The global artificial intelligence landscape reached a significant milestone in April with the near-simultaneous release of two frontier large language models (LLMs): OpenAI’s GPT-5.5 and Anthropic’s Claude Opus 4.7. These launches represent a pivot in the industry, moving away from simple conversational interfaces toward autonomous "agentic" systems capable of complex reasoning, tool manipulation, and long-term planning. While both organizations claim the mantle of technical leadership, empirical benchmarks and comparative performance testing reveal distinct philosophies and specialized strengths that differentiate the two models for enterprise and individual workflows.
The Chronology of a Dual Launch
The release cycle began in early April when Anthropic announced the debut of Claude Opus 4.7. Positioned as the successor to the highly regarded Claude 3.5 series, Opus 4.7 was marketed specifically for high-stakes professional environments, including legal, financial, and advanced engineering sectors. Anthropic emphasized the model’s increased "reliability" and "vision-density," designed to handle multi-step workflows with minimal human oversight.
Shortly thereafter, OpenAI responded with the release of GPT-5.5. Rather than a minor iterative update, GPT-5.5 was presented as a fundamental shift in how AI processes intent. OpenAI’s launch focused on "intuitive execution," showcasing the model’s ability to anticipate user needs, utilize external software tools autonomously, and perform complex browser-based tasks. The overlap of these releases has forced developers and enterprises to conduct immediate, side-by-side evaluations to determine which architecture better serves specific operational requirements.
Technical Specifications and Model Philosophy
The design of GPT-5.5 reflects OpenAI’s push toward full-scale AI agents. The model is engineered to bridge the gap between "answering" and "doing." It features enhanced capabilities in planning and tool integration, allowing it to interact with terminal environments and web browsers to complete tasks that previously required human intervention. The primary goal of GPT-5.5 is to reduce "prompt sensitivity," meaning the model can extract the user’s true intent even from ambiguous or poorly structured instructions.
Conversely, Anthropic’s Claude Opus 4.7 leans into "frontier reasoning" and "software mastery." Anthropic has prioritized the model’s performance in coding environments and visual analysis of complex documentation. Opus 4.7 is designed for consistency across long-running tasks, featuring an improved memory architecture that allows it to maintain context over multi-session projects without the "hallucinations" or drift often associated with earlier LLM iterations.

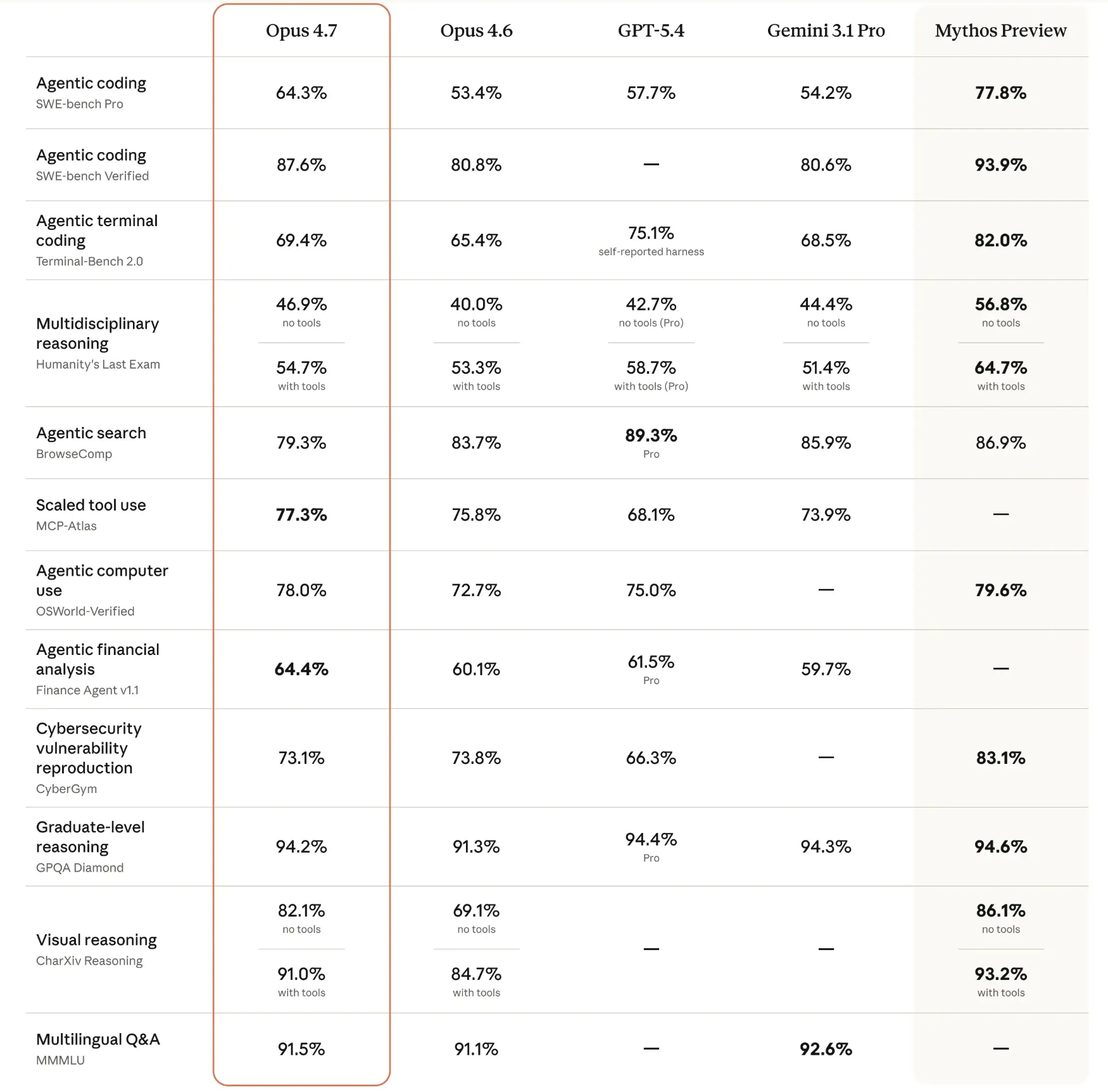
Comparative Benchmarking: A Data-Driven Overview
Benchmark results released by both companies provide a quantitative look at the models’ respective capabilities across various domains, from mathematics to software engineering.
GPT-5.5 Performance Metrics
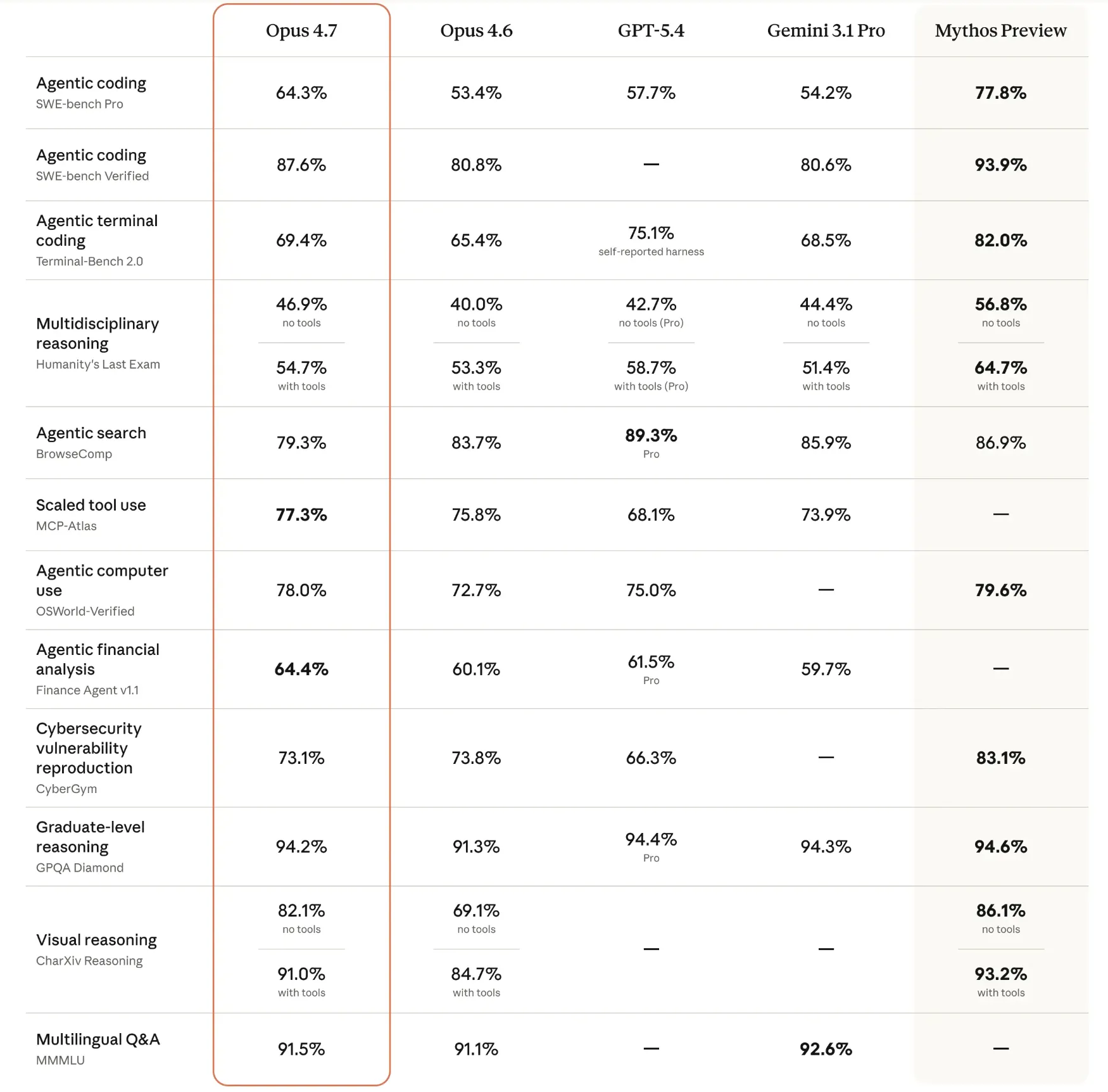
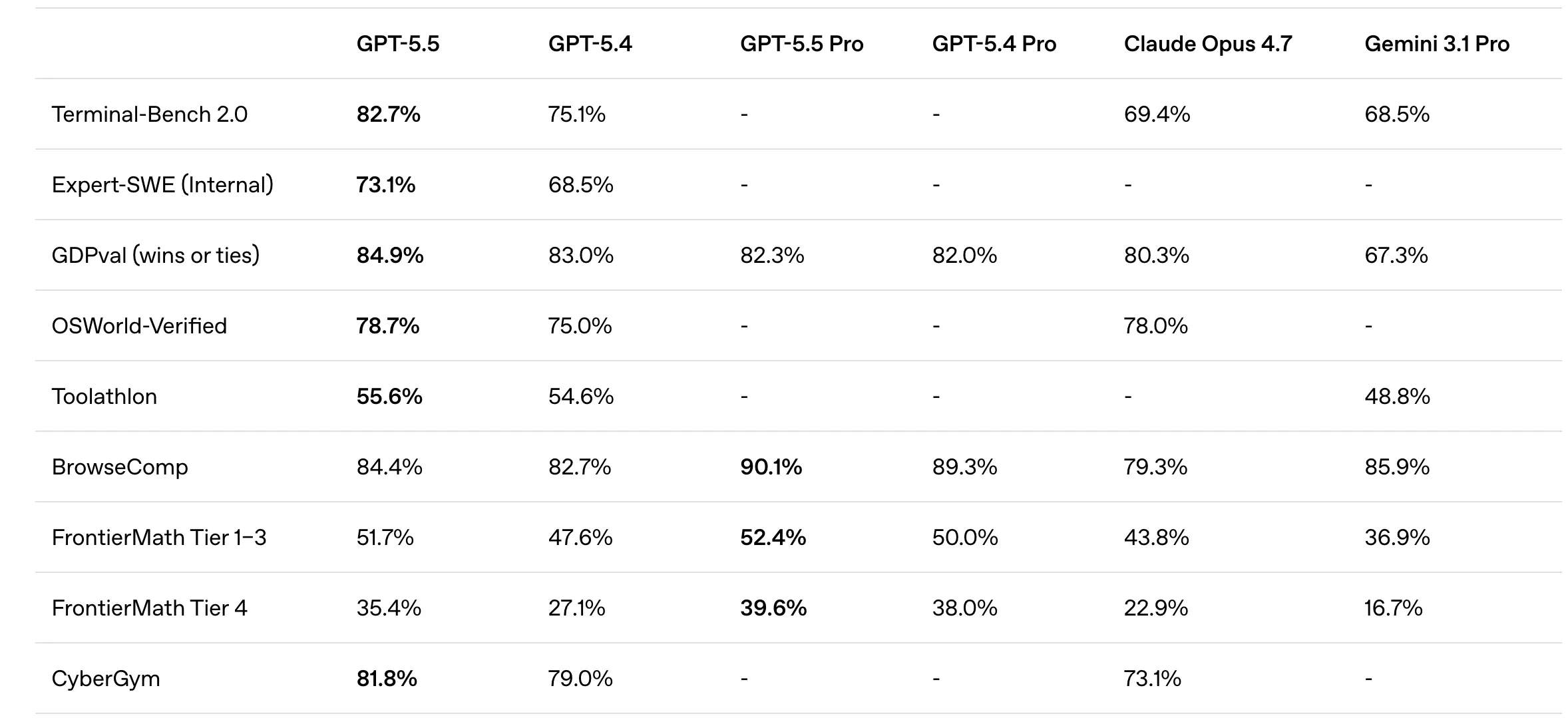
GPT-5.5 demonstrated exceptional proficiency in "agentic" benchmarks—tests that require the AI to navigate environments and use tools. It achieved a score of 82.7% on Terminal-Bench 2.0, a significant indicator of its ability to operate within command-line interfaces. In the realm of autonomous web navigation, it scored 78.7% on the OSWorld-Verified benchmark. Its reasoning capabilities were further validated by a 51.7% score on FrontierMath Tiers 1–3, which involves graduate-level mathematical problem-solving.
Claude Opus 4.7 Performance Metrics
Claude Opus 4.7 showed its greatest strengths in software development and knowledge-heavy reasoning. It secured an 87.6% on the SWE-bench Verified, a benchmark that tests a model’s ability to resolve real-world GitHub issues. In high-level academic reasoning, it achieved a 94.2% on the GPQA Diamond (Graduate-Level Google-Proof Q&A). Furthermore, its visual reasoning capabilities were highlighted by a 91.5% score on the MMMU (Massive Multi-discipline Multimodal Understanding) benchmark, suggesting a high degree of precision in interpreting charts, diagrams, and technical screenshots.
Comparative Performance in Applied Scenarios
Beyond theoretical benchmarks, comparative testing across seven core functional areas reveals how these models behave in real-world applications.
Strategic Planning and Reasoning
In scenarios involving business strategy—such as resource allocation for startups—GPT-5.5 tends to provide more exhaustive, structured breakdowns. Testing showed that GPT-5.5 often produces granular, month-by-month execution plans that include specific focus areas and task lists. While Claude Opus 4.7 offers similar strategic conclusions, its output is generally more concise, focusing on high-level trade-offs rather than the minute operational details favored by the OpenAI model.
Software Development and Coding
For technical workflows, Claude Opus 4.7 has emerged as the preferred tool for many developers. In head-to-head coding tasks, Opus 4.7 demonstrated a more sophisticated approach to error handling and terminal integration. For instance, when tasked with building data processing scripts, Opus 4.7 automatically included "parse arguments," allowing the code to be run directly via command line without modification. GPT-5.5, while producing functional code, often relied on more static configurations that required manual adjustment by the user.
Linguistic Nuance and Creative Output
The "personality" of the two models differs significantly in creative writing. Claude Opus 4.7 is noted for a more "human-centric" and "quirky" tone, often avoiding the formulaic structures common in AI-generated text. GPT-5.5, while highly efficient and clear, tends to follow a more standardized journalistic or academic structure. This makes Opus 4.7 the stronger candidate for content creation that requires a specific brand voice or narrative flair.
Data Analysis and Presentation
In the analysis of financial or operational data, GPT-5.5 maintains a slight lead in presentation and immediate insight. Evaluators noted that GPT-5.5 is more adept at identifying critical anomalies—such as a Customer Acquisition Cost (CAC) rising faster than revenue—and presenting these findings in highly readable tables and bulleted lists. Opus 4.7 provides accurate analysis but often requires the user to synthesize the insights from a more narrative-heavy output.
Visual Intelligence and Document Analysis
Both models have made strides in multimodal capabilities. In vision tests involving product dashboards or dense technical diagrams, both models accurately identified trends and suggested actionable next steps. However, GPT-5.5’s output was frequently cited as being more "consumable" for business teams, utilizing formatting that highlights the most critical data points first.
Industry Implications and Market Reaction
The simultaneous arrival of GPT-5.5 and Opus 4.7 has sparked a new wave of competition among enterprise software providers. Industry analysts suggest that the "Agentic Era" is now in full swing, as companies move from using AI for simple queries to integrating these models into automated workflows.
Early reactions from the developer community suggest a split: those focused on building autonomous agents and browser-based automation tools are gravitating toward GPT-5.5 due to its superior terminal and navigation scores. Meanwhile, research-heavy firms, legal departments, and software engineering teams are showing a preference for Claude Opus 4.7, citing its reasoning depth and more natural communication style.
There are also broader implications for the workforce. As these models become better at "execution" (e.g., managing a 30-day newsletter launch or resolving software bugs), the role of the human operator is shifting from "doer" to "orchestrator." The ability of these models to handle "unsupervised" tasks reduces the friction of adoption for small businesses that lack large technical teams.
Conclusion and Future Outlook
The battle between GPT-5.5 and Claude Opus 4.7 confirms that the AI industry has moved past the stage of general-purpose chatbots. We are now seeing the emergence of specialized "super-intelligences" tailored for different aspects of professional life.
GPT-5.5 stands as the current leader for users who prioritize directness, presentation, and complex task execution. Its ability to act as a proactive partner—offering ideas before being asked and structuring information for immediate use—makes it a powerful tool for general productivity and business management.
Claude Opus 4.7 remains the premier choice for tasks requiring deep technical accuracy, nuanced writing, and complex visual interpretation. Its strength lies in its role as a "reliable expert," providing high-quality output that feels less like a machine and more like a senior professional counterpart.
As both OpenAI and Anthropic continue to refine these models, the focus is expected to shift toward further reducing latency and decreasing the cost of "agentic" compute. For now, the choice between GPT-5.5 and Opus 4.7 depends largely on whether the user requires an autonomous executor or a sophisticated analytical partner.