release of Gemma 1 and 2 established benchmarks for small-scale models, proving that 2-billion and 7-billion parameter models could compete with much larger counterparts.
- Mid-2024: The introduction of the AI Edge Gallery beta, providing a testing ground for running models on Android and iOS without cloud intervention.
- Current Release: The launch of Gemma 4, featuring 140+ language support, advanced agentic "skills," and the full integration of the AI Edge Gallery app for the general public.
This progression indicates a strategic shift toward "Privacy by Design," where the goal is to provide users with sophisticated AI tools that do not require them to sacrifice their personal data to the cloud.
The AI Edge Gallery: Bridging the Gap Between Model and Mobile
The AI Edge Gallery application serves as the primary interface for users to interact with Gemma 4 on mobile platforms. Available on both the Google Play Store and the Apple App Store, the application functions as an open-source gateway. Once a user downloads the specific model weights—either the E2B or E4B versions—the app no longer requires an active data connection.
The application is structured into five core functional modes:
- AI Chat: A standard interface for text-based queries and conversational logic.
- Ask an Image: A vision-based feature allowing users to upload or take photos for the AI to analyze and describe.
- Audio Scribe: A local transcription service that converts spoken word into text without sending audio files to a server.
- Agent Skills: A sophisticated framework for multi-step tasks where the AI can interact with other device functions.
- Prompt Lab: A developer-focused environment for testing and refining specific AI instructions.
The "Agent Skills" feature is perhaps the most transformative aspect of the app. It allows the AI to act as an autonomous agent, capable of executing complex sequences such as searching a local map or drafting an email. This is one of the first instances where "Agentic AI"—technology that can plan and execute steps to reach a goal—has been made available for offline mobile use.
Supporting Data and Performance Benchmarks
In comparative testing, the Gemma 4 E4B model has shown a marked ability to handle complex function schemas that often cause smaller models to fail. While the E2B model is preferred for its speed and lower memory footprint, the E4B model is essential for tasks requiring "multi-step reasoning."
For instance, in a technical use case involving the generation of code for a Sudoku game, the E2B model occasionally struggles with task completion, sometimes stopping mid-process due to memory constraints. In contrast, the E4B model consistently produces full HTML and JavaScript code blocks, accompanied by detailed deployment instructions.
However, the transition to local processing does come with performance trade-offs. Data indicates that because the processing is limited by the phone’s CPU and NPU (Neural Processing Unit), execution times are significantly longer than cloud-based alternatives. A task that might take two seconds on a Google server could take thirty seconds or more on a mid-range smartphone. Furthermore, the E4B model requires a higher RAM threshold, making it less suitable for budget-tier mobile devices.
Official Responses and Strategic Implications
Industry analysts view the release of Gemma 4 as a direct challenge to the subscription-based models favored by competitors. By providing high-quality models under the Apache 2.0 license, Google is incentivizing businesses to move away from token-based pricing models.
"The licensing of Gemma 4 is a strategic masterstroke," noted one industry consultant. "By allowing businesses to build on these models without usage restrictions, Google is ensuring that Gemma becomes the standard for edge computing. This isn’t just about a phone app; it’s about the future of IoT, automotive AI, and secure enterprise communications."
Google’s official documentation emphasizes that the "Agent Skills" are designed with transparency in mind. Users can track exactly which "skill" the agent is using at any given moment, addressing common concerns regarding the "black box" nature of autonomous AI. This transparency is a key component of Google’s broader "Responsible AI" framework, which aims to mitigate the risks of hallucination and unauthorized data access.
Broader Impact: Privacy, Accessibility, and the Digital Divide
The implications of fully offline AI extend far beyond convenience. For users in regions with unstable internet connectivity, Gemma 4 provides access to advanced educational and professional tools that were previously out of reach. In professional sectors such as healthcare or legal services, where data sensitivity is paramount, the ability to process information without it ever leaving the device is a game-changer.
Key benefits identified by early adopters include:
- Zero Latency in Connectivity: While local processing is slower, it is not subject to "network lag" or server timeouts, providing a consistent user experience in dead zones.
- Cost Efficiency: Users avoid the costs associated with data usage and monthly AI subscriptions.
- Enhanced Privacy: Sensitive documents, private photos, and personal schedules can be analyzed by the AI with zero risk of a third-party data breach.
Despite these advancements, Gemma 4 is not without its limitations. The current iteration can be "memory hungry," often leading to high battery drain during intensive tasks. There are also reported issues with "agentic transparency," where the AI may claim to have sent an email without providing the specific metadata of the transaction. Additionally, while the model supports 140+ languages, its reasoning capabilities in non-English languages are still being optimized.

Conclusion: The Era of the Pocket Server
The release of Gemma 4 and the AI Edge Gallery marks the end of the "Research Demo" era for on-device AI. What was once a theoretical possibility—carrying a high-level reasoning engine in one’s pocket—is now a functional reality. By bridging the gap between open-source flexibility and mobile hardware, Google has fundamentally altered the relationship between the user and the machine.
As hardware manufacturers continue to integrate more powerful NPUs into smartphones, the performance gap between local and cloud AI is expected to narrow. For now, Gemma 4 stands as a robust proof-of-concept that the future of artificial intelligence is not just in the cloud, but in the palm of the hand, running silently, securely, and entirely offline.