The landscape of artificial intelligence underwent a seismic shift in April 2026 as the industry’s two primary titans, OpenAI and Anthropic, released their most sophisticated models to date in a near-simultaneous launch window. Anthropic initiated the sequence with the debut of Claude Opus 4.7, a model engineered for high-level reasoning and autonomous professional workflows. OpenAI responded shortly thereafter with GPT-5.5, an iteration positioned not merely as a conversational interface but as a highly intuitive agent capable of executing complex, multi-step tasks with minimal human intervention. This dual release marks a pivotal moment in the transition from generative AI to agentic AI, where the value of a model is measured more by its execution of intent than its ability to synthesize text.
The Chronology of the Spring AI Releases
The road to the April 2026 releases began in late 2025, when both companies signaled a move toward "system 2" thinking—models capable of slow, deliberate reasoning rather than instant pattern matching. On April 4, Anthropic announced Opus 4.7, emphasizing its utility in advanced software engineering and high-resolution visual processing. The market reaction was immediate, with enterprise sectors in law and finance praising the model’s consistency and memory retention over long-running projects.
OpenAI followed on April 12 with GPT-5.5. Unlike previous launches that focused on parameter count or linguistic flair, OpenAI centered its narrative on "agentic execution." This release included the "GPT-5.5 Pro" tier, specifically designed for browser-based autonomy and complex tool utilization. The overlapping release schedules forced a direct market comparison, as developers and enterprises sought to determine which architecture would serve as the backbone for the next generation of automated workflows.
Technical Specifications and Benchmark Performance
To evaluate the claims of both organizations, it is necessary to examine standardized benchmark performance, which provides an objective metric for reasoning, coding, and tool manipulation.
GPT-5.5: The Agentic Powerhouse
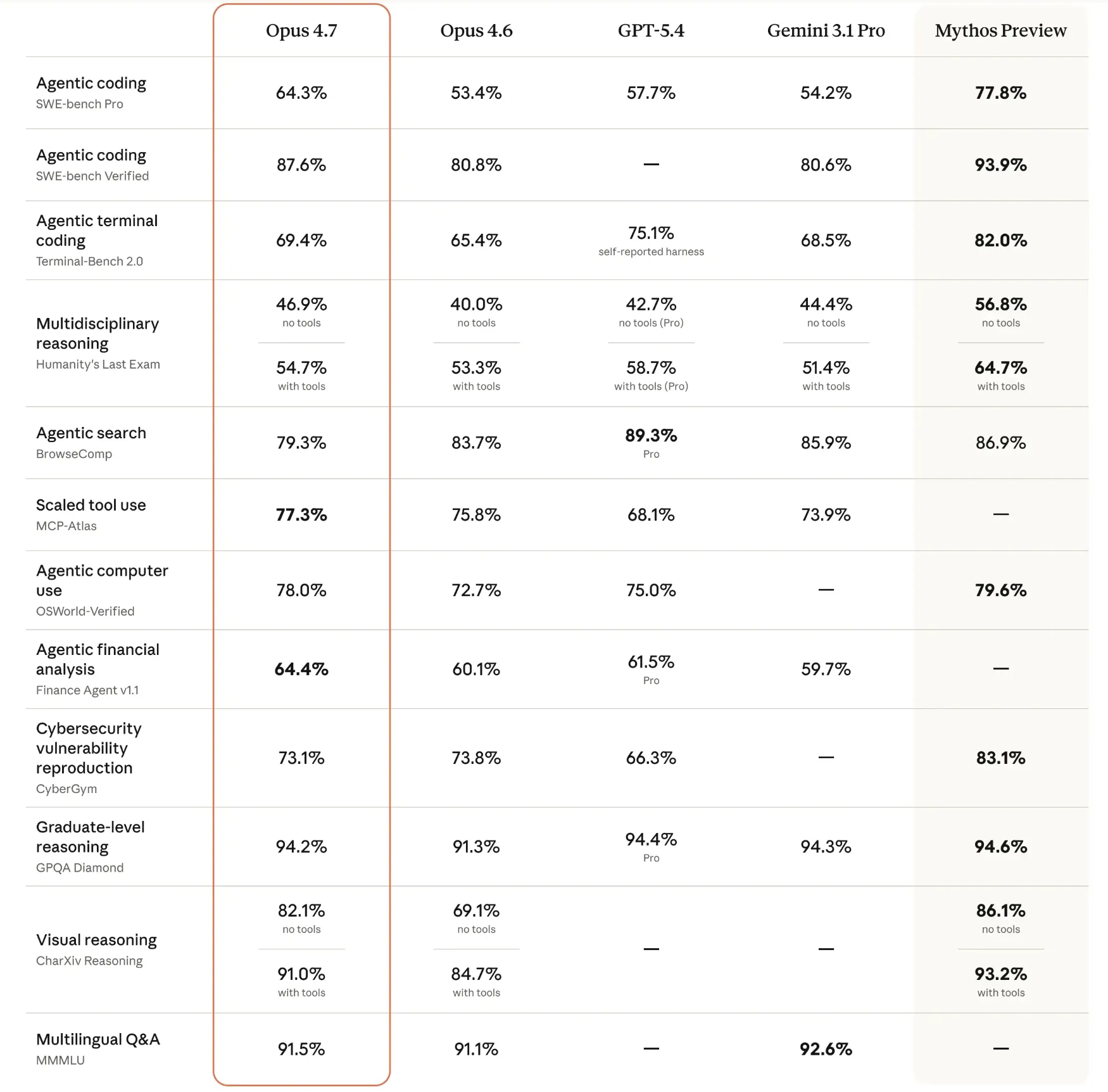
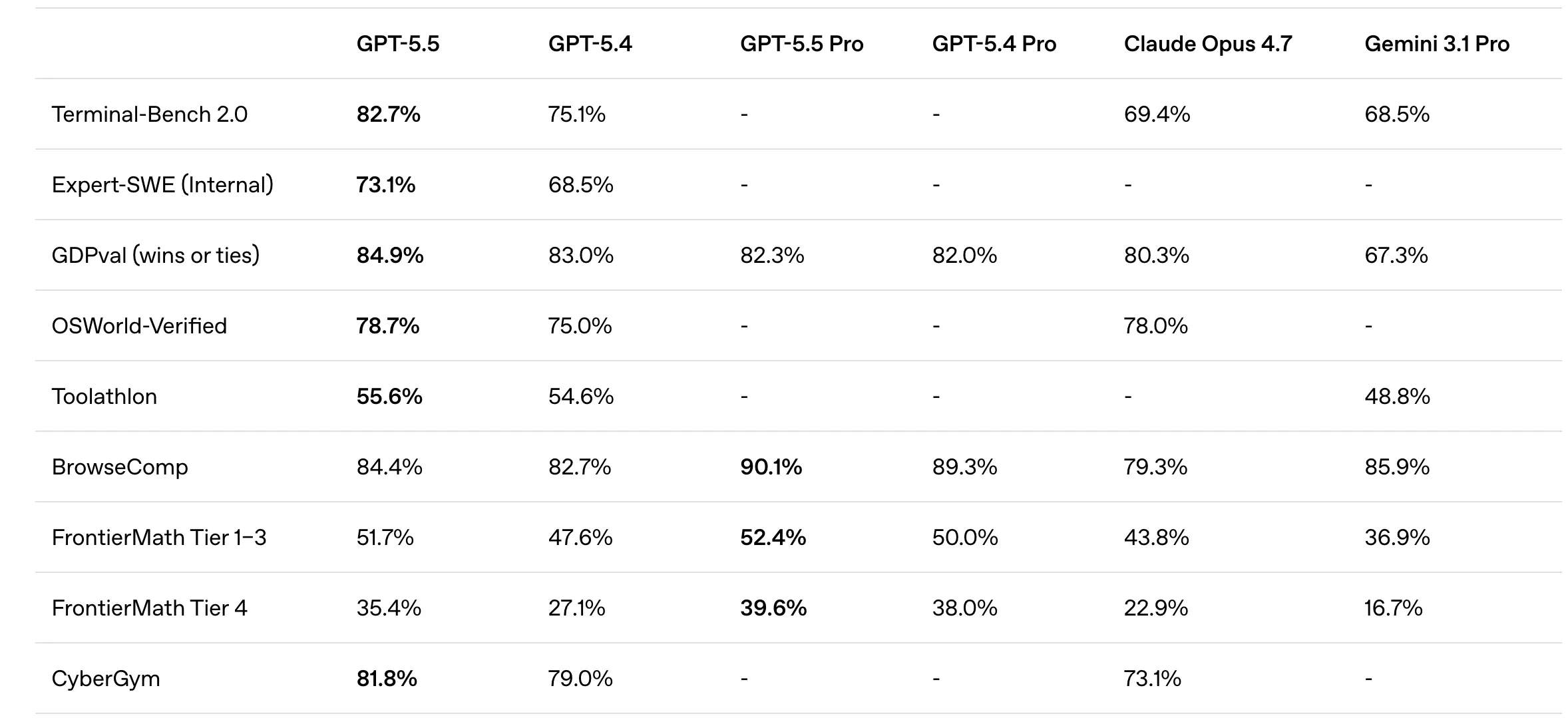
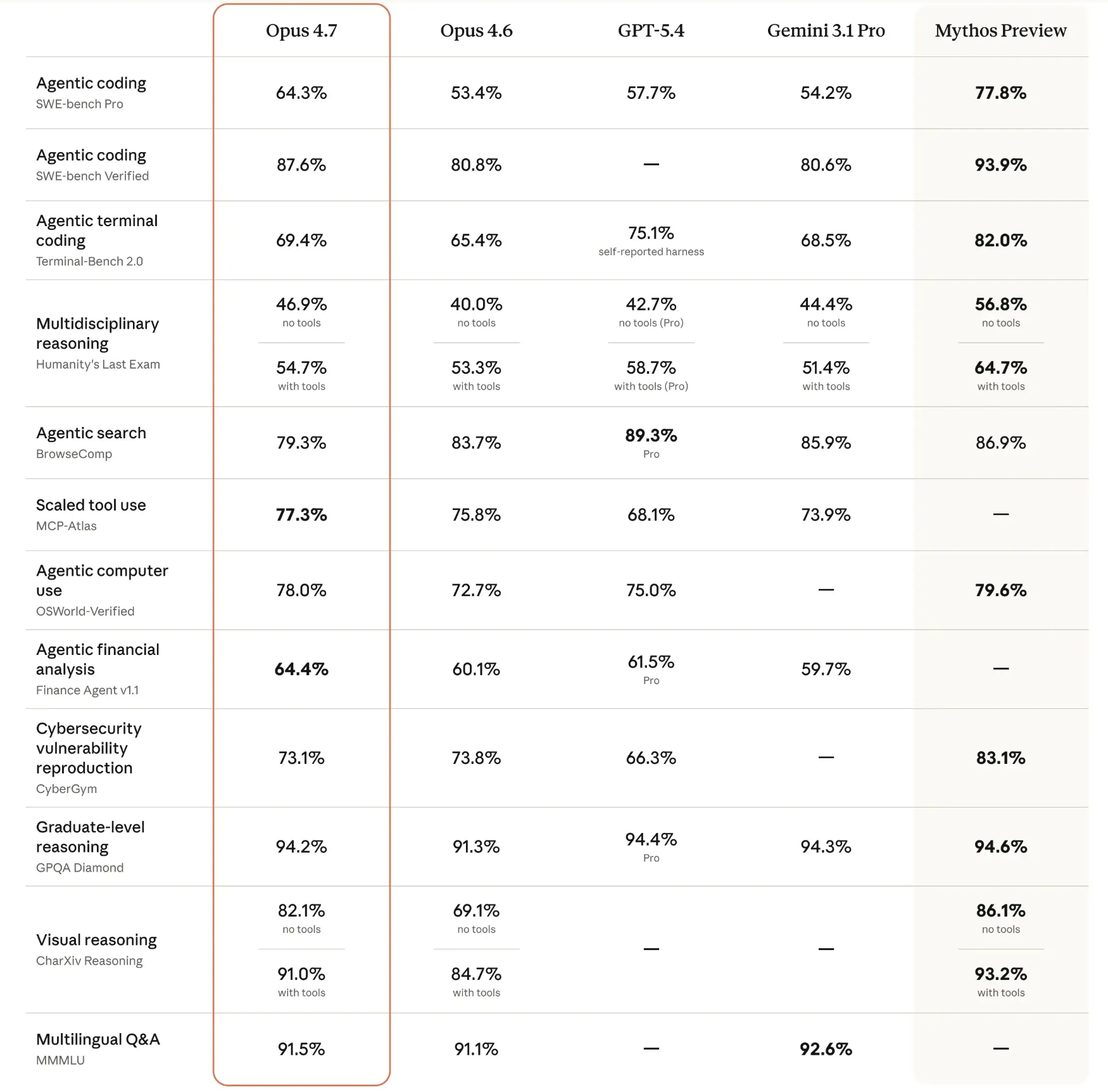
OpenAI’s GPT-5.5 demonstrated significant dominance in tasks requiring interaction with external environments. On Terminal-Bench 2.0, a metric testing a model’s ability to navigate command-line interfaces and execute system-level tasks, GPT-5.5 scored 82.7%. Its performance on Expert-SWE (73.1%) and OSWorld-Verified (78.7%) underscores its capability to manage operating systems and software environments autonomously.

Furthermore, GPT-5.5’s reasoning capabilities in mathematics were highlighted by its performance on FrontierMath. It achieved a 51.7% success rate on Tiers 1–3 and a notable 35.4% on the highly complex Tier 4, suggesting a level of mathematical intuition previously unseen in large language models. The model’s design philosophy appears to prioritize the "how" of a task—planning, tool selection, and execution—over the mere "what."
Claude Opus 4.7: The Professional Architect
Anthropic’s Opus 4.7, conversely, showed superior performance in deep reasoning and high-fidelity vision tasks. It achieved an 87.6% on SWE-bench Verified, a benchmark for resolving real-world GitHub issues, indicating a slight edge in practical software engineering over GPT-5.5. Its score on GPQA Diamond (94.2%), a test composed of graduate-level science questions, remains the industry gold standard for academic knowledge.
In terms of multimodal capabilities, Opus 4.7 reached 91.5% on MMMU (Massive Multi-discipline Multimodal Understanding) and 91.0% on CharXiv for visual reasoning. These figures suggest that Opus 4.7 is better suited for interpreting dense technical diagrams, financial charts, and legal documents where precision is paramount. Anthropic’s focus remains on reliability and the reduction of "hallucinations" in professional, knowledge-heavy environments.
Comparative Field Testing: Real-World Use Cases
While benchmarks provide a quantitative baseline, qualitative field testing reveals how these models behave under the pressure of ambiguous human requests.
Strategic Reasoning and Planning
In tests involving business strategy—such as building a six-month priority plan for a startup with limited runway—both models exhibited high-level competence. However, GPT-5.5 demonstrated a superior ability to break down high-level goals into granular, actionable tasks. Its output provided a month-by-month distribution of focus areas, including specific pros and cons for different revenue streams. While Opus 4.7 provided a sound strategic framework, it lacked the exhaustive detail and "project manager" perspective that GPT-5.5 offered.
Creative and Human-Centric Writing
The creative writing sector continues to see a divergence in model "personality." When tasked with writing a sharp, non-generic introduction to an article on AI agents, Claude Opus 4.7 consistently outperformed GPT-5.5. Reviewers noted that Opus 4.7’s prose felt more "human," utilizing varied sentence structures and a tone that avoided the predictable, hyperbolic tropes often associated with OpenAI’s outputs. For professional writers and marketing teams, Opus 4.7’s ability to mimic nuanced human styles remains a significant competitive advantage.
Software Engineering and Error Handling
In coding simulations—specifically the creation of Python scripts for data classification—Opus 4.7 showed a more sophisticated understanding of edge cases. Its code included comprehensive "parse arguments" for terminal use and robust error-handling protocols, such as ValueError exceptions for incorrect data types. GPT-5.5 produced functional, "clean" code, but it was less prepared for the unpredictability of real-world deployment, often relying on static file paths that would require manual user intervention.
Visual Data Analysis
The vision test, involving the analysis of a product dashboard, highlighted GPT-5.5’s superior presentation skills. While both models correctly identified trends in customer acquisition costs (CAC) and churn rates, GPT-5.5 presented its findings in a highly digestible format using tables and direct, bolded action items. This "at-a-glance" utility makes it more effective for executive briefings where speed of comprehension is vital.
Industry Implications and Market Reaction
The launch of these models has triggered a wave of reactions from the technology and business sectors. Market analysts suggest that the competition is no longer about which model is "smarter" in a general sense, but which model integrates more seamlessly into existing tech stacks.
"We are seeing a bifurcation of the market," stated one lead AI researcher at a Silicon Valley firm. "OpenAI is building the ‘Universal Executor’—a model that can go into your browser, use your tools, and act as a digital employee. Anthropic is building the ‘Universal Consultant’—a model you go to for deep, reliable, and nuanced expertise in complex fields like code or law."
Enterprises have responded by diversifying their AI reliance. Large-scale software houses are reportedly leaning toward Opus 4.7 for its superior coding benchmarks and error handling. Meanwhile, logistics and productivity-focused firms are gravitating toward GPT-5.5 for its agentic capabilities and its ability to handle "messy" real-world workflows with less supervision.
The Agentic Shift: A New Paradigm
The most significant takeaway from the April 2026 releases is the formal arrival of "agentic" AI. Previous models were reactive; they waited for a prompt and provided a response. GPT-5.5 and Opus 4.7 represent a shift toward proactivity.
In agentic tasks, such as launching a niche newsletter from scratch, these models no longer just suggest ideas. They outline toolsets, create content calendars, suggest monetization paths, and—in the case of GPT-5.5—provide specific, viable niche ideas to begin with. This reduces the "cold start" problem for entrepreneurs and employees, effectively moving the AI from the role of a calculator to that of a collaborator.
Conclusion and Future Outlook
The battle between GPT-5.5 and Claude Opus 4.7 has no clear victor, as the "best" model depends entirely on the requirements of the user. GPT-5.5 is currently the industry leader in directness, presentability, and agentic execution. It is the preferred choice for users who need a model to "just do it"—whether that involves analyzing a spreadsheet or planning a project.
Claude Opus 4.7 remains the premier choice for tasks requiring deep technical rigor, creative flair, and complex software development. Its ability to handle high-resolution visual data and its more human-like writing style make it indispensable for research-heavy and creative workflows.
As these models continue to evolve, the focus will likely shift toward "inference-time compute"—allowing the models more time to "think" before they speak. For now, the April 2026 releases have set a new high-water mark for the industry, proving that the era of AI as a mere chatbot is over, and the era of the AI agent has officially begun. The competition between OpenAI and Anthropic remains the primary engine of innovation in the field, ensuring that the boundaries of what is possible with machine intelligence will continue to expand at an unprecedented pace.