The landscape of large language models (LLMs) has witnessed a significant shift with the release of Anthropic’s Claude Opus 4.7, the latest iteration in the company’s flagship series. Positioned as a bridge toward the capabilities of the highly anticipated "Mythos" architecture, Opus 4.7 was designed to refine the foundations laid by its predecessor, Opus 4.6. While Anthropic promised a leap in agentic workflows, memory retention, and complex real-world task handling, the rollout has been met with a mixture of technical acclaim and vocal user frustration. This report examines the technical evolution from Opus 4.6 to 4.7, analyzing official claims against real-world performance benchmarks and user feedback.
The Evolution of the Opus Lineage: From 4.6 to 4.7
The transition from Opus 4.6 to 4.7 represents Anthropic’s effort to move beyond simple chat-based interactions toward more autonomous "agentic" capabilities. Opus 4.6 gained fame for its nuanced writing style and high emotional intelligence, often being cited by developers as a more "human-like" alternative to OpenAI’s GPT-4 series. However, as the industry pivots toward AI agents—models that can plan, use tools, and execute multi-step workflows—Anthropic recognized the need for a model with more rigorous internal verification.
Opus 4.7 was introduced as a refined version of this vision. According to Anthropic’s internal documentation, the primary focus of the 4.7 update was "reliability in high-stakes environments." This includes advanced software engineering, enhanced visual processing, and a more robust file-system-based memory. Despite these promises, the launch has triggered a debate within the AI community regarding the "cost of intelligence," as the technical changes under the hood have altered the economic and functional experience for end-users.
Technical Specifications and Official Claims
Anthropic’s official release highlights four key areas where Opus 4.7 is intended to outperform the 4.6 model:

1. Advanced Software Engineering and Supervision
Anthropic asserts that Opus 4.7 is engineered for long-running, complex software projects. In internal benchmarks, the company reported that Opus 4.7 requires significantly less human supervision than Opus 4.6 when managing dense coding workloads. This is attributed to the model’s ability to "self-verify"—a process where the model checks its own logic before delivering a response. This architectural shift is designed to prevent the common "hallucinations" that often plague complex coding tasks in earlier iterations.
2. High-Resolution Vision Capabilities
One of the most measurable leaps in Opus 4.7 is its visual processing power. The model now supports image processing at resolutions up to 2,576 pixels on the long edge, totaling approximately 3.75 megapixels. This is a three-fold increase over the megapixel count supported by Opus 4.6. This upgrade is specifically targeted at professional use cases such as analyzing dense financial charts, reading architectural blueprints, and extracting data from high-resolution screenshots of software interfaces.
3. Economic and Professional Knowledge Work
In third-party evaluations and Anthropic’s internal testing, Opus 4.7 demonstrated superior performance in domains tied to high economic value, such as finance and legal analysis. The model is reportedly capable of producing more rigorous financial models and tighter integration across multi-part tasks. The goal was to transform the AI from a creative assistant into a reliable professional analyst.
4. Memory and File-System Integration
Opus 4.7 introduces an improved method for utilizing file-system-based memory. Unlike the transient memory of previous models, which often lost context during extended sessions, Opus 4.7 is designed to retain notes and context across multi-session workflows. This reduces the need for "context stuffing," where users must re-upload or re-explain background information at the start of every new prompt.
The Tokenizer Controversy: A Hidden Cost
The most significant technical change in Opus 4.7, and the source of much user ire, is the updated tokenizer. A tokenizer is the component of an AI model that breaks down text into numerical units that the model can process. Anthropic confirmed that the new tokenizer in Opus 4.7 maps input text to a higher number of tokens than the 4.6 version. Depending on the content, users are seeing a 1.0x to 1.35x increase in token consumption for the exact same input.
Furthermore, Opus 4.7 is designed to engage in "higher effort" thinking, particularly in agentic settings. While this increases reliability, it results in a massive surge in output tokens. For users on the $20/month Pro plan, this has led to a dramatic reduction in session limits. Reports have surfaced on social media platforms like Reddit and X (formerly Twitter) of users hitting their usage caps after as few as three prompts. In some cases, the model’s internal "Chain of Thought" reasoning consumes so much of the context window that the user is locked out of the conversation almost immediately.
Real-World Comparison: Hands-On Benchmarking
To verify the claims and complaints, a series of comparative tests were conducted between Opus 4.6 and Opus 4.7 across three domains: content extraction, reasoning, and coding.
Test 1: Content Extraction and Data Analysis
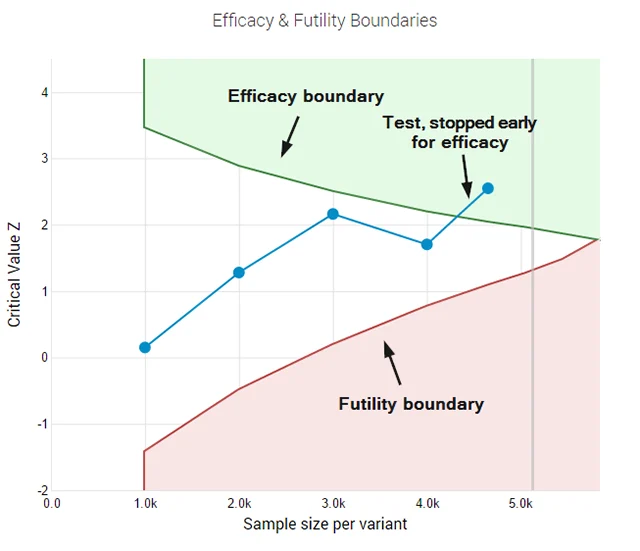
When tasked with analyzing an IMF report on India’s financial stability, both models provided accurate data. However, the execution styles differed wildly. Opus 4.7 engaged in a seven-step "thinking" process, meticulously planning its response. While the resulting data was accurate, the output was delivered in a dense, text-heavy format that lacked visual appeal.
In contrast, Opus 4.6 arrived at the conclusion in only three steps and automatically generated a dashboard to present the findings. For the average user, Opus 4.6 provided a more "useful" and presentable result with significantly lower token expenditure. This suggests that while Opus 4.7 is more "thorough," its thoroughness may not always translate into better user utility.
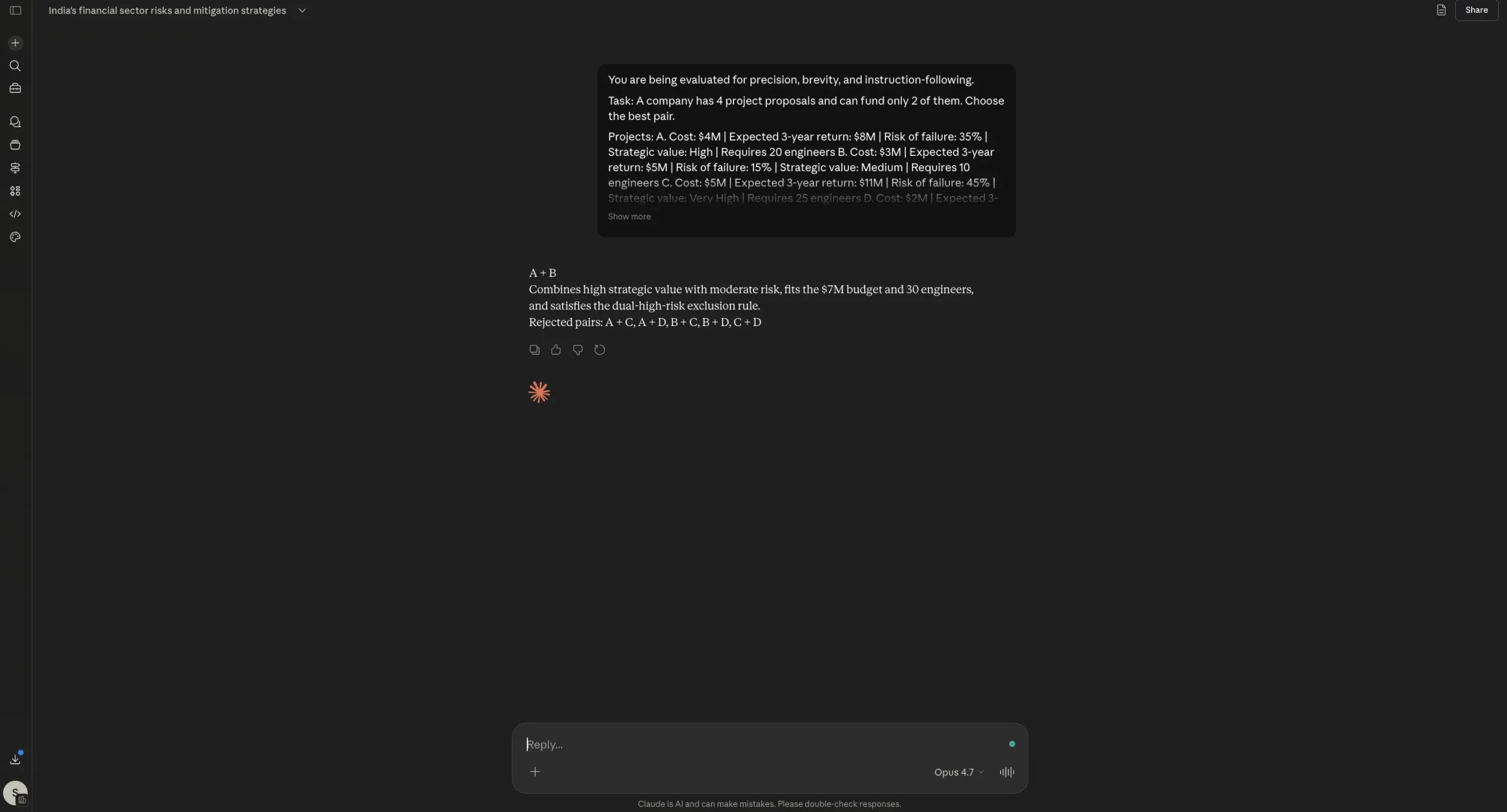
Test 2: Logical Reasoning and Constraint Following
A complex project management prompt was used to test the models’ ability to follow strict output rules while solving a mathematical constraint problem. The prompt required the models to choose a pair of project proposals based on budget, staffing, and risk constraints, with strict formatting rules (e.g., "no calculations shown," "maximum 25 words").
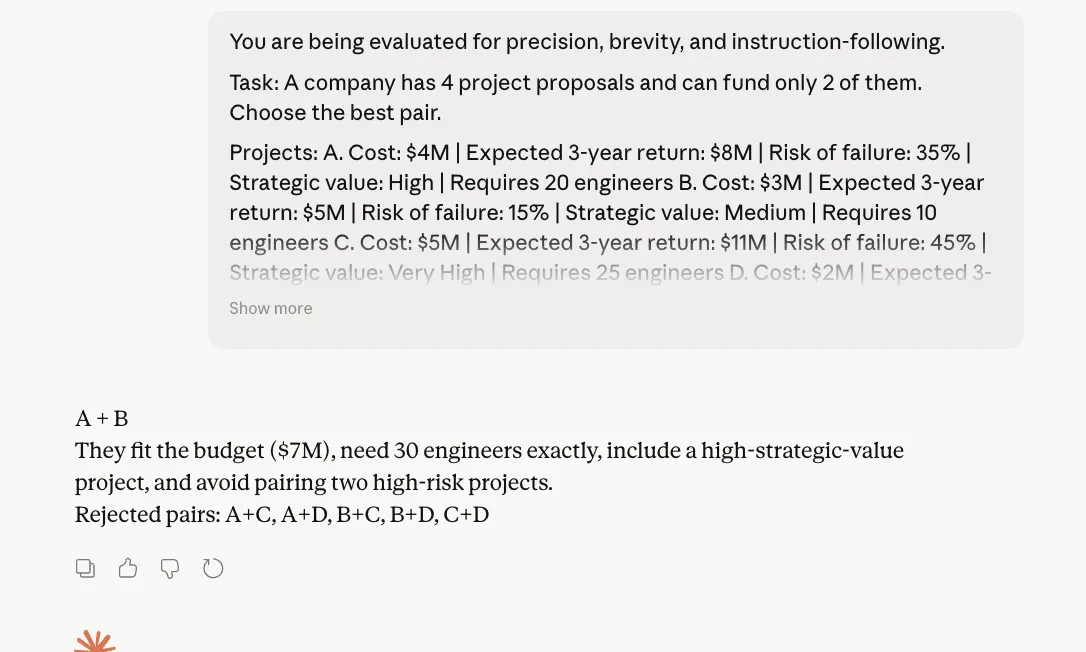
Both models passed this test perfectly. They arrived at the same correct pair and adhered to all negative constraints. Interestingly, Opus 4.7 did not exhibit the "token wastage" reported by some users in this specific scenario, staying compact and disciplined. This indicates that Opus 4.7’s tendency to over-explain may be triggered more by open-ended tasks than by highly constrained logical prompts.
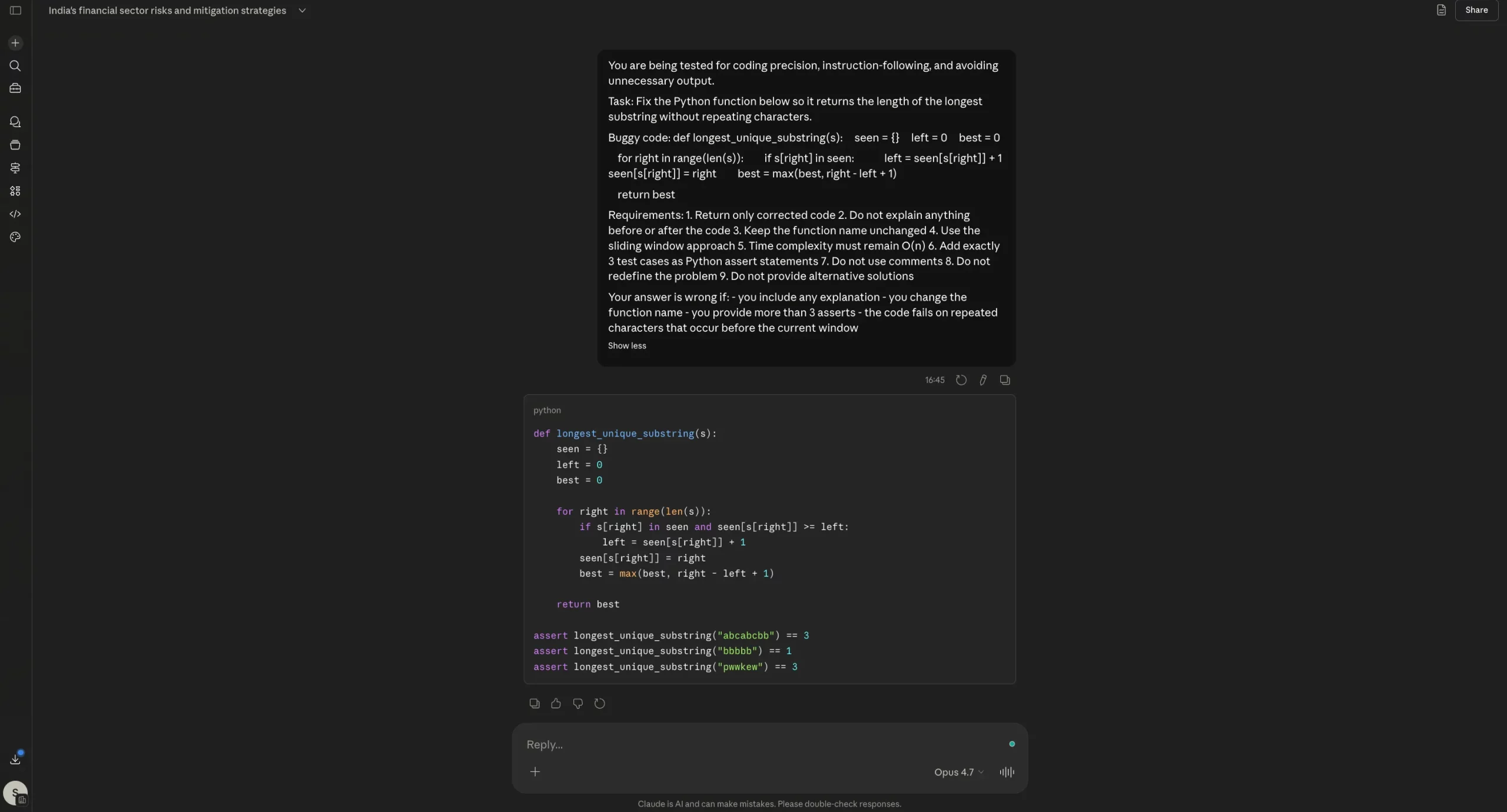
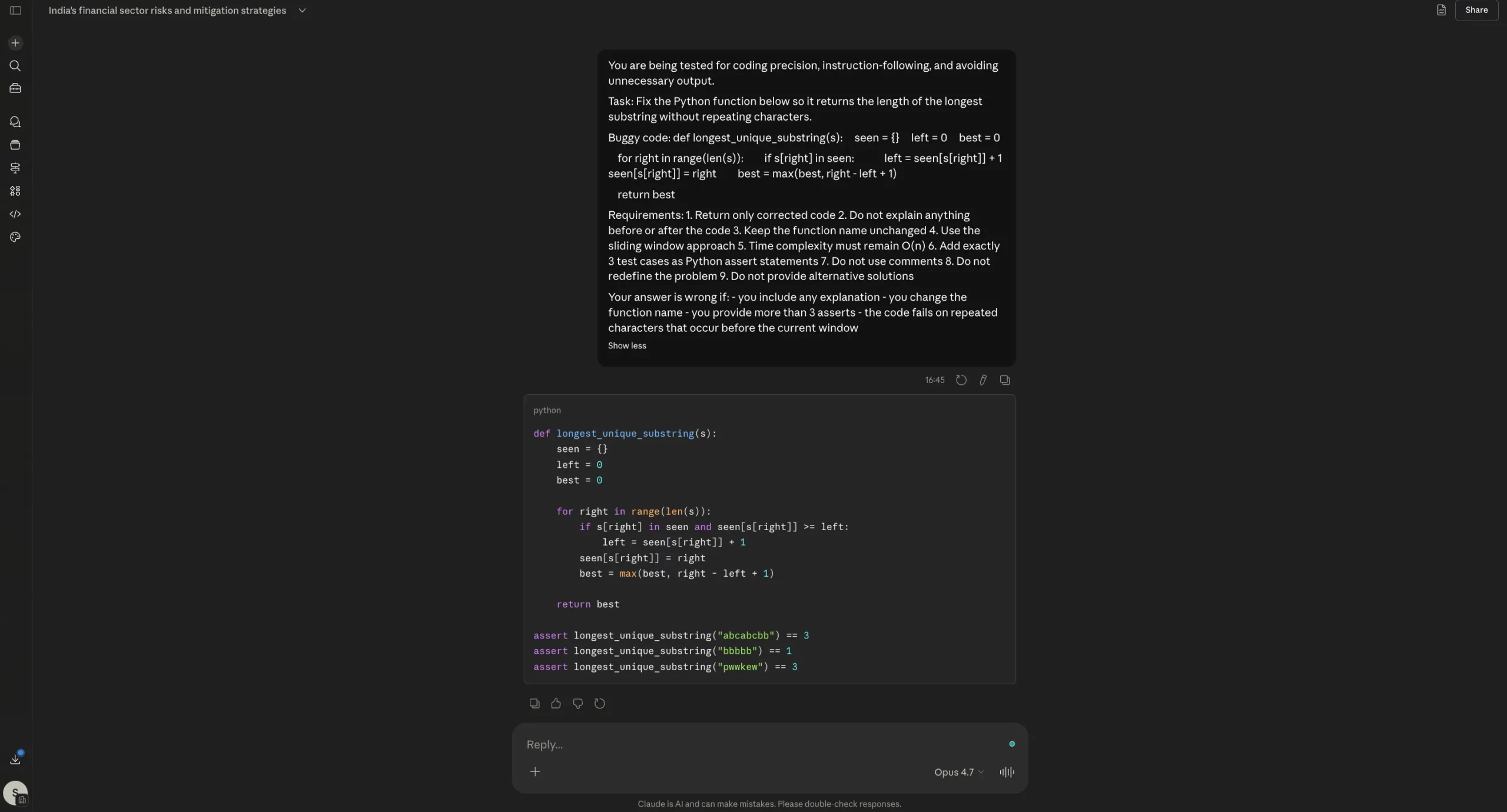
Test 3: Python Coding and Bug Fixing
The models were asked to fix a "sliding window" algorithm in Python with specific requirements: no comments, no explanations, and the inclusion of exactly three assert statements. Both Opus 4.6 and 4.7 successfully fixed the bug and followed all formatting instructions.
While Opus 4.7 was marketed as a major upgrade for software engineering, this test showed it to be on par with, rather than significantly ahead of, Opus 4.6 for isolated coding tasks. The "agentic" benefits promised by Anthropic likely manifest in larger, multi-file repositories rather than single-function debugging.
User Sentiment and Market Reaction
The reception of Opus 4.7 has been polarized. A segment of the developer community has praised the model’s increased "honesty" and its ability to verify its own work, noting that it is less likely to confidently provide wrong answers than Opus 4.6.
However, a larger portion of the general user base has expressed disappointment. Common complaints include:
- "Sonnet in Disguise": Some users claim that Opus 4.7 feels more like Claude 3.5 Sonnet—Anthropic’s mid-tier, faster model—than a true "Opus" class upgrade.
- Instruction Overlooking: Reports suggest that the model occasionally ignores direct commands, such as citation requirements or specific formatting needs, in favor of its own internal "reasoning" style.
- The "Apology" Loop: Users have noted that when the model hits a token limit or fails a task, it often enters a cycle of lengthy apologies that further consume the remaining token budget.
Implications for the AI Industry
The launch of Opus 4.7 highlights a growing tension in AI development: the trade-off between "Deep Thinking" and "User Efficiency." As models like Opus 4.7 and OpenAI’s "o1" series move toward internal reasoning (Chain of Thought), the cost of a single query is rising.
For enterprises, Opus 4.7 represents a step toward more reliable autonomous agents that can be trusted with financial or legal data. The increased vision resolution and self-verification are high-value features for corporate environments where accuracy is more important than token cost.
For individual creators and casual users, however, the update may feel like a regression. The increased token consumption and the removal of the "intuitive" presentation style seen in Opus 4.6 make the new model harder to use for quick, daily tasks.
Conclusion
Anthropic’s Claude Opus 4.7 is a technically superior model in terms of raw resolution, memory architecture, and internal verification. It successfully moves the needle toward the "Mythos" era of agentic AI. However, this technical superiority comes at a high price—both in literal token costs and in the loss of the streamlined efficiency that made Opus 4.6 a favorite.
The data suggests that while Opus 4.7 is a powerful tool for complex, high-stakes engineering and analysis, it has not yet rendered Opus 4.6 obsolete. Users seeking presentation-ready outputs and cost-effective interactions may find themselves sticking with the older model, while those pushing the boundaries of AI agents will find the 4.7’s rigorous "thinking" process to be a necessary, if expensive, evolution. As Anthropic continues to iterate, the challenge will be to maintain this high level of intelligence without alienating the user base through prohibitive resource demands.