The landscape of generative artificial intelligence has undergone a fundamental shift with Google’s release of the Gemma 4 family, a series of open-weight models designed to bring high-performance reasoning and multimodal capabilities to local hardware. This release marks a significant milestone in the tech giant’s strategy to compete with Meta’s Llama and Mistral AI’s offerings, focusing on the growing demand for privacy-centric, offline-capable AI solutions. By providing weights that can be run on consumer-grade hardware, Google is enabling developers to build sophisticated applications without the recurring costs or data privacy concerns associated with proprietary cloud-based APIs.
The Strategic Shift Toward Open-Weight Architecture
The introduction of Gemma 4 follows the success of its predecessors, Gemma 1 and 2, but introduces a more sophisticated architectural approach. Unlike "closed" models like Gemini, which are accessible only via API, open-weight models allow developers to download the model parameters and run them on their own infrastructure. This "open-weight" distinction is critical; while the underlying training data and code may remain proprietary, the ability to execute the model locally provides a level of transparency and control that was previously reserved for smaller, less capable models.
Industry analysts suggest that Google’s move is a direct response to the democratization of AI. As enterprises become increasingly wary of sending sensitive data to third-party servers, the value of a model that can perform complex reasoning within a corporate firewall has skyrocketed. Gemma 4 is positioned as a bridge between the agility of open-source research and the robust performance expected from Google’s engineering pipeline.

Architectural Diversity: The Four Variants of Gemma 4
Gemma 4 is not a single model but a tiered family designed for various hardware constraints and use cases. The family is divided into four primary variants, categorized by their parameter counts and architectural styles:
- Gemma 4 E2B and E4B: These models are optimized for "edge" performance. With 2.3 billion and 4.5 billion effective parameters respectively, these variants utilize a "Dense + PLE" (Parameter-Level Efficiency) architecture. They are designed for high-speed inference on mobile devices and laptops, supporting a context window of 128,000 tokens.
- Gemma 4 26B-A4B: This variant represents a shift toward efficiency through the Mixture-of-Experts (MoE) architecture. By utilizing 3.8 billion active parameters out of a total of 25.2 billion, the model only activates specific "expert" neurons for given tasks. This allows for the reasoning capabilities of a large model with the latency of a much smaller one. It supports a 256,000-token context window.
- Gemma 4 31B: The flagship of the local family, the 31B model uses a traditional Dense Transformer architecture. With 30.7 billion active parameters, it is built for complex reasoning, long-form content generation, and multimodal tasks involving text and images. Like the MoE version, it features a 256,000-token context window, making it suitable for analyzing large document sets.
Technical Specifications and Hardware Requirements
The utility of Gemma 4 is heavily dependent on the hardware available to the user. Because these models reside in the system’s VRAM (Video RAM), the choice of model must align with the machine’s GPU capabilities.

For entry-level use, such as running the E2B or E4B variants, a standard modern laptop with 8GB to 16GB of unified memory (such as an Apple M2 or M3 MacBook Air) is sufficient. These models are ideal for basic text summarization and simple chatbot interactions.
However, the 26B and 31B variants require more substantial resources. To run the 31B model comfortably, developers typically need 24GB of VRAM, found in high-end consumer GPUs like the NVIDIA RTX 3090 or 4090, or professional-grade hardware. On Apple Silicon, 32GB or more of unified memory is recommended to accommodate both the model and the operating system’s requirements.
Integration with Ollama and the Local Ecosystem
To facilitate the deployment of these models, Google has ensured compatibility with Ollama, an open-source framework that simplifies the process of running large language models (LLMs) locally. Ollama manages the complexities of model weights, quantization, and local API endpoints, allowing developers to interact with Gemma 4 through a simple command-line interface.
The installation process reflects the industry’s move toward "one-click" AI. By pulling specific tags—such as gemma4:e2b or gemma4:31b—users can initialize a local environment in minutes. This ecosystem is further supported by tools like Claude Code CLI, an agentic development tool that can be configured to use local Ollama endpoints as its "brain." This synergy allows for a fully local development cycle where code generation, debugging, and testing occur without an internet connection.
Case Study: Building an AI-Powered "Second Brain"
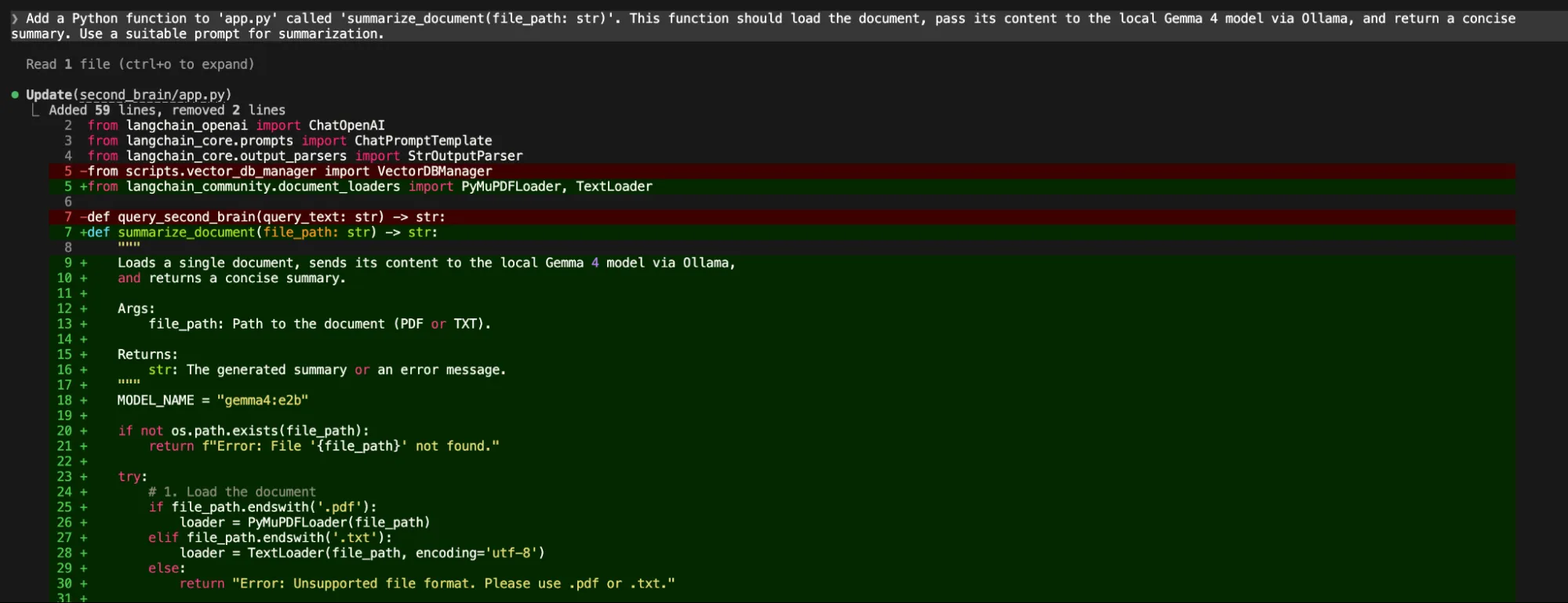
The practical application of Gemma 4 is best demonstrated through the construction of a "Second Brain"—a personal knowledge management system that uses Retrieval-Augmented Generation (RAG) to answer questions based on a user’s private files.
The workflow for such a project involves several distinct stages:
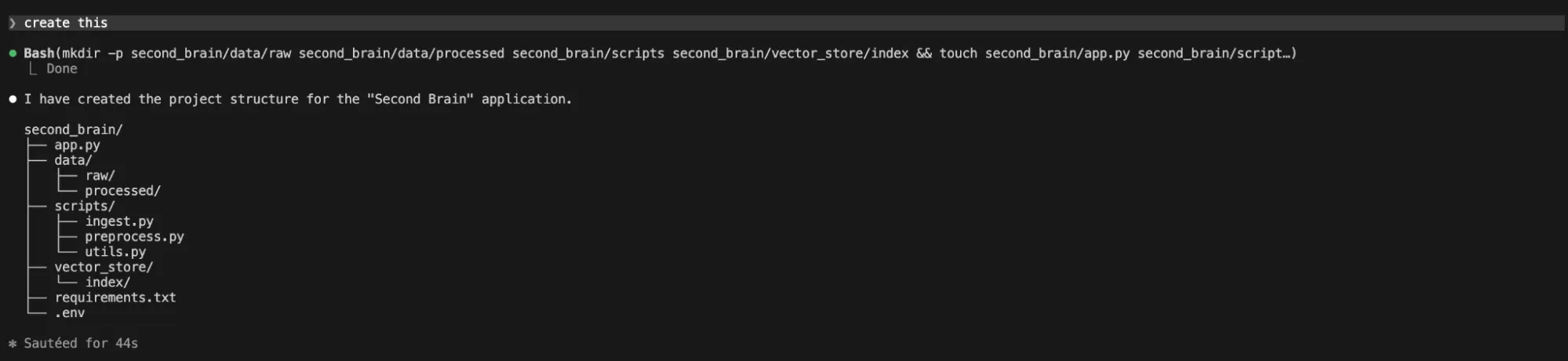
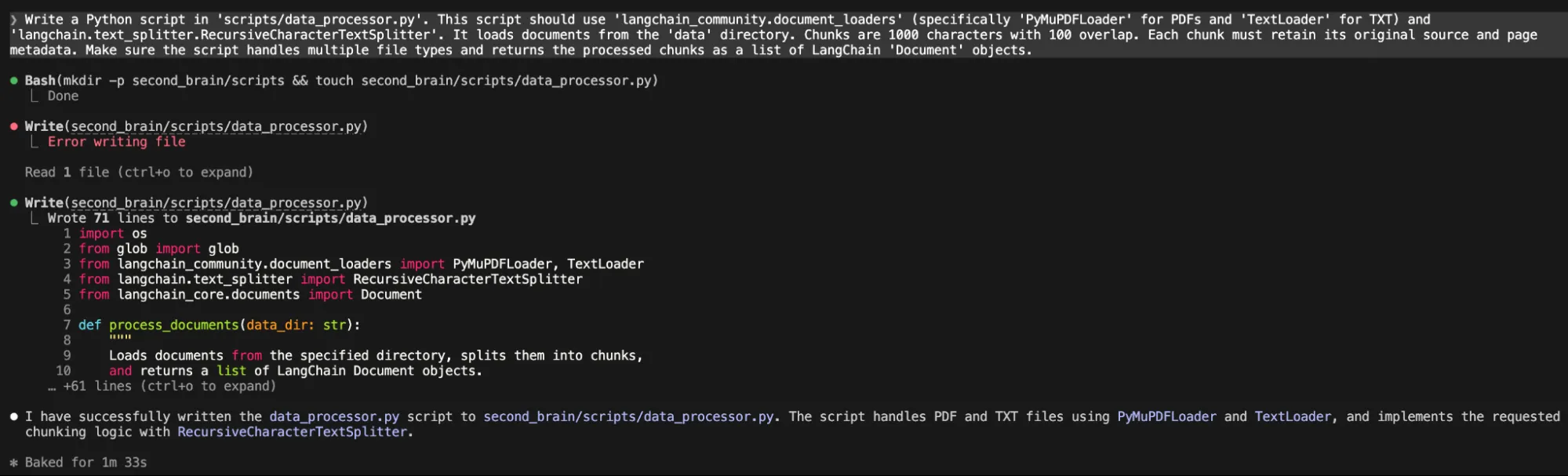
- Data Ingestion: Utilizing libraries like LangChain, the system loads local PDFs and text files.
- Document Chunking: The text is broken into manageable segments (e.g., 1,000 characters) to fit within the model’s processing limits while maintaining context.
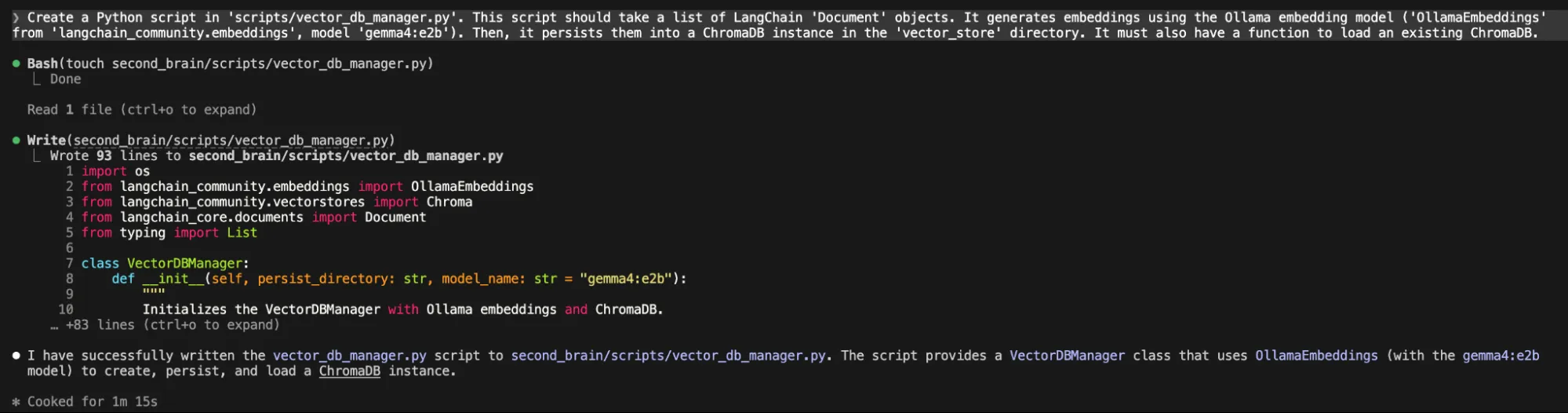
- Vector Embeddings: Gemma 4’s embedding capabilities are used to convert text chunks into mathematical vectors, which are then stored in a local vector database like ChromaDB.
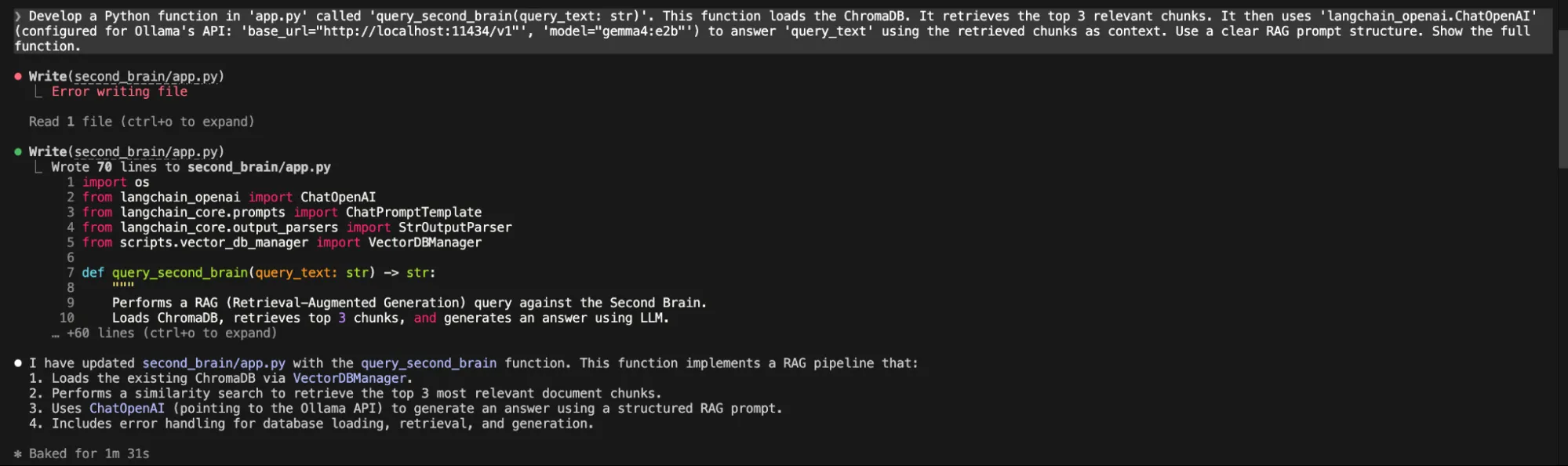
- Retrieval and Generation: When a user asks a question, the system retrieves the most relevant chunks from the database and feeds them to the Gemma 4 model to generate a precise, context-aware answer.
This RAG-based approach ensures that the AI’s responses are grounded in the user’s specific data, effectively eliminating the "hallucinations" common in general-purpose chatbots while maintaining total data privacy.
Performance Analysis: Local vs. Cloud Trade-offs
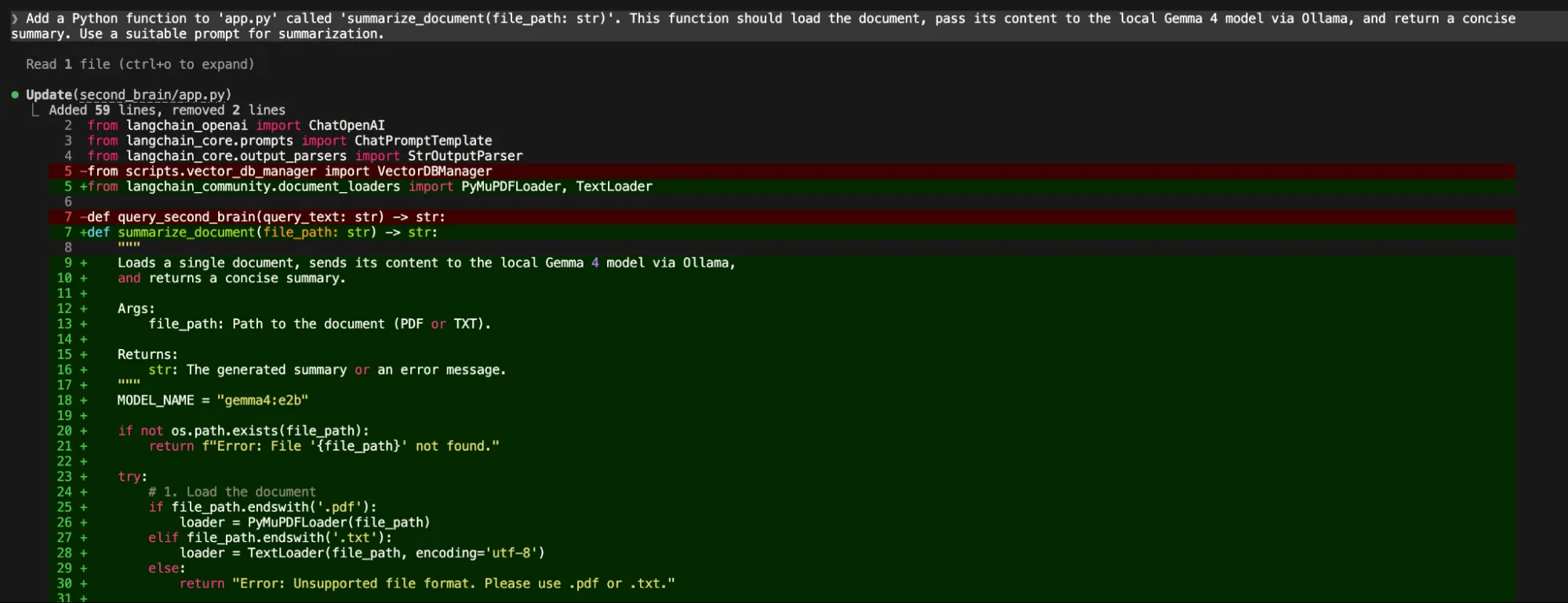
Despite the advancements in Gemma 4, recent hands-on testing highlights a persistent gap between local execution and cloud-based performance. In complex software engineering tasks, such as building the "Second Brain" architecture from scratch, local variants like the 26B-A4B occasionally struggle with multi-step logical reasoning and bug fixing.
During development trials, users reported that while the 26B model could generate initial project structures and scripts, it often hit a "reasoning ceiling" when asked to debug integration errors between different Python modules. In these instances, developers frequently found it necessary to pivot to the cloud-hosted version of the 31B model. The cloud variant, often running on more powerful H100 or A100 GPU clusters, demonstrates a higher "intelligence density," capable of analyzing entire project directories and self-correcting code in a single pass.
This suggests that while local AI is ready for document analysis, summarization, and basic assistance, high-tier agentic workflows—where the AI must act as an independent developer—still benefit significantly from the compute-heavy environments of the cloud.
Industry Implications and Future Outlook
The release of Gemma 4 has broader implications for the AI industry and the future of work. By lowering the barrier to entry for high-quality local AI, Google is putting pressure on other major players to maintain "open" versions of their flagship models.
Privacy and Security: For sectors like healthcare, law, and finance, Gemma 4 provides a viable path to AI adoption. The ability to summarize patient records or analyze legal contracts without data leaving the local machine solves one of the primary hurdles to AI integration in regulated industries.
The Cost of Intelligence: As the "token war" continues, where API providers compete on fractions of a cent per thousand tokens, the cost of running a local model like Gemma 4 is essentially reduced to the price of electricity. For startups and independent developers, this enables a level of experimentation that was previously cost-prohibitive.
The Future of Edge AI: The "E" variants of Gemma 4 indicate Google’s long-term interest in "Edge AI"—bringing intelligence directly to smartphones, IoT devices, and personal computers. As hardware manufacturers like Intel, AMD, and Apple continue to integrate dedicated AI accelerators (NPUs) into their chips, the performance gap between local and cloud models is expected to narrow.
Conclusion
Gemma 4 represents a sophisticated evolution in Google’s AI strategy, offering a versatile toolset for the modern developer. From the lightweight E2B model for mobile applications to the robust 31B model for deep reasoning, the family addresses a wide spectrum of computational needs. While local models still face challenges in matching the sheer logical depth of massive cloud-based clusters, the ability to build, iterate, and deploy intelligent systems privately is a transformative capability. As the ecosystem around Ollama, LangChain, and agentic tools like Claude Code continues to mature, Gemma 4 is poised to become a foundational component of the next generation of private, decentralized AI applications.